Machine Learning Algorithms – Hitting the Data Science target with a Ten cent pistol
There are various real-world problems, which Machine Learning tackles. We have several models and Machine Learning algorithms, which can be of great help.
Programmers work with many Machine Learning algorithms, sometimes for a single problem.
Algorithms differ from each other in various aspects. They can differ in terms of efficiency, speed, computation power, etc.
Due to this, programmers can test their data using different Machine Learning algorithms. The algorithm that gives the most accurate results is selected for the project.
There are various categories of algorithms in ML. We have various, supervised and unsupervised learning-based ML algorithms.
Both of these approaches have their significance in the market.
These ML algorithms are used for various aspects. They are used in stock market analysis, cancer prediction, etc.
Companies have now started to work with ML, since a couple of years. They work on various innovative ideas and on other existing ones.
This has expanded and created more opportunities in their businesses.
ML is the field that requires constant learning. So, if you are working on ML, be sure to stay updated.
The reason is many new versions of the older algorithms are being created. So, Machine Learning algorithms are becoming more advanced and efficient to fit user needs.
Now that we know the significance of algorithms in ML, let us have a look at them. These are the top Machine Learning algorithms in the market right now.
Machine Learning Algorithms
Let’s discuss the different types of Machine Learning algorithms in detail.
1. Linear Regression
We should know that regression is a statistical method. It is used in finding relationships between variables.
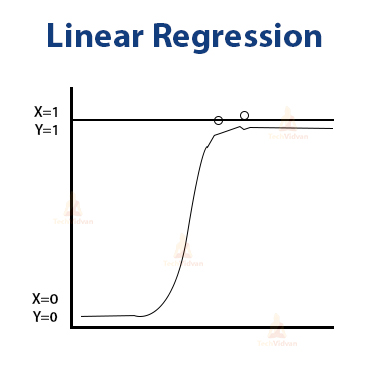
Linear regression is one of the regression-based algorithms in ML. It shows a linear relationship between its variables.
There is a mathematical formula to represent linear regression.
y = m*x + c
This is the representation of a line in mathematics. This means that the data points would be around this line in the graph.
Here, y and x are the axes, m is the slope and c is the constant.
There are two types of Linear regression.
- Simple Linear Regression
- Multiple Linear Regression
Simple linear regression includes only one input variable.
An example can make this easier.
The price of a house can be predicted by using just it’s size. Whereas, multiple linear regression is different.
It takes in various types of input for prediction. Here, other criteria like distance of the house from city, size and many others matter.
In mathematical terms, we can represent linear regression as:
F(x) = b0 + b1x1 + b2x2 + b3x3 +……….+ bkxk
2. Logistic Regression
This is another type of regression. It does not include a linear graph, as the graph is a curve here.
It is a classification-based algorithm and it is used for giving predictions. Here, the graph is a sigmoid function.
Sigmoid means that the graph is S-shaped.
Unlike linear regression, here, the dependent variable is binary in nature. Binary means value is either one or zero, or true or false.
We can have the graph images for better understanding: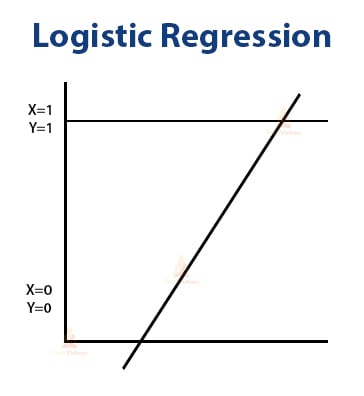
A. Linear Regression
B. Logistic Regression
In linear regression, the values can exceed the limit of 0 and 1.
However, logistic regression is based on probability.
Therefore, the values of logistic regression are always between 0 and 1.
Logistic regression is used in many areas. It can be used in the medical sector.
It can classify cancer as potent or less severe. In addition, it can give uncertain values between 0 and 1.
For example, it can help to predict the resemblance between two objects.
There is a mathematical way to represent logistic regression:
S(x) = 1 / (1 + e-(F(x)))
Here, F(x) is the linear function.
We can also say that the linear function is the logarithmic function of the sigmoid function.
Ln(S(x) / (1 – S(x) ) = F(x)
There are two types of logistic regression:
- Binary valued (Either true or false)
- Multi-linear functions (This is used for finding probability)
Project: Please refer Credit Card Fraud Detection Project for the implementation of logistic regression algorithm.
