Machine Learning Tutorial for Beginners with Case Study
This is a basic Machine Learning tutorial. Therefore, the explanation will be in a way that it is simpler to understand.
Machine Learning or ML is one of the most popular fields in today’s technology market. Having knowledge about ML can be really good because of its huge demand.
In this Machine Learning tutorial, we will be looking at what exactly Machine Learning is. We will also be studying about its needs, it’s working. The various types and approaches to Machine Learning will mark the end of the article.
Introduction to Machine Learning Tutorial
Machine Learning or ML is a field that makes predictions using algorithms. It helps to make the machines learn from the data given to them.
Machine Learning uses various statistical approaches for making predictions. It also has a major role in pattern finding in data, that is, it can find various patterns in complex data given to it.
Machine Learning is a part of its larger domain, which is Artificial Intelligence (AI). It deals with algorithms that learn from given data and make predictions.
Why Do We Need Machine Learning?
Machine Learning has made the analysis of large amounts of data very efficient. Normal algorithms are not capable of doing complex tasks, which is why ML is in use.
The iterative aspect of machine learning is vital because as models are exposed to new data, they’re ready to independently adapt. They learn from previous computations to supply reliable, repeatable decisions and results. It is a science that’s not new – but one that has gained fresh momentum.
ML has made work a lot more easier in many areas today. It is widely used in fields like banking, healthcare, science and many more.
Machine Learning is a very important part in today’s technology. Without it, many tasks will not be possible to achieve. Tasks like pattern recognition, prediction of future data would not be possible without ML. Even your internet searches use Machine Learning methods.
For every Google search you do, the algorithm learns from the previous searches. Based on your search history, it provides you the most desired results in your next search.
How Does Machine Learning Work?
Machine Learning has a basic working pattern. The algorithm takes both the input and output of the program. Then it trains a model using the given data. The algorithm looks for various patterns in the given data.
These patterns help in future predictions. The results obtained from training the model will help in improving the model’s working.
For a better understanding, take the example of Google searches. If you search for something on Google, you get a result. Here the search is the input data and the result is the output data. If you make more than one search, you will get many results.
Google has a search algorithm. This algorithm takes the searches and search results as input and output data.
The algorithm trains the model using this data. After this, if you search for the same thing again you might get even better results. Again, this new result helps to train the model for future searches. This is how Machine Learning works.
Machine Learning Approaches
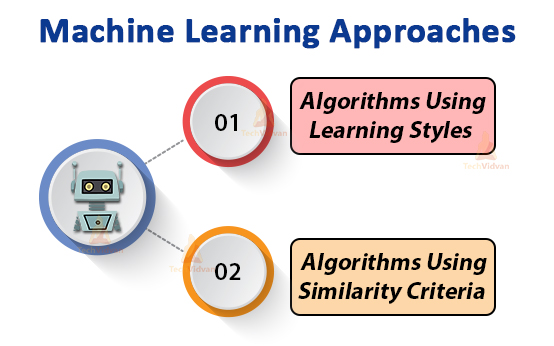
There are various approaches when it comes to implementing Machine Learning algorithms.
Machine Learning has been under research for several decades now. Hence, there are many approaches and algorithms in use and under research.
The approaches in ML are now classified into two categories. These are:
a. Grouping of the algorithms by their learning style.
b. Grouping of the algorithms by their similarity.
Now we will study the algorithms that come under these two categories.
1. Algorithms Using Learning Styles
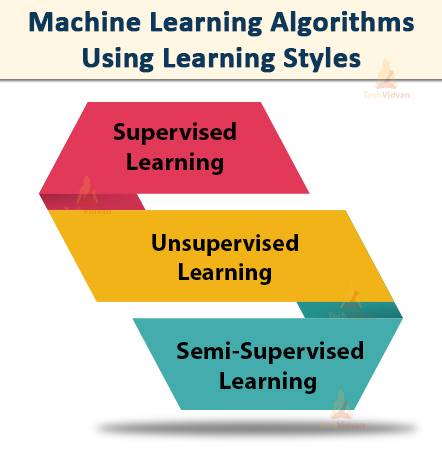
This method shows us how the ML algorithm works when given certain input data to learn from. This also helps in the selection of the correct model based on the result obtained.
a. Supervised Learning
Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples
In this type of learning, we have labeled input data. This means that the data presented to the model already contains the correct answer. Some might wonder why we are providing data that already has the right answer. The answer is simple.
We are giving this pre-labeled data to make the model learn from it. This means if data with similar features is given to the machine in the future, it will recognize it. In addition, the labeled data (training data) helps to train the model to improve its accuracy.
