
MapReduce is one of the core components of Hadoop that processes large datasets in parallel by dividing the task into a set of independent tasks. In this MapReduce Tutorial, you will study the working of Hadoop MapReduce in detail.
It covers all the phases of MapReduce job execution like Input Files, InputFormat, InputSplits, RecordReader, Mapper, Combiner, Partitioner, Shuffling, and Sorting, Reducer, RecordWriter, and OutputFormat in detail.
Let us first see what Hadoop MapReduce is.
Introduction to MapReduce
Hadoop MapReduce is the software framework for writing applications that processes huge amounts of data in-parallel on the large clusters of in-expensive hardware in a fault-tolerant and reliable manner.
A MapReduce job splits the input data into the independent chunks. These independent chunks are processed by the map tasks in a parallel manner. The framework then sorts the outputs of the maps tasks.
These outputs of the map tasks are then provided as an input to the reduce tasks. The input and the output of the MapReduce job are stored in the file-system. The Hadoop framework takes care of the tasks scheduling, monitoring, and re-execution of the failed tasks.
The Hadoop Distributed File System and the MapReduce framework runs on the same set of nodes, that is, the storage nodes and the compute nodes are the same.
This configuration allows the Hadoop framework to effectively schedule the tasks on the nodes where data is present. This results in very high aggregate bandwidth across the Hadoop cluster.
The Hadoop MapReduce framework consists of:
- single master ResourceManager
- One worker NodeManager per cluster-node
- MRAppMaster per application
The applications specify the input and the output locations and supply the map and reduce functions through the implementations of appropriate interfaces or abstract classes.
These and the other job parameters comprise job configuration.
Then, the Hadoop job client submits the job, that is, jar or executable, and configuration to the ResourceManager.
ResourceManager then assumes the responsibility of distributing the contribution of software to the workers, scheduling tasks and monitoring them, and providing status and diagnostic information to the job-client.
Though the Hadoop framework is implemented in Java, it is not needed to write MapReduce applications in Java.
Let us now see how it works internally in detail.
How Hadoop MapReduce works?
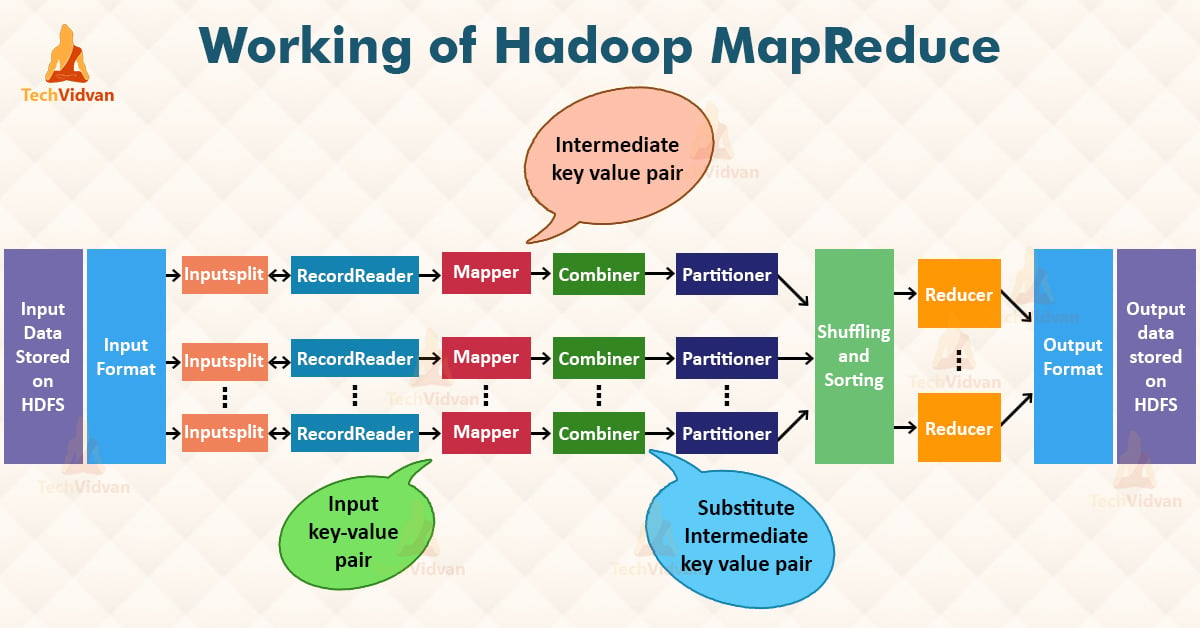
The whole process goes through various MapReduce phases of execution, namely, splitting, mapping, sorting and shuffling, and reducing. Let us explore each phase in detail.
