Java Interview Questions for Experienced Professionals
Are you looking to upgrade your profile and get a dream job? If yes, this is the perfect place. TechVidvan is providing a comprehensive list of Java interview questions for experienced professionals. We have compiled all the popular interview questions along with the answers.
This is the third and final part in the series of Java Interview questions. In this series, we are providing 370 Java interview questions and answers in 3 parts:
- Java Interview questions and answers for freshers
- Java Interview questions and answers for intermediates
- Java Interview questions and answers for experienced

Java Interview Questions and Answers for Experienced
After completing the beginner and intermediate level interview questions and answers in Java, we have come with the advanced level interview questions of core Java. These interview questions are for the experienced developers in Java. So let’s begin with Java interview questions for experienced professionals.
Q.1. What is JCA in Java?
Answer. The term JCA stands for Java Cryptography Architecture. Sun Microsystems introduced it to implement security functions for the Java platform. JCA provides a platform and gives architecture and APIs for encryption and decryption of data. Many developers use JCA to combine their applications with the security measure. A Java programmer uses JCA to fulfill security measures. JCA also helps in performing the security rules of the third party. JCA uses the hash tables, encryption message digest, etc. to implement the security functions.
Q.2. What is JPA in Java?
Answer. JPA stands for Java Persistence API(Application Programming Interface). JPA is a standard API that allows us to access databases from within Java applications. It also enables us to create the persistence layer for desktop and web applications.
The main advantage of using JPA over JDBC is that JPA represents the data in the form of objects and classes instead of tables and records as in JDBC.
Java Persistence deals with the following:
1. Java Persistence API
2. Query Language
3. Java Persistence Criteria API
4. Object Mapping Metadata
Q.3. What is JMS in Java?
Answer. JMS stands for Java Message Service. JMS helps to create the communication interface between two clients using the message passing services. It helps the application to interact with other components irrespective of the location of the components, whether they depend on the same system or connect to the main system through LAN or the internet.
Q.4. What is a Chained Exception in Java?
Answer. When the first exception causes another exception to execute in a program, such a condition is termed as Chained Exception. Chained exceptions help in finding the root cause of the exception that occurs during the execution of the application.
Below are the constructors that support chained exceptions in Throwable classes:
1. Throwable initCause(Throwable)
2. Throwable(Throwable)
3. Throwable(String, Throwable)
4. Throwable getCause()
Q.5. State the differences between JAR and WAR files in Java?
Answer. The differences between the JAR file and the WAR file are the following:
- JAR file stands Java Archive file that allows us to combine many files into a single file. Whereas, WAR files stand for Web Application Archive files that store XML, java classes, and JavaServer pages, etc., for Web Application purposes.
- JAR files hold Java classes in a library. Whereas, WAR files store the files in the ‘lib’ directory of the web application.
- All the enterprise Java Bean classes and EJB deployment descriptors present in the EJB module are packed and stored in a JAR file with .jar extension. Whereas, the WAR file contains the web modules such as Servlet classes, GIFs, HTML files, JSP files, etc., with .war extension.
Q.6. What is the dynamic method dispatch in Java?
Answer. Dynamic Method Dispatch is also called runtime polymorphism. It is a method in which the overridden method is resolved during the runtime, not during the compilation of the program. More specifically, the concerned method is called through a reference variable of a superclass.
Q.7. How does HashMap work in Java?
Answer. A HashMap in Java works by storing key-value pairs. The HashMap uses a hash function and requires the hashCode() and equals() methods to put elements into a collection and retrieve them from the collection. On the invocation of the put() method, the HashMap calculates the hash value of the key and then stores the pair in the particular index inside the collection. If there is a key, it updates the value of the key with the new value. Some important characteristics of a HashMap are its capacity, its load factor, and the threshold resizing.
Q.8. What are the differences between HashMap and Hashtable?
Answer. The differences between HashMap and Hashtable in Java are:
- Hashtable is synchronized while HashMap is not synchronized. For the same reason, HashMap works better in non-threaded applications, because unsynchronized objects typically perform better than synchronized ones.
- Hashtable does not allow null keys or null values whereas HashMap allows one null key and any number of null values.
- One of the subclasses of HashMap is LinkedHashMap, so if we want a predictable iteration order in the event, we can easily swap out the HashMap for a LinkedHashMap. But, this would not be as easy using Hashtable.
Q.9. What is the role of System.gc() and Runtime.gc() methods in Java?
Answer. System class contains a static method called gc() for requesting JVM to run Garbage Collector. Using Runtime. getRuntime(). gc() method, the Runtime class allows the application to interact with the JVM in which the application is running. Both the methods System.gc() and Runtime.gc() help to give a hint to the JVM, so that JVM can start a garbage collection. However, it is up to the Java Virtual Machine (JVM) to start the garbage collection immediately or later in time.
Q.10. Does not overriding hashCode() method have any impact on performance?
Answer. A poor hashCode() function will result in the frequent collision in HashMap. This will eventually increase the time for adding an object into HashMap. But, from Java 8 onwards, the collision will not impact performance as much as it does in earlier versions. This is because after crossing a threshold value, the linked list gets replaced by a binary tree, which will give us O(logN) performance in the worst case as compared to O(n) of a linked list.
Q.11. What happens when we create an object in Java?
Answer. Following things take place during the creation of an object in Java:
- Memory allocation: Memory allocation takes place to hold all the instance variables of the class and implementation-specific data of the object.
- Initialization: Initialization occurs to initialize the objects to their default values.
- Constructor: Constructors invoke the constructors for their parent classes. This process goes on until the constructor for java.langObject is called. The java.lang.Object class is the base class for all objects in Java.
- Execution: Before the execution of the body of the constructor, all the instance variables should be initialized and there must be the execution of all the initialization blocks. After that, the body of the constructor is executed.
Q.12. When do you override hashCode() and equals() methods in Java?