For a better understanding, let’s take an example.
We have a bag of vegetables consisting of tomatoes, onions, potatoes, radishes, etc.
Now you have to train your data like:
- If the shape is round and the color is red, then the vegetable should be a tomato.
- If the shape is an elongated cylinder and color is white then the vegetable should be a radish.
Since the machine has now learned about the vegetables, it should be able to distinguish them based on their attributes. That is if the shape is round and the color is red then the algorithm will put it in the tomatoes category.
Supervised learning is of two types:
1. Classification
It specifies the category to which data elements belong to and is best used when the output has finite and discrete values. It predicts a category for an input variable also.
The output in this problem is a category. Such as ‘blue’, ‘green’, ‘sunny’, ‘no sunny’, ‘disease’, ‘no disease’ etc.
The output here is in the form of classes.
2. Regression
It is a way which helps find the correlation between variables and enables us to predict the continual output variable supported the one or more predictor variables. The output in this problem is a real value like ‘mass’, ‘percent’, ‘rupees’, ‘dollars’ etc.
b. Unsupervised Learning:
Unsupervised learning is a type of machine learning algorithm used to draw inferences from datasets consisting of input data without labeled responses.
The most common unsupervised learning method is cluster analysis, which is used for exploratory data analysis to find hidden patterns or grouping in data. In this type of learning, there is no labeled input data. This means that the machine won’t be given any training data to learn from.
Thus, the task of the machine is to group similar types of data together. This is done based on patterns and differences without any sort of previous training. Thus, the machine will have to figure everything from scratch without any help.
Let’s take an example for a better understanding.
There is a picture of sardines and salmon fishes. Obviously, the machine has no knowledge about this. But, the algorithm can help us to find some patterns in the picture. Sardines and salmon are two varieties of fish. The sardines are small in size. Hence, they form one group. Whereas the salmon is bigger in size. Therefore, they also form a separate group.
In this way, the algorithm classifies objects using unsupervised learning. There are two types in this:
1. Clustering:
It which involves segregating data supported the similarity between data instances. It is an iterative process to seek out cluster centers called centroids and assigning data points to at least one of the centroids.
Here, we have groups of data according to certain criteria.
For example, people who drink coffee are grouped separately. Whereas, people who don’t drink come in a different group.
2. Association:
Association rules allow you to determine associations amongst data objects inside large databases. This helps to find more diverse rules in the data.
Association rule provides us with deeper information about groups.
For example, people who drink coffee may also like to drink tea.
c. Semi-Supervised Learning:
Semi-supervised learning follows both supervised and unsupervised learning methods. It removes some disadvantages that occur in both supervised and unsupervised leanings.
The disadvantage of supervised learning is that we have to manually label the data. This requires a lot of time and can be really expensive. Also, it requires ML engineers or special data scientists to do such jobs.
The disadvantage of unsupervised learning is that the results obtained are less accurate. This is because the data is not labeled and also unknown.
Semi-supervised learning eliminates these problems. Here the algorithm trains using both labeled and unlabeled data. The labeled data is a small part as compared to the unlabeled data.
The programmer uses unsupervised learning to first group the unlabeled data. Then the supervised learning labels all the remaining unlabeled data.
2. Algorithms Using Similarity Criteria
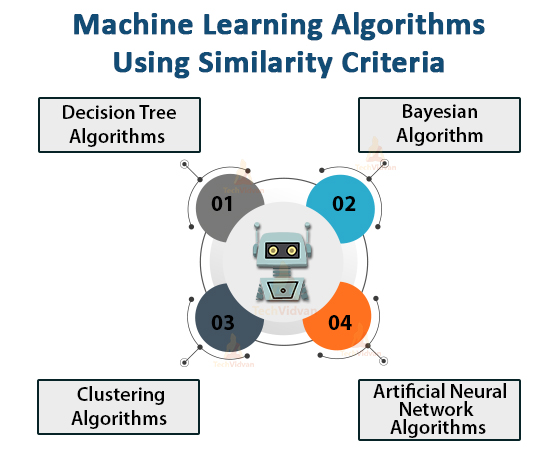
There are some algorithms which work on the basis of similarities in their functions. Especially neural networks.
Few algorithms are discussed below:
a. Decision Tree Algorithms:
In trees, the data splits according to specific parameters. It consists of nodes and leaves. Here, leaves are the final result whereas the nodes represent the point where the data is split.
Splitting here means, if there are two options of yes and no, at a time only one result is there. We have two types of trees namely classification trees and regression trees.