3. LSTM Algorithm
LSTM or Long Short Term Memory is a great substitute for RNNs or Recurrent Neural Networks.
The reason is RNNs are called feed-forward neural networks.
Feed Forward means that they always tend to move forward. They do not remember any previous information.
If you want to add any new piece of data, it will overwrite the existing data. RNNs have something called Short Term Memory.
This short-term memory prevents them from storing data. In addition, RNNs cannot differentiate between important and less useful information.
This is different in LSTM. They have certain cell states within them.
The information, which we give, passes through these states. These cell states help to separate out useful and non-useful information.
This means that LSTM can remember or forget things. There are also three dependencies in these cells:
- Cell State (previous)
- Hidden State (previous)
- Current Time-Step
These are the states, which help LSTM to remember and make decisions.
We can take an example of the stock market for better understanding. LSTM can be of great use in stock predictions.
As per these states, we can see the previous performance and price of stocks. We can also see the current performance of the stocks.
Therefore, using the previous and present information, we can predict stock prices.
Project: Please refer Image Caption Generator Project for the implementation of the LSTM algorithm.
4. Decision Trees
A decision tree is a tree structure used in ML. This tree helps in many classification techniques.
These trees are used in various algorithms. Like, take CART as an example.
CART or classification and regression technique use decision trees. We have the Gini-index with which we can evaluate the cost function of CART.
Decision trees are generally binary trees. So, each node will only have two possibilities.
It is basically an if-then-else structure that is continuous in nature. Decision trees are based on supervised learning.
They are one of the easiest and efficient to use Machine Learning algorithms.
There are various applications of decision trees that form the base of several ML models. It is mainly used in the medical sector.
So, it can classify the disease as dangerous or mild. This was only one example.
We can use it in any of the fields today, like education, business, etc.
Project: Please refer Parkinson’s Disease Detection Project for the implementation of Decision Trees Algorithm.
5. Random Forest
A random forest is a collection of decision trees. It is a much bigger and robust version of the decision tree.
The reason is we can take in more information than a decision tree. The problem of overfitting in decision trees can be removed here.
They work in a specific way as mentioned. There is a huge training dataset.
This dataset is divided into smaller subparts. The algorithm of random forest creates decision trees for these datasets.
For each decision tree created, we obtain different results. The algorithm does a voting procedure on the results obtained.
The best result obtained from the votes is the final prediction obtained. This reduces the problem of overfitting in one decision tree.
We should also know that the algorithm has a high complexity. It is a big Machine Learning algorithm and takes a lot of time to build.
Also, it takes a lot of computational power to execute. The process can give accurate results, but it is very time-consuming.
6. Reinforcement Learning
Reinforcement learning is a technique mainly used in Deep Learning and neural networks.
This method trains the ML models to make decisions.
This is mostly used in areas like gaming, automated cars, etc. Here models work on the basis of rewards given.
The algorithm gives the model a reward if it achieves the right result.
We can explain the working of RL with an example.
Suppose we are teaching our dog some commands. The commands will be, sit, run, etc.
At first, we will try to emulate the situation ourselves. The dog may respond in many ways.
If it is the right way, we give biscuits to the dog as a reward. So, the next time, if there is a similar situation, the dog might do it more eagerly.
This is how the dog learns.
This is what RL is. The algorithm gives rewards to the model, on getting the right result.
This reward giving is called feedback. There can be different varieties of feedback based on your choice.
There are also negative feedbacks along with positive ones. If the dog does not follow properly, we shout at it.
The shout here gives the dog an idea of not repeating the same thing. This is how many games and self- driving cars are designed.
There are three types of RL algorithms:
- Value-Based
- Policy-Based
- Model-Based
We also have two types of RL models.
These are the Q learning and Markov decision process.
It is a very vast topic to cover and is currently under research.
Companies like Amazon, Google are working on it.
7. K-means Clustering
K-means clustering is an unsupervised learning approach. In this type of Machine Learning algorithm, we analyze clusters of data.
Here, k is the number of centroids in the dataset. Means is the mean or average of these selected k number of centroids.
These centroids can be both real and imaginary based on the data given.
Now, let us try to understand how the algorithm works.
In k-means clustering, the algorithm selects some random points in the dataset. Then it performs iterative operations on these points.
These selected centroids are the starting points of every cluster. These iterations compare each point’s distance with the centroids.
The point gets into the cluster whose centroid is nearest to it. The iterations carry on until all the clusters are formed.
