

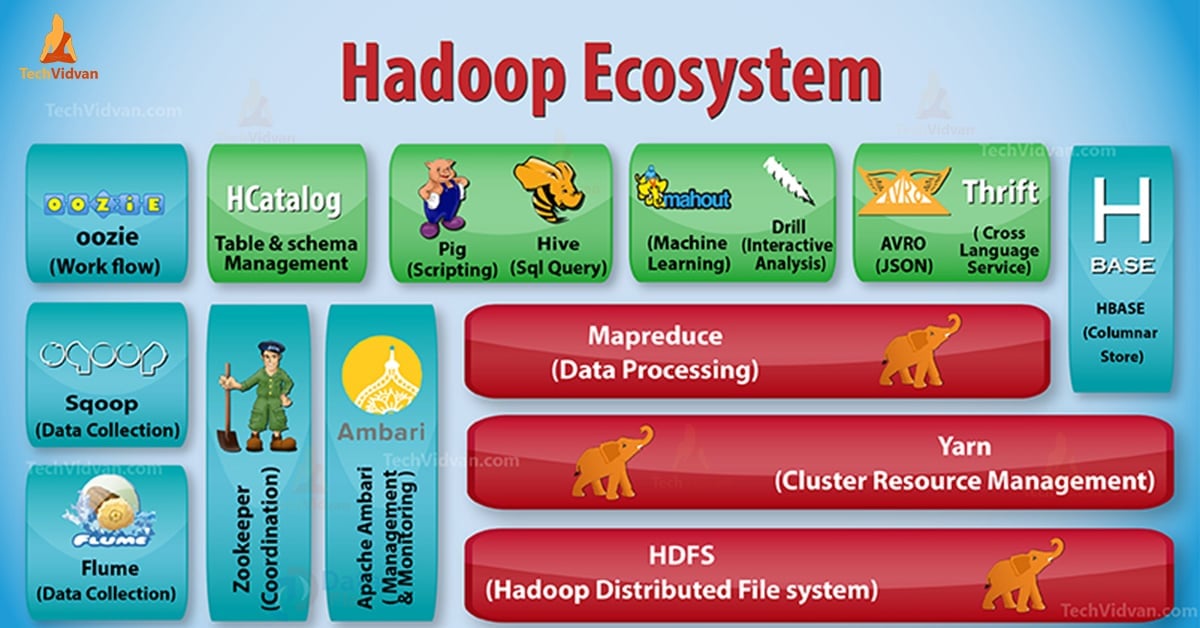
In our previous blog, we have discussed Hadoop Introduction in detail. Now in this blog, we are going to answer what is Hadoop Ecosystem and what are the roles of Hadoop Components.
In this Hadoop Components tutorial, we will discuss different ecosystem components of the Hadoop family such as HDFS, MapReduce, YARN, Hive, HBase, Pig, Zookeeper etc.
All these Components of Hadoop Ecosystem are discussed along with their features and responsibilities.
Hadoop Ecosystem Tutorial
Apache Hadoop is the most powerful tool of Big Data. Hadoop ecosystem revolves around three main components HDFS, MapReduce, and YARN. Apart from these Hadoop Components, there are some other Hadoop ecosystem components also, that play an important role to boost Hadoop functionalities.
let’s now understand the different Hadoop Components in detail.
a. HDFS
Hadoop Distributed File System (HDFS) is the primary storage system of Hadoop. HDFS store very large files running on a cluster of commodity hardware.
It follows the principle of storing less number of large files rather than the huge number of small files. HDFS stores data reliably even in the case of hardware failure. Hence, it provides high throughput access to the application by accessing in parallel.
Components of HDFS:
- NameNode – It works as Master in Hadoop cluster. Namenode stores meta-data i.e. number of blocks, replicas and other details. Meta-data is present in memory in the master. NameNode assigns tasks to the slave node. It should deploy on reliable hardware as it is the centerpiece of HDFS.
- DataNode – It works as Slave in Hadoop cluster. In Hadoop HDFS, DataNode is responsible for storing actual data in HDFS. DataNode also performs read and write operation as per request for the clients. DataNodes can also deploy on commodity hardware.
b. MapReduce
Hadoop MapReduce is the data processing layer of Hadoop. It processes large structured and unstructured data stored in HDFS. MapReduce also processes a huge amount of data in parallel.
It does this by dividing the job (submitted job) into a set of independent tasks (sub-job). In Hadoop, MapReduce works by breaking the processing into phases: Map and Reduce.
- Map – It is the first phase of processing, where we specify all the complex logic code.
- Reduce – It is the second phase of processing. Here we specify light-weight processing like aggregation/summation.
c. YARN
Hadoop YARN provides the resource management. It is the operating system of Hadoop. So, it is responsible for managing and monitoring workloads, implementing security controls. It is a central platform to deliver data governance tools across Hadoop clusters.
YARN allows multiple data processing engines such as real-time streaming, batch processing etc.
Components of YARN:
- Resource Manager – It is a cluster level component and runs on the Master machine. Hence it manages resources and schedule applications running on the top of YARN. It has two components: Scheduler & Application Manager.
- Node Manager – It is a node level component. It runs on each slave machine. It continuously communicate with Resource Manager to remain up-to-date
d. Hive
Apache Hive is an open source data warehouse system used for querying and analyzing large datasets stored in Hadoop files. It process structured and semi-structured data in Hadoop.
Hive also support analysis of large datasets stored in HDFS and also in Amazon S3 filesystem is supported by Hive. Hive uses the language called HiveQL (HQL), which is similar to SQL. HiveQL automatically translates SQL-like queries into MapReduce jobs.
e. Pig
It is a high-level language platform developed to execute queries on huge datasets that are stored in Hadoop HDFS. PigLatin is a language used in pig which is very similar to SQL.