Answer. We override the hashCode() and equals() methods whenever it is necessary. We override them especially when we want to do the equality check based upon business logic rather than object equality. For example, two employee objects are equal if they have the same empId, despite the fact that they both are two different objects, created using different parts of the code.
Also overriding both these methods is a must when we need them as keys in HashMap. As a part of the equals-hashcode contract in Java, when you override the equals() method, we must override hashCode() as well, otherwise, the object will not break invariants of classes. For example, the Set, Map which relies on the equals() method for functioning properly.
Q.13. What will be the problem if you do not override the hashCode() method?
Answer. If we do not override the equals() method, then the contract between equals and hashcode will not work. So the two objects which are equal by equals() method must have the same hashcode. In this case, another object may return a different hash code and will be stored in that location. This breaks the invariants of the HashMap class because they do not allow duplicate keys.
When we add the object using the put() method, it iterates through the whole Map.Entry objects present in that bucket location. It also updates the value of the previous mapping value if Map already contains that key. This will not work if we do not override the hashcode()method.
Q.14. What is the difference between creating the String as a literal and with a new operator?
Answer. When we create an object of String in Java using a new() operator, it is created in a heap memory area and not into the String pool. But when we create a String using literal, then it gets stored in the String pool itself. The String pool exists in the PermGen area of heap memory.
For example,
String str = new String("java");
The above statement does not put the String object str in the String pool. We need to call the String.intern() method to put the String objects into the String pool explicitly.
It is only possible when we create a String object as String literal.
For example,
String str1 = "java";
Java automatically puts the String object into the String pool.
Q.15. Which are the different segments of memory?
Answer.
- Stack Segment: The stack segment contains the local variables and reference variables. Reference variables hold the address of an object in the heap segment.
- Heap Segment: The heap segment contains all the objects that are created during runtime. It stores objects and their attributes (instance variables).
- Code Segment: The code segment stores the actual compiled Java bytecodes when loaded.
Q.16. Does the garbage collector of Java guarantee that a program will not run out of memory?
Answer. There is no guarantee that using a Garbage collector will ensure that the program will not run out of memory. As garbage collection is an automatic process, programmers need not initiate the garbage collection process explicitly in the program. A Garbage collector can also choose to reject the request and therefore, there is no guarantee that these calls will surely do the garbage collection. Generally, JVM takes this decision based on the availability of space in heap memory.
Q.17. Describe the working of a garbage collector in Java.
Answer. Java Runtime Environment(JRE) automatically deletes objects when it determines that they are no longer useful. This process is called garbage collection in Java. Java runtime supports a garbage collector that periodically releases the memory from the objects that are no longer in need.
The Java Garbage collector is a mark and sweeps garbage collector. It scans dynamic memory areas for objects and marks those objects that are referenced. After finding all the possible paths to objects are investigated, those objects that are not marked or not referenced) are treated like garbage and are collected.
Q.18. What is a ThreadFactory?
Answer. A ThreadFactory is an interface in Java that is used to create threads rather than explicitly creating threads using the new Thread(). It is an object that creates new threads on demand. The Thread factory removes hardwiring of calls to new Thread and enables applications to use special thread subclasses, and priorities, etc.
Q.19. What is the PermGen or Permanent Generation?
Answer. PermGen is a memory pool that contains all the reflective data of the Java Virtual Machine(JVM), such as class, objects, and methods, etc. The Java virtual machines that use class data sharing, the generation is divided into read-only and read-write areas. Permanent generation contains the metadata required by JVM to describe the classes and methods used in Java application. Permanent Generation is populated by the JVM during the runtime on the basis of classes used by the application. Additionally, Java SE(Software Edition) library classes and methods may also be stored in the PermGen or Permanent generation.
Q.20. What is a metaspace?
Answer. The Permanent Generation or PermGen space has been completely removed and replaced by a new space called Metaspace. The result of removing the PermGen removal is that the PermSize and MaxPermSize JVM arguments are ignored and we will never get a java.lang.OutOfMemoryError: PermGen error.
Q.21. What is the difference between System.out, System.err and System.in?
Answer. Both System.out and System.err represent the Monitor by default. Hence they are used to send or write data or results to the monitor. System.out displays normal messages and results on the monitor whereas System.err displays the error messages. System.in represents an InputStream object, which by default represents a standard input device, that is, the keyboard.
Q.22. Why is the Char array preferred over String for storing passwords?
Answer. As we know that String is immutable in Java and stored in the String pool. Once we create a String, it stays in the String pool until it is garbage collected. So, even though we are done with the password it is still available in memory for a longer duration. Therefore, there is no way to avoid it.
It is clearly a security risk because anyone having access to a memory dump can find the password as clear text. Therefore, it is preferred to store the password using the char array rather than String in Java.
Q.23. What is the difference between creating an object using new operator and Class.forName().newInstance()?
Answer. The new operator statically creates an instance of an object. Whereas, the newInstance() method creates an object dynamically. While both the methods of creating objects effectively do the same thing, we should use the new operator instead of Class.forName(‘class’).getInstance().
The getInstance() method uses the Reflection API of Java to lookup the class at runtime. But, when we use the new operator, Java Virtual Machine will know beforehand that we need to use that class and therefore it is more efficient.
Q.24. What are the best coding practices that you learned in Java?
Answer. If you are learning and working on a programming language for a couple of years, you must surely know a lot of its best practices. The interviewer just checks by asking a couple of them, that you know your trade well. Some of the best coding practices in Java can be:
- Always try to give a name to the thread, this will immensely help in debugging.
- Prefer to use the StringBuilder class for concatenating strings.
- Always specify the size of the Collection. This will save a lot of time spent on resizing the size of the Collection.
- Always declare the variables as private and final unless you have a good reason.
- Always code on interfaces instead of implementation.
- Always provide dependency on the method instead they get it by themselves. This will make the coding unit testable.
Q.25. What is CountDownLatch in Java?