1. InputFiles
The data that is to be processed by the MapReduce task is stored in input files. These input files are stored in the Hadoop Distributed File System. The file format is arbitrary, while the line-based log files and the binary format can also be used.
2. InputFormat
It specifies the input-specification for the job. InputFormat validates the MapReduce job input-specification and splits-up the input files into logical InputSplit instances. Each InputSplit is then assigned to the individual Mapper. TextInputFormat is the default InputFormat.
3. InputSplit
It represents the data for processing by the individual Mapper. InputSplit typically presents the byte-oriented view of the input. It is the RecordReader responsibility to process and present the record-oriented view. The default InputSplit is the FileSplit.
4. RecordReader
RecordReader reads the <key, value> pairs from the InputSplit. It converts a byte-oriented view of the input and presents a record-oriented view to the Mapper implementations for processing.
It is responsible for processing record boundaries and presenting the Map tasks with keys and values. The record reader breaks the data into the <key, value> pairs for input to the Mapper.
5. Mapper
Mapper maps the input <key, value> pairs to a set of intermediate <key, value> pairs. It processes the input records from the RecordReader and generates the new <key, value> pairs. The <key, value> pairs generated by Mapper are different from the input <key, value> pairs.
The generated <key, value> pairs is the output of Mapper known as intermediate output. These intermediate outputs of the Mappers are written to the local disk.
The Mappers output is not stored on the Hadoop Distributed File System because this is the temporary data, and writing this data on HDFS will create unnecessary copies. The output of the Mappers is then passed to the Combiner for further processing.
6. Combiner
It is also known as the ‘Mini-reducer’. Combiner performs local aggregation on the output of the Mappers. This helps in minimizing data transfer between the Mapper and the Reducer.
After the execution of the Combiner function, the output is passed to the Partitioner for further processing.
7. Partitioner
When we are working on the MapReduce program with more than one Reducer then only the Partitioner comes into the picture. For only one reducer, we do not use Partitioner.
It partitions the keyspace. It controls the partitioning of keys of the Mapper intermediate outputs.
Partitioner takes the output from the Combiner and performs partitioning. Key is for deriving the partition typically through the hash function. The number of partitions is similar to the number of reduce tasks. HashPartitioner is the default Partitioner.
8. Shuffling and Sorting
The input to the Reducer is always the sorted intermediate output of the mappers. After combining and partitioning, the framework via HTTP fetches all the relevant partitions of the output of all the mappers.
Once the output of all the mappers is shuffled, the framework groups the Reducer inputs on the basis of the keys. This is then provided as an input to the Reducer.
9. Reducer
Reducer then reduces the set of intermediate values who shares a key to the smaller set of values. The output of reducer is the final output. This output is stored in the Hadoop Distributed File System.
10. RecordWriter
RecordWriter writes the output (key, value pairs) of Reducer to an output file. It writes the MapReduce job outputs to the FileSystem.
11. OutputFormat
The OutputFormat specifies the way in which these output key-value pairs are written to the output files. It validates the output specification for a MapReduce job.
OutputFormat basically provides the RecordWriter implementation used for writing the output files of the MapReduce job. The output files are stored in a FileSystem.
Hence, in this manner, MapReduce works over the Hadoop cluster in different phases.
Summary
I hope after reading this article, you are now familiar with the internal working of Hadoop MapReduce.
The MapReduce Tutorial clearly explains all the phases of the Hadoop MapReduce framework such as Input Files, InputFormat, InputSplits, RecordReader, Mapper, Combiner, Partitioner, Shuffling, and Sorting, Reducer, RecordWriter, and OutputFormat.
All these play a vital role in the Hadoop MapReduce working.