Pig loads the data, apply the required filters and dump the data in the required format. Pig also converts all the operation into Map and Reduce tasks which are effectively processed on Hadoop.
Characteristics of Pig:
- Extensible – Pig users can create custom functions to meet their particular processing requirements.
- Self-optimizing – Since Pig allows the system to optimize automatically. So, the user can focus on semantics.
- Handles all kinds of data – Pig analyzes both structured as well as unstructured.
f. HBase
Apache HBase is NoSQL database that runs on the top of Hadoop. It is a database that stores structured data in tables that could have billions of rows and millions of columns. HBase also provides real-time access to read or write data in HDFS.
Components of HBase:
- HBase Master – It is not part of the actual data storage. But it performs administration (interface for creating, updating and deleting tables.).
- Region Server – It is the worker node. It handles read, writes, updates and delete requests from clients. Region server also process runs on every node in Hadoop cluster.
g. HCatalog
It is table and storage management layer on the top of Apache Hadoop. HCatalog is a main component of Hive. Hence, it enables the user to store their data in any format and structure. It also supports different Hadoop components to easily read and write data from the cluster.
Advantages of HCatalog:
- Provide visibility for data cleaning and archiving tools.
- With the table abstraction, HCatalog frees the user from the overhead of data storage.
- Enables notifications of data availability.
i. Avro
It is an open source project that provides data serialization and data exchange services for Hadoop. Using serialization, service programs can serialize data into files or messages.
It also stores data definition and data together in one message or file. Hence, this makes it easy for programs to dynamically understand information stored in Avro file or message.
Avro provides:
- Container file, to store persistent data.
- Remote procedure call.
- Rich data structures.
- Compact, fast, binary data format.
j. Thrift
Apache Thrift is a software framework that allows scalable cross-language services development. Thrift is also used for RPC communication. Apache Hadoop does a lot of RPC calls, so there is a possibility of using Thrift for performance.
k. Drill
The drill is used for large-scale data processing. Designing of the drill is to scale to several thousands of nodes and query petabytes of data. It is also a low latency distributed query engine for large-scale datasets.
The drill is also the first distributed SQL query engine that has a schema-free model.
Characteristics of drill:
- Drill decentralized metadata – Drill does not have centralized metadata requirement. Drill users do not need to create and manage tables in metadata in order to query data.
- Flexibility – Drill provides Hierarchical columnar data model. It can represent complex, highly dynamic data and also allow efficient processing.
- Dynamic schema discovery – To start the query execution process Drill does not require any type specification for data. Instead, drill starts processing the data in units called record batches. It also discovers schema on the fly during processing.
l. Mahout
It is an open source framework used for creating scalable machine learning algorithm. Once we store data in HDFS, mahout provides the data science tools to automatically find meaningful patterns in those Big Data sets.
m. Sqoop
It is mainly used for importing and exporting data. So, it imports data from external sources into related Hadoop components like HDFS, HBase or Hive. It also exports data from Hadoop to other external sources. Sqoop works with relational databases such as Teradata, Netezza, Oracle, MySQL.
n. Flume
Flume efficiently collects, aggregate and move a large amount of data from its origin and sending it back to HDFS. It has a very simple and flexible architecture based on streaming data flows. Flume is fault tolerant, also a reliable mechanism.
Flume also allows flow data from the source into Hadoop environment. It uses a simple extensible data model that allows for the online analytic application. Hence, using Flume we can get the data from multiple servers immediately into Hadoop.
o. Ambari
It is an open source management platform. It is a platform for provisioning, managing, monitoring and securing Apache Hadoop cluster. Hadoop management gets simpler because Ambari provides consistent, secure platform for operational control.
Benefits of Ambari:
- Simplified installation, configuration, and management – It can easily and efficiently create and manage clusters at scale.
- Centralized security setup – Ambari configures cluster security across the entire platform. It also reduces the complexity to administer.
- Highly extensible and customizable – Ambari is highly extensible for bringing custom services under management.
- Full visibility into cluster health – Ambari ensures that the cluster is healthy and available with a holistic approach to monitoring.
p. Zookeeper
Zookeeper in Hadoop is a centralized service. It maintains configuration information, naming, and provide distributed synchronization. It also provides group services. Zookeeper also manages and coordinates a large cluster of machines.
Benefits of Zookeeper:
- Fast – zookeeper is fast with workloads where reads to data are more common than writes. The ideal read/write ratio is 10:1.
- Ordered – zookeeper maintains a record of all transactions, which can also be used for high-level
q. Oozie
It is a workflow scheduler system to manage Apache Hadoop jobs. It combines multiple jobs sequentially into one logical unit of work.
Hence, Oozie framework is fully integrated with Apache Hadoop stack, YARN as an architecture center. It also supports Hadoop jobs for Apache MapReduce, Pig, Hive, and Sqoop.
Oozie is scalable and also very much flexible. One can easily start, stop, suspend and rerun jobs. Hence, Oozie makes it very easy to rerun failed workflows. It is also possible to skip a specific failed node.
There are two basic types of Oozie jobs:
- Oozie workflow – It is to store and run workflows composed of Hadoop jobs e.g., MapReduce, Pig, Hive.
- Oozie coordinator – It runs workflow jobs based on predefined schedules and availability of data.
Conclusion
Hence, Hadoop Ecosystem provides different components that make it so popular. Due to these Hadoop components, several Hadoop job roles are available now.
I hope this Hadoop Ecosystem tutorial helps you a lot to understand the Hadoop family and their roles. If you find any query, so please share with us in the comment box.