Answer. CountDownLatch in Java is like a synchronizer. It allows a thread to wait for one or more threads before starting the process. CountDownLatch is a very crucial requirement and we often need it in server-side core Java applications. Having this functionality built-in as CountDownLatch simplifies the development.
CountDownLatch in Java was introduced on Java 5 along with other concurrent utilities like CyclicBarrier, Semaphore, ConcurrentHashMap, and BlockingQueue. These are all present in the java.util.concurrent package.
Java Interview Questions for Experienced Developers
As time is changing and the competition is increasing day by day, gone are the days when the interview questions used to be very simple and straightforward. Now you have to get ready with tricky interview questions as well:
Q.26. What is CyclicBarrier in Java?
Answer. The CyclicBarrier class is present in the java.util.concurrent package. It is a synchronization mechanism that synchronizes threads progressing through some algorithm. CyclicBarrier class is a barrier at which all the threads until all threads reach it.
A CyclicBarrier is used when multiple threads carry out different subtasks and there is a need to combine the output of these subtasks to form the final output. After completing its execution, threads call the await() method and wait for other threads to reach the barrier.
Q.27. Differentiate between CountDownLatch and CyclicBarrier in Java?
Answer. Both CyclicBarrier and CountDownLatch are useful tools for synchronization between multiple threads. However, they are different in terms of the functionality they provide.
CountDownLatch allows one or more than one thread to wait for a number of tasks to complete while CyclicBarrier allows a number of threads to wait on each other. In short, CountDownLatch maintains a count of tasks whereas CyclicBarrier maintains a count of threads.
When the barrier trips in the CyclicBarrier, the count resets to its original value. CountDownLatch is different because the count never resets to the original value.
Q.28. What is the purpose of the Class.forName method?
Answer. This forName() method loads the driver that establishes a connection to the database. The forName() method belongs to java.lang.Class class. This method gets the instance of this Class with the specified class name. The method Class. forName(String name, boolean initialize, ClassLoader loader) returns the object of Class associated with the class or interface with the given string name, using the specified class loader. The specified class loader loads the class or interface.
Q.29. Why does the Collection interface not extend the Cloneable or Serializable interfaces?
Answer. The Collection interface does not extend the Cloneable or Serializable interfaces because the Collection is the root interface for all the Collection classes like ArrayList, LinkedList, HashMap, etc. If the collection interface extends Cloneable or Serializable interfaces, then it is making compulsory for all the concrete implementations of this interface to implement Cloneable and Serializable interfaces. Collection interfaces do not extend Cloneable or Serializable interfaces to give freedom to concrete implementation classes.
Q.30. What is the advantage of using getters and setters?
Answer. Getters and Setters methods are used to get and set the properties of an object. The advantages are:
- We can check if new data is valid before setting a property.
- We can perform an action on the data which we are getting or setting on a property.
- We can control which properties we can store and retrieve.
Q.31. What is RMI?
Answer. RMI in Java stands for Remote Method Invocation. RMI is an API in Java that allows an object residing in one system or JVM to access or invoke an object running on another system or JVM. RMI is used to create distributed applications in Java. It provides remote communication between Java programs using two objects: stub and skeleton. It is present in the package java.rmi.
Q.32. State the basic principle of RMI architecture?
Answer. The principle of RMI architecture states that “the definition of the behavior and the implementation of that behavior are treated as separate concepts. Remote method Invocation allows the code that defines the behavior and the code that implements the behavior to remain separate and to run on separate JVMs”.
Q.33. What is the role of using Remote Interface in RMI?
Answer. A Remote Interface is an interface that is used to declare a set of methods that we can invoke from a remote Java Virtual Machine. The java.rmi.Remote interface is a marker interface that defines no methods:
public interface Remote {}
A remote interface must satisfy the following conditions:
- A remote interface should extend at least the java.rmi.Remote interface, either directly or indirectly.
- The declaration of Each method in a remote interface or its super-interfaces must satisfy the following requirements of a remote method declaration:
— The declaration of the remote method must include the exception of java.rmi.RemoteException in its throws clause.
— A remote object that is declared as a parameter or return value must be declared as the remote interface in a remote method declaration, not the implementation class of that interface.
Q.34. What is the role of java.rmi.Naming Class in RMI?
Answer. The Naming class of java.rmi package provides methods for storing and obtaining references to remote objects in a remote object registry. The methods of the java.rmi.Naming class makes calls to a remote object. This implements the Registry interface using the appropriate LocateRegistry.getRegistry method.
The Naming class also provides methods to get and store the remote object. The Naming class provides five methods:
| lookup() | This method returns the reference of the remote object. |
| bind() | This method binds the remote object with the given name. |
| unbind() | It destroys the remote object bound with the given name. |
| rebind() | rebind() method binds the remote object to the new name. |
| list() | This method returns an array of the names of the remote objects in the registry. |
Q.35. What is meant by binding in RMI?
Answer. Binding is the process of registering or associating a name for a remote object, that we can use later in order to look up that remote object. It associates the remote object with a name using the bind() or rebind() methods of the Naming class of java.rmi package.
Q.36. What is the purpose of RMISecurityManager in RMI?
Answer. RMISecurityManager is a class in the RMI package of Java. It provides a default security manager for RMI applications that need it because they use downloaded code. The classloader of RMI’s will not download any classes if the user has not set any security manager. We cannot apply RMISecurityManager to applets that run under the protection of the security manager of their browser.
To set the RMISecurityManager, we need to add the following to an application’s main() method:
System.setSecurityManager(new RMISecurityManager());
Q.37. Explain Marshalling and unmarshalling.
Answer. Marshalling: When a client invokes a method that accepts parameters on a remote object, it bundles the parameters into a message before sending it over the network. These parameters can be of primitive type or objects. When the parameters are of primitive type, they are put together and a header is attached to it. If the parameters are objects, then they are serialized. This process is called marshalling.
Unmarshalling: The packed parameters are unbundled at the server-side, and then the required method is invoked. This process is called unmarshalling.