This can be shown in the diagram.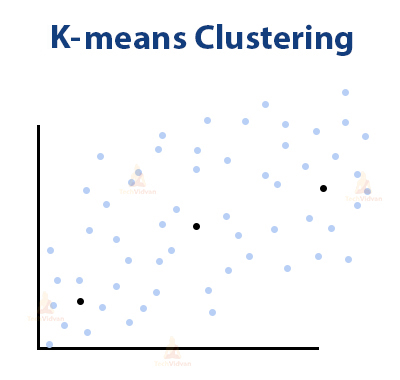
The black dots are the centroids of the clusters. This is before the iterative operations take place.
The algorithm selects three random points from the dataset. When the iteration starts, the points start accumulating around centroids near to them.
After the iteration is complete, the image would look like this one below.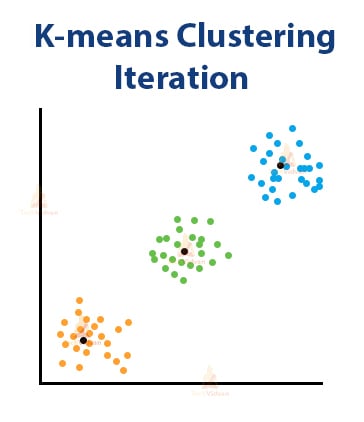
This Machine Learning algorithm is used in many places. It can be used in areas like image classification, market analysis, etc.
There are several disadvantages like:
- It is difficult to use for global datasets.
- Outliers in the dataset can be a problem for the algorithm as they can alter the centroid position.
- The clusters can vary depending on the number of k.
Project: Please refer Customer Segmentation Project for the implementation of K-means clustering algorithm.
8. KNN (K-Nearest Neighbors)
KNN is a supervised learning-based algorithm. It is used in areas like classification and regression.
Still, we use it mainly for classification purposes.
In this, the letter ‘k’ represents an integer. This integer is the number of data points.
The algorithm is not the same as K- means clustering. In this, we have to load the training and testing data at the beginning.
This Machine Learning algorithm is all about calculating the distance between points. There are methods like Euclidean and Manhattan distance methods that we use.
We mostly use Euclidean. We then choose a value of k.
Based on the ‘k’, both the training and testing data are compared. The distance between points of training data is compared with testing data.
The algorithm then sorts the data into increasing order. Then it selects the top k rows.
From this, the understanding is simple. Points closer to the test point are similar.
This is the KNN algorithm. It also uses a lot of computational power.
But it can be really efficient. It is used in banking sectors, speech recognition, etc.
9. ANNs (Artificial Neural Networks)
Artificial Neural Networks form the base of Deep Learning algorithms. These networks work in the same way as a real neuron.
There are two types of networks. Feed Forward and Feed Back.
Feed Forward is unidirectional but Feed Back forms a loop. The networks can also be single or multi-layered neural networks.
Neural Networks form the base of Deep Learning. We use it for designing hardware like GPUs etc.
We know a fair few algorithms of ANN. These are:
- Gradient Descent (used in finding local minima of functions)
- Evolutionary Algorithms (based on natural selection in biology)
- Genetic Algorithms (used for giving rules for a solution and used in inheritance, crossovers, etc.)
10. Naïve Bayes
Naïve Bayes approach is a probability-based ML approach.
It is a mathematical concept about prior and posterior probability. It is a classification- based technique based on Bayes Theorem.
The Bayes theorem helps to calculate the posterior probability. We should know it’s terminologies.
P (A|B) is the posterior probability where P (A) is the class prior to probability, P (B) is the predictor prior probability and P (B|A) is the Likelihood.
The algorithm works as follows.
First, the dataset is analyzed. It generates a feature table for any particular entity.
The algorithm calculates the prior probability of every entity.
After that, the algorithm generates the likelihood table and likelihood is calculated. At the last of everything, the algorithm calculates the posterior probability.
This technique is a classification method. It has several advantages.
It can calculate small datasets with great accuracy. Easy to implement.
The mathematical expression is:
P (C|X) = P (X|C) P(C) / P(X)
Summary
After studying so many Machine Learning algorithms, we can end on a good note.
There are many algorithms, which are under research. However, in this article, we covered the ones that are the most used.
These Machine Learning algorithms are very important. We may understand what they are from this article.
However, these demands a lot of practical work. So, learning to code with these Machine Learning algorithms is highly suggested.
Also, make use of these Machine Learning algorithms in some cool projects.