A classification tree is of a yes/no type. Whereas, in the regression tree, the data is continuous.
There are various algorithms using which the decision tree is constructed. These are:
- ID3 algorithm (Iterative Dichotomiser 3 algorithm)
- CART (Classification and Regression Testing)
- Chi-square method
- Decision Stump
- M5 algorithm
b. Bayesian Algorithm:
For Bayesian methods, it is obvious that the Bayes theorem is there in all methods.
Bayes theorem is all about probability, especially conditional probability. It suggests that an event A will happen if an event B has already happened.
The most famous algorithm used is the Naïve Bayes theorem. It works on probability and it can calculate the likelihood of events to happen.
There are various other algorithms like:
- Gaussian Naïve Bayes theorem
- Multinomial Naïve Bayes theorem
- Bayesian Belief Network
c. Clustering Algorithms:
This is an unsupervised learning approach, which is very useful when it comes to grouping of data. Here, in clustering, similar types of data occur in a single group or cluster. Whereas, if data is not similar, then it occurs in some other group or cluster.
The algorithms used are:
- K-means
- K-medians
- Hierarchical clustering
d. Artificial Neural Network (ANN) Algorithms:
ANNs work on the exact concept of biological neurons (the nerve cells) in your brain. An ANN consists of many artificial neurons, which perform the exact task as the nerve cell in a brain.
The neural networks are a concept of Deep Learning. They can simulate the biological nervous system. It is capable of both Machine Learning and also pattern recognition.
ANN is mainly an information processing technique. It is also a type of graph consisting of nodes and connecting arcs.
The neural network consists of three layers. The input layer, the hidden layer, and the output layer. The input layer takes the input. The hidden layer processes the input data. It performs various tasks on the given data. Then the processed data passes through the output layer. Each neuron is represented by a circle. Whereas, the connections here are arc-shaped.
There are various algorithms in ANN:
- Perceptron learning
- Multilayer perceptron
- Back-propagation
- Stochastic gradient descent
Companies Using Machine Learning

1. Google
Google is one of the leading tech giants and it has made huge progress in AI and ML. It has various cloud-based machine learning systems and it also uses it in its search engine. Recently, it developed a chatbot that will answer your queries.
2. Microsoft
Microsoft has one of the leading AL and ML programs in the world. It is researching on automated agriculture, water management using AI and ML. There are numerous projects like these.
3. Nvidia
Nvidia is one of the largest and most successful GPU makers in the world. It uses ML and data science to improve GPU processing quality to give better performance. GPU is available in many gaming laptops and desktops and also in some I5 generation laptops.
4. Intel
Intel is one of the leading chip and processor making company in the world. Its main goal is to make faster and more efficient processors so that your systems give better performance.
For higher version computers, it is now using ML methods for better processing accuracy.
Machine Learning Case Study
There are many case studies of ML which we can refer to. Since we are only at the basic Machine Learning tutorial, we will take one for an overview.
So, let’s talk about Tesla.
Tesla is now a big player in the electric automobile industry. It is widely known for its advanced and futuristic cars. The company says that the cars have their own AI hardware. Tesla is using AI for making self-driving cars. At the moment, cars are not completely autonomous. The company is working on the thinking algorithm for cars. It is currently working with NVIDIA on an unsupervised ML algorithm.
This step by Tesla would be a game-changer for many reasons. The cars send data directly to tesla’s cloud.
The car sends the driver’s seating position, traffic of area, and other valuable info. The car is equipped with various internal and external sensors that detect things.
This data is used for making highly detailed maps that are used for navigation. The map will show slow traffic movements, areas to avoid, etc.
The cloud of tesla holds the data of all of its cars. So, the ML algorithm is applied in the cloud server. It can train all the vehicles to go according to the map. Also, cars use edge computing to decide the car movements and other actions.
Tesla, however, came under pressure from various firms. Many still think that the system might cause more accidents.
But, this is not true. With the advancement in systems, cars are adapting fast. The data collected from the car is really important.
In terms of money, it could generate a revenue of 750 to 800 billion dollars by 2030. If all goes well, Tesla might become one of the most profitable companies in the future.
Summary
Hence, in this Machine Learning tutorial, we studied what is machine learning. Why is it necessary in today’s time and how does it work. We also looked at various ML algorithms and approaches and studied them in detail. We saw various leading companies that are using ML at the moment. Then, at last, we looked at a case study of tesla.
The case study helped to understand various innovative and economic aspects of ML. From this Machine Learning tutorial, we can conclude that ML has now become a really important part of today’s world. Therefore, we must learn about it in detail to make further progress.