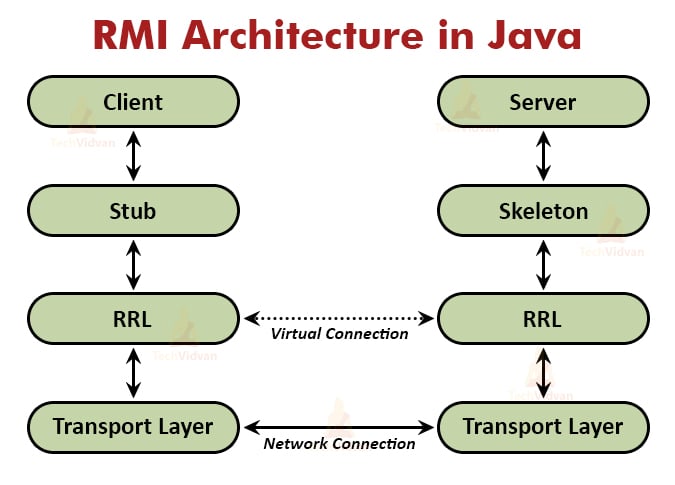
Q.38. What are the layers of RMI Architecture?
Answer. There are three layers of RMI architecture: the Stub and Skeleton Layer, the Remote Reference Layer, and the Transport Layer.
- The stub and skeleton layer helps in marshaling and unmarshaling the data and transmits them to the Remote Reference layer and receives them from the Remote Reference Layer.
- The Remote reference layer helps in carrying out the invocation. This layer manages the references made by the client to the remote object.
- The Transport layer helps in setting up connections, managing requests, monitoring the requests, and listening to incoming calls.
Q.39. What is the difference between a synchronized method and a synchronized block?
Answer. The differences between a synchronized method and a synchronized block are:
1. A synchronized method uses the method receiver as a lock. It uses ‘this’ for non-static methods and the enclosing class for static methods. Whereas, the synchronized blocks use the expression as a lock.
2. A synchronized method locks on that object only in which the method is present, while a synchronized block can lock on any object.
3. The synchronized method holds the lock throughout the method scope. While the lock is held only during that block scope, also known as the critical section in the synchronized block.
4. If the expression provided as parameter evaluates to null, the synchronized block can throw NullPointerException while this is not the case with synchronized methods.
5. The synchronized block offers granular control overlock because we can use any lock to provide mutual exclusion to critical section code. The synchronized method always locks either class level lock on the current object, if its static synchronized method.
Q.40. Write a simple program on a synchronized block.
Answer.
Program of Synchronized Block:
class Table {
void printTable(int n) {
synchronized(this) {
//synchronized block
for (int i = 1; i <= 5; i++) {
System.out.println(n * i);
try {
Thread.sleep(400);
}
catch(Exception e) {
System.out.println(e);
}
}
}
} //end of the method
}
class MyThread1 extends Thread {
Table t;
MyThread1(Table t) {
this.t = t;
}
public void run() {
t.printTable(5);
}
}
public class Test {
public static void main(String args[]) {
Table obj = new Table(); //only one object
MyThread1 t1 = new MyThread1(obj);
t1.start();
}
}
Q.41. Differentiate between Serial and Throughput Garbage collectors?
Answer. Serial Garbage collector uses one thread to perform garbage collection in Java. On the other hand, Throughput garbage collector uses multiple threads to perform garbage collection.
We can use Serial Garbage Collector for applications that run on client-style machines and do not have low pause time requirements. Throughput Garbage Collector can be chosen for applications that have low pause time requirements.
Q.42. What is Double Brace initialization in Java?
Answer. Double brace initialization in Java is a combination of two separate Java processes. When we use the initialization block for an anonymous inner class it becomes double brace initialization in Java. The inner class that we created will have a reference to the enclosing outer class. We can use that reference using the ‘this’ pointer.
Q.43. What is Connection Pooling in Java?
Answer. Connection pooling is a mechanism where we create and maintain a cache of database connections. Connection Pooling has become the standard for middleware database drivers. A connection pool creates the connections ahead of time. When there is a JDBC connection pool, there is a creation of a pool of Connection objects when the application server starts.
Connection pooling is used to create and maintain a collection of JDBC connection objects. The primary objective of connection pooling is to leverage reusability and improve the overall performance of the application.
Q.44. Differentiate between an Applet and a Java Application?
Answer.
| Application | Applet |
| Applications are stand-alone programs that run independently without using a web browser. | Applets are small Java programs that are included in an HTML web document. |
| Applications require a Java-enabled browser for execution. They have full access to the local file system and network. | Applets have no disk space and network access. |
| The application requires a main method() for its execution. | An Applet does not require the main method() for its execution. |
| We can run Applications using programs from the local system. | We cannot run applets using programs from the local machine. |
| An application program performs some tasks directly for the user. | An applet program performs small tasks or parts of it. |
| An application can access all kinds of resources available on the system. | Applets can only access the browser-specific services. |
Advanced Java Interview Questions – JSPs & Servlets
Q.45. What is a JSP Page?
Answer. A JSP(Java Server Page) page is a text document that has two types of text: static data and JSP elements. We can express Static data in any text-based format such as HTML, SVG, WML, and XML. JSP elements construct dynamic content.
The file extension used for the JSP source file is .jsp. The JSP page can contain a top file that includes other files containing either a fragment of a JSP page or a complete JSP page. The extension used for the source file of a fragment of a JSP page is .jspf.
The elements of JSP in a JSP page can be expressed in two syntaxes: standard and XML. But, any file can use only one syntax.
Q.46. What is a Servlet?
Answer. A servlet in Java is a class that extends the capabilities of servers that host applications accessed using a request-response programming model. Servlets can be used to respond to any type of request, but they commonly extend the applications hosted by web servers.
A servlet handles requests, processes them, and replies back with a response. For example, a servlet can take input from a user using an HTML form, trigger queries to get the records from a database and create web pages dynamically.
The primary purpose of the Servlet is to define a robust mechanism to send content to a client-defined by the Client/Server model. The most popular use of servlets is for generating dynamic content on the Web and have native support for HTTP.
Q.47. How are the JSP requests handled?
Answer. When the JSP requests arrive, the browser first requests a page that has a .jsp extension. Then, the webserver reads the request. The Web server converts the JSP page into a servlet class using the JSP compiler. The JSP file gets compiled only on the first request of the page, or if there is any change in the JSP file. The generated servlet class is invoked to handle the browser’s request. The Java servlet sends the response back to the client when the execution of the request is over.
Q.48. What are Directives?
Answer. JSP directives are the elements or messages of a JSP container. They are the part of a JSP source code that guides the web container to translate the JSP page into its respective servlet. They provide global information about an entire JSP page.
Directives are instructions that JSP engine processes to convert a page into a servlet. Directives set page-level instructions, insert data from external files, and specify custom tag libraries. There can be many comma-separated values in directives. Directives are defined between < %@ and % >.
Q.49. What are the different types of Directives present in JSP?
Answer. The different types of directives are:
- Include directive: The include directive is useful to include a file. It merges the content of the file with the current page.
- Page directive: The page directive defines specific attributes in the JSP page, such as error page and buffer, etc.
- Taglib: Taglib is used to declare a custom tag library used on the page.
Q.50. What are JSP actions?
Answer. JSP actions use constructs in XML syntax that are used to control the behavior of the servlet engine. JSP actions are executed when there is a request for a JSP page. We can insert JSP actions dynamically into a file. JSP actions reuse JavaBeans components, forward the user to another page, and generate HTML for the Java plugin.
Some of the available JSP actions are listed below:
- jsp:include: It includes a file when there is a request for a JSP page.
- jsp:useBean: It instantiates or finds a JavaBean.
- jsp:setProperty: It is used to set the property of a JavaBean.
- jsp:getProperty: It is used to get the property of a JavaBean.
- jsp:forward: It forwards the requester to a new page.
- jsp:plugin: It generates browser-specific code.
Q.51. What are Declarations?
Answer. Declarations in JSP are similar to variable declarations in Java. They are used to declare variables for subsequent use in expressions or scriptlets. It is necessary to use the sequences to enclose your declarations to add a declaration.
Q.52. What are Expressions?
Answer. An expression in JSP is used to insert the value of a scripting language expression. It converts them into a string, into the data stream returned to the client, by the webserver. Expressions are defined between <% = and %> tags.
Expression Tag in JSP writes content on the client-side. This tag displays information on the client browser. The JSP Expression tag converts the code into an expression statement that turns into a value in the form of string object and inserts into the implicit output object.
Q.53. Explain the architecture of a Servlet.
Answer. The core abstraction that all servlets must implement is javax.servlet.Servlet interface. Every servlet must implement this interface either directly or indirectly. The servlet can implement it either by extending javax.servlet.http.HTTPServlet or javax.servlet.GenericServlet. Each servlet should be able to serve multiple requests in parallel using multithreading.
Q.54. State the difference between sendRedirect and forward methods?
Answer. The sendRedirect() method creates a new request, whereas the forward() method forwards the request to a new target. The scope objects of the previous request are not available after a redirect, because it results in a new request. On the other hand, the scope objects of the previous request are available after forwarding. Generally, the sendRedirect method is considered to be slower as compared to the forward method.
Applet Java Interview questions
Q.55. What is an Applet?
Answer. An applet is a Java program that is embedded into a web page. An applet runs inside the web browser and works at the client-side. We can embed an applet in an HTML page using the APPLET or OBJECT tag and host it on a web server. Applets make the website more dynamic and entertaining.
Q.56. Explain the life cycle of an Applet.
Answer.
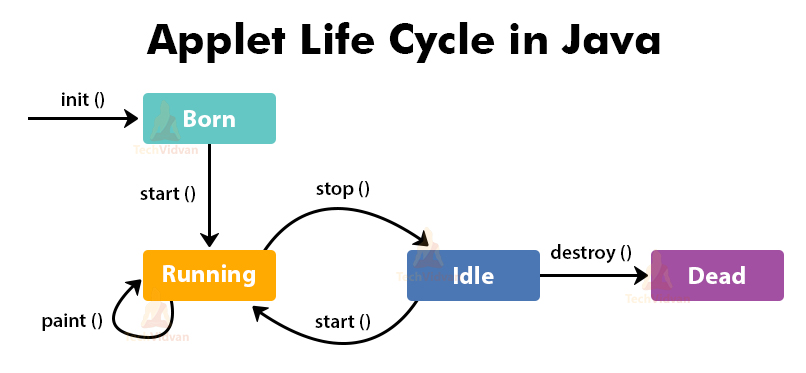
The above diagram shows the life cycle of an applet that starts with the init() method and ends with destroy() method. Other methods of life cycle are start(), stop() and paint(). The methods init() and destroy() execute only once in the applet life cycle. Other methods can execute multiple times.
Below is the description of each method of the applet life cycle:
init(): The init() is the initial method that executes when the applet execution starts. In this method, the variable declaration and initialization operations take place.
start(): The start() method contains the actual code to run the applet. The start() method runs immediately after the init() method executes. The start() method executes whenever the applet gets restored, maximized, or moves from one tab to another tab in the browser.
stop(): The stop() method is used to stop the execution of the applet. The stop() method executes when the applet gets minimized or moves from one tab to another in the browser.
destroy(): The destroy() method gets executed when the applet window or tab containing the webpage closes. The stop() method executes just before the invocation of destroy() method The destroy() method deletes the applet object from memory.
paint(): The paint() method is used to redraw the output on the applet display area. The paint() method executes after the execution of start() method and whenever the applet or browser is resized.
Q.57. What happens when an applet is loaded?
Answer. When the applet is loaded, first of all, an object of the applet’s controlling class is created. Then, the applet initializes itself and finally starts running.
Q.58. What is the applet security manager? What does it provide?
Answer. The applet security manager class is a mechanism to impose restrictions on Java applets. A browser can have only one security manager. It is established at startup, and after that, we cannot replace, overload, override, or extend it.
Q.59. What are the restrictions put on Java applets?
Answer. Following restrictions are put on Java applets:
- An applet cannot define native methods or load libraries.
- An applet cannot write or read files on the execution host.
- An applet cannot read some system properties.
- An applet cannot make network connections except the host from which it came.
- An applet cannot initiate any program on the host which is executing it.
Q.60. What are untrusted applets?
Answer. Untrusted applets are those applets in Java that cannot access or execute local system files. By default, all downloaded applets are treated as untrusted. Untrusted applets can not perform operations such as reading, writing or deleting files from the local file system. They are not allowed to access files on the local computer and access the network connections from the computer.
Q.61. What is the difference between a ClassNotFoundException and NoClassDefFoundError?
Answer. ClassNotFoundException and NoClassDefFoundError exceptions occur when a particular class is not found during the runtime. However, they differ from each other and occur in different scenarios.
A ClassNotFoundException is an exception that occurs when we try to load a class during the runtime using methods like Class.forName() or loadClass() methods and these classes are not found in the classpath. Whereas NoClassDefFoundError is an error that occurs when a particular class is present at compile-time but missing at run time.
| ClassNotFoundException | NoClassDefFoundError |
| It is an exception. It is of type java.lang.Exception. | It is an error. It is of type java.lang.Error. |
| It occurs when an application tries to load a class at runtime which is not present in the classpath. | It occurs when the Java runtime system does not find a class definition, which is present at compile-time but missing at run time. |
| It is thrown by methods like ,loadClass(), Class.forName(), and findSystemClass(). | Java Runtime System throws this error. |
| It occurs when there is no update of classpath with required JAR files. | It occurs when the definition of the required class is missing at runtime. |
Q.62. What Are The Attributes Of Applet Tags?
Answer.
- height: It defines the height of applet.
- width: It defines the width of the applet.
- align: It defines the text alignment around the applet.
- alt: It is an alternate text that is to be displayed if the browser supports applets but cannot run this applet.
- code: It is an URL that points to the class of the applet.
- codebase: It indicates the base URL of the applet if the code attribute is relative.
- hspace: It defines the horizontal spacing around the applet.
- vspace: It defines the vertical spacing around the applet.
- name: It defines a name for an applet.
- object: It defines the resource name that contains a serialized representation of the applet.
- title: It displays information in the tooltip.
Q.63. What is the difference between applets loaded from the internet and applets loaded via the file system?
Answer. When an applet is loaded from the internet, the applet gets loaded by the applet classloader and there are restrictions enforced on it by the applet security manager. When an applet is loaded from the client’s local file system, the applet is loaded by the file system loader.
Applets that are loaded via the file system are allowed to read files, write files, and to load libraries on the client. Also, they are allowed to execute processes and are not passed through the byte code verifier.
Q.64. What is the applet class loader?
Answer. When an applet gets loaded over the internet, the applet classloader loads the applet. The applet class loader enforces the Java namespace hierarchy. The classloader also guarantees that a unique namespace exists for classes that come from the local file system, and there exists a unique namespace for each network source.
When an applet is loaded by the browser over the internet, the classes of that applet are placed in a private namespace associated with the origin of the applet. After that, the classes loaded by the class loader are passed through the verifier. The verifier checks that the class file matches the Java language specification. The verifier also ensures that there are no stack overflows or underflows and that the parameters to all bytecode instructions are correct.
Q.65. What is the difference between an event-listener interface and an event-adapter class?
Answer. An EventListener interface defines the methods that an EventHandler must implement for a particular kind of event whereas an EventAdapter class provides a default implementation of an EventListener interface.
Q.66. What are the advantages of JSP?
Answer. The advantages of using the JSP are:
- JSP pages are compiled into servlets and therefore, the developers can easily update their presentation code.
- JSP pages can be precompiled.
- Developers can easily combine JSP pages to static templates, including HTML or XML fragments, with code that generates dynamic content.
- Developers can offer customized JSP tag libraries. The page authors can access these libraries using an XML-like syntax.
- Developers can make changes in logic at the component level, without editing the individual pages that use the application’s logic.
Q.67. What are Scriptlets?
Answer. A scriptlet in Java Server Pages (JSP) is a piece of Java code that is embedded in a JSP page. The scriptlet is everything that is present inside the tags. A user can add any valid scriptlet between these tags.
Q.68. What is meant by JSP implicit objects and what are they?
Answer. JSP implicit objects are those objects in Java that the JSP container makes available to developers on each page. A developer can call these objects directly without declaring them explicitly. JSP Implicit Objects are also called pre-defined variables. The objects are considered as implicit in a JSP page are:
- application
- page
- request
- response
- session
- exception
- out
- config
- pageContext
Q.69. State the difference between GenericServlet and HttpServlet?
Answer. GenericServlet is a protocol-independent and generalized servlet that implements the Servlet and ServletConfig interfaces. The servlets extending the GenericServlet class must override the service() method. Finally, if you need to develop an HTTP servlet for use on the Web that serves requests using the HTTP protocol, your servlet must extend the HttpServlet.
Q.70. State the difference between an Applet and a Servlet?
Answer. An Applet is a client-side Java program that runs on a client-side machine within a Web browser. Whereas, a Java servlet is a server-side component that runs on the webserver. An applet uses the user interface classes, while a servlet does not have a user interface. Instead, a servlet waits for HTTP requests from clients and generates a response in every request.
Q.71. Explain the life cycle of a Servlet.
Answer. The Servlet Engine loads the servlets on every client’s request, and invokes its init methods, for the servlet to be initialized. Then, the object of the Servlet handles all subsequent requests coming from that client, by invoking the service() method for each request separately. Finally, the servlet gets removed by calling the destroy() method.
The life cycle of the servlet is:
- Servlet class gets loaded.
- Creation of Servlet instance.
- init() method gets invoked.
- service() method is invoked.
- destroy() method is invoked.
Q.72. Differentiate between doGet() and doPost()?
Answer. doGet(): The doGet() method appends the name-value pairs on the URL of the request. Therefore, there is a restriction on the number of characters and subsequently on the number of values used in a client’s request. Also, it makes the values of the request visible, and thus, sensitive information must not be passed in that way.
doPost(): The doPost() method overcomes the limit of the GET request. it sends the values of the request inside its body. Furthermore, there are no limitations on the number of values to be sent across. Finally, the sensitive information that is passed through a POST request is not visible to an external client.
Q.73. What is the difference between final, finalize, and finally?
Answer. Below is a list of differences between final, finally and finalize:
| No. | final | finally | finalize |
| 1) | The final keyword applies restrictions on class, method, and variable. We can not inherit the final class, we cannot change the value of a final variable and also can not override the final method. | The finally block places the important code. This code will be executed whether an exception is handled or not. | The finalize method performs the cleanup processing just before the object is garbage collected. |
| 2) | The Final is a keyword. | Finally is a block. | Finalize is a method. |
Java Developer Interview Questions
These questions are frequently asked from Java developers during the interviews:
Q.74. What is a Server Side Include (SSI)?
Answer. Server Side Includes (SSI) is a simple and interpreted server-side scripting language. SSI is used almost exclusively for the Web. It is embedded with a servlet tag. Including the contents of one or more than one file into a Web page on a Web server is the most frequent use of SSI. When a browser accesses a Web page, the Web server replaces the servlet tag on that Web page with the hypertext generated by the corresponding servlet.
Q.75. What is Servlet Chaining ?
Answer. Servlet Chaining is the mechanism where the output of one servlet is sent to the second servlet. The output of the second servlet is sent to a third servlet, and so on. The last servlet in the servlet chain is responsible for sending the response to the client.
Q.76. How can you find out what client machine is making a request to your servlet ?
Answer. There is a ServletRequest class that has functions for finding out the IP address or hostname of the client machine. The getRemoteAddr() method gets the IP address of the client machine and getRemoteHost() method gets the hostname of the client machine.
Q.77. What is the structure of the HTTP response?
Answer. The HTTP response has three parts:
- Status Code: The status code describes the status of the response. We can use it to check if the request has been successfully completed or not. In case the request fails, we can use the status code to find out the reason behind the failure. If our servlet does not return a status code, then by default, the success status code, HttpServletResponse.SC_OK is returned.
- HTTP Headers: HTTP headers contain more information about the response. For example, they may specify the date or time after which the response is considered stale, or the type of encoding used to safely transfer the entity to the user.
- Body: The body contains the content of the HTTP response. The body contains HTML code, images, etc. The body also consists of the data bytes transmitted in an HTTP transaction message immediately following the headers.
Q.78. What is a cookie? Differentiate between session and cookie?
Answer. A cookie is a small piece of data that the Web server sends to the browser. The browser stores the cookies for each Web server in a local file. Cookies provide a reliable mechanism for websites to remember stateful information or to record the browsing activity of users.
The differences between the session and a cookie are:
- The session should work irrespective of the settings on the client’s browser. The client can choose to disable cookies. However, the sessions still work because the client has no ability to disable them on the server-side.
- The session and cookies are also different in the amount of information they can store. The HTTP session can store any Java object, while a cookie can only store String objects.
Q.79. Which protocol can be used by browser and servlet to communicate with each other?
Answer. The browser uses the HTTP protocol to communicate with a servlet.
Q.80. What is HTTP Tunneling?
Answer. HTTP Tunneling is a mechanism that encapsulates the communications performed using various networks using the HTTP or HTTPS protocols. Therefore, the HTTP protocol acts as a wrapper for a channel that the network protocol being tunneled uses to communicate. HTTP Tunneling is the masking of other protocol requests as HTTP requests.
Q.81. What are the differences between sendRedirect and forward methods?
Answer. The sendRedirect() method creates a new request, whereas the forward() method forwards a request to a new target. After using a redirect, the previous request scope objects are not available because it results in a new request. While, after using the forwarding, the previous request scope objects are available. Generally, the sendRedirect method is considered to be slower compared to the forward method.
Q.82. What is URL Encoding and URL Decoding?
Answer. The URL encoding is a procedure responsible for replacing all the spaces and every other extra special character of a URL and converts them into their corresponding Hex representation. URL decoding is the exact opposite procedure of URL Encoding.
Q.83. What is a JavaBean?
Answer. A Bean in Java is a software component that was designed to be reusable in a variety of different environments. Java beans can be visually manipulated in the builder tool. Java Beans can perform simple functions, such as checking the spelling of a document or complex functions such as forecasting the performance of a stock portfolio.
Q.84. What are the advantages of Java Beans?
Answer. Advantages of using Java Beans are
- Java Beans are portable, platform-independent, and stand for the “write-once, run-anywhere” paradigm.
- The properties, methods, and events of Java beans are controlled when exposed to an application builder tool.
- A Java Bean may register to receive events from other objects. It can also generate events that are sent to other objects.
- Beans use object serialization capabilities for gaining persistence.
Q.85. What are the different properties of a Java Bean?
Answer. There are five types of properties of a Java bean:
- Simple property: This property sets a simple property, a pair of accessors. It employs the getXXX (), and mutator, i.e setXXX(), methods.
- Boolean Property: It is a simple property with boolean values: true or false. It sets the values in the mutator method.
- Indexed property: An indexed property is used when a single property can hold an array of values using the pset propertyName (propertyType[] list) method.
- Bound property: The bound property generates an event when the property is changed.
- Constrained property: The constrained property generates an event when an attempt is made to change its value.
Q.86. What are the steps to be followed while creating a new Bean?
Answer. The steps that must be followed to create a new Bean are:
- Create a directory for the new Bean.
- Create the Java source file(s).
- Compile the source file(s).
- Create a manifest file.
- Generate a JAR file.
- Start the BDK.
- Test
Java Interview Questions and Answers for Experienced
Being an experienced Java professional, the expectations will be a bit high, You have to prepare well, below interview questions will provide an edge over other candidates.
Q.87. Differentiate between Java Bean and ActiveX controls?
Answer.
- Java Beans is a framework used to build applications out of Java components or Beans. ActiveX is a framework for building component documents with ActiveX controls.
- A Bean is written in Java and therefore it has security and cross-platform features of Java. On the other hand, ActiveX controls require a port of Microsoft’s Common Object Model (COM) to be used outside Microsoft windows.
Q.88. What is the difference between fail-fast and fail-safe?
Answer. The fail-safe property of the Iterator works with the clone of the underlying collection and therefore, it is not affected by any modification in the collection. All the collection classes in the java. the concurrent package is fail-safe, while the collection classes in java.util.util are fail-fast. Fail-safe iterators never throw such an exception while fail-fast iterators throw a ConcurrentModificationException.
Q.89. What are some of the best practices related to the Java Collection framework?
Answer. Some best practices related to Java collection framework are:
- Selecting the right type of collection to use, based on the needs of the application is very important for its performance. For example, if we know that the size of the elements and it is fixed we should use an Array, instead of an ArrayList.
- There are some collection classes that enable us to specify their initial capacity. Thus, if we have an estimated number of elements that will be stored, then we can use it to avoid rehashing or resizing.
- We should always use Generics for type-safety, readability, and robustness. Also, we use Generics to avoid the ClassCastException during runtime.
- To avoid the implementation of the hashCode and equals methods for our custom class, we should use immutable classes that are provided by the Java Development Kit (JDK) as a key in a Map.
- Try to write the program in terms of interface not implementation.
Q.90. What is DGC? And how does it work?
Answer. DGC in Java stands for Distributed Garbage Collection. DGC is used by Remote Method Invocation (RMI) for automatic garbage collection. As RMI involves remote object references across Java Virtual Machine, the garbage collection process can be quite difficult. The Distributed garbage Collector uses a reference counting algorithm to provide automatic memory management for remote objects.
Q.91. State the role of stub in RMI?
Answer. A stub in RMI(Remote Method Invocation) acts as a local representative for clients or a proxy for the remote object. Caller invokes or calls a method on the local stub, that executes the method on the remote object. When it invokes the stub’s method, it goes through the below steps:
- It starts a connection with the remote JVM that contains the remote object.
- It then marshals the parameters to the remote JVM.
- It waits till it gets the result of the method invocation and execution.
- It unmarshals the returned value or an exception if the method has not been successfully executed.
- It returns the value to the caller.
Q.92. What is the reflection in Java, and why is it useful?
Answer. Reflection in Java is an API that we can use to examine or modify the behavior of methods, classes, interfaces of the program during the runtime. The required classes for reflection are present under the java.lang.reflect package. We can use reflection to get information about Class, Constructors, and Methods, etc.
Java Reflection is powerful, and it can be advantageous. Java Reflection enables us to inspect classes, interfaces, fields, and methods at runtime. We can do it without knowing the names of the classes, methods, at compile time.
Q.93. What is the difference between multitasking and multithreading?
Answer.
| Multitasking | Multithreading |
| The processes share separate memory in multitasking. | There is a separate memory for processes in multithreading. |
| In multitasking, the CPU executes many tasks at a time. | In multithreading, a CPU is provided to execute many threads from a process at a time. |
| In multitasking, processes do not share the same resources. There is a separate allocated resource for each process. | Each process shares the same resources in multithreading. |
| Multitasking is slower as compared to multithreading. | Multithreading is faster as compared to multitasking. |
| The termination of the process takes more time. | The termination of thread takes less time. |
Q.94. What is the tradeoff between using an unordered array versus an ordered array?
Answer. The significant advantage of using an ordered array is that the search time in the ordered array has a time complexity of O(log n). The time complexity of searching in an unordered array is O(n). The drawback of using an ordered array is that the time complexity of insertion operation is O(n). On the other hand, the time complexity of an insertion operation for an unordered array is constant: O(1).
Q.95. Is Java “pass-by-reference” or “pass-by-value”?
Answer. Java is always treated as a pass-by-value. When we pass the value of an object, we are actually passing the reference to it. In Java, all object references are passed by values. It means that a copy of that value will be passed to a method, not the original value.
Q.96. How can you print the content of a multidimensional array in Java?
Answer. We use java.util.Arrays.deepToString(Object[]) method to get a string representation of the content of a multi dimensioned array.
The below example shows how the deepToString() method can print the content of a multidimensional array:
// initializing an object array
Object[][] obj = {
{
"Welcome ",
" to "
},
{
"techvidvan",
".net"
}
};
System.out.println("The string content of the array is:");
System.out.println(Arrays.deepToString(obj));
Output:
The string representation of the array is:
[[Welcome , to ], [techvidvan, .net]]
Project-related Interview Questions for Experienced
- Explain your project along with all the components
- Explain the Architecture of your Java Project
- Versions of different components used
- Which are the biggest challenges you have faced while working on Java project?
- Which is your biggest achievement in the mentioned Java project?
- Did you stuck in a situation where there was no path ahead, how you handled that case?
- Which is your favorite forum to get help while facing issues?
- How you coordinate with the client in case of any issues?
- How you educate your client for the problems which they are not aware of?
- Do you have any experience in pre-sales?
- What were your roles and responsibilities in last Java project?
- Which design pattern did you follow and why?
- Best practices in Java development that you followed?
Conclusion
In this tutorial of Java interview questions for experienced, we covered the advanced interview questions and answers which are frequently asked by the interviewers. We discussed tons of questions and answers that will quickly help you to crack the Java interview.