NLP Techniques in Data Science with Real Life Case Studies
Data is increasing at an alarming rate. A large portion of the data available today is in the form of text. Natural Language Processing is a popular branch of AI which helps Data Science in extracting insights from the textual data. Following this, Industry experts have predicted that there will be a huge demand for Natural Language Processing professionals in the near future. In this tutorial, we will discuss some of the important NLP Techniques used in the field of Data Science.

What is Natural Language Processing?
Natural Language Processing or NLP is a branch that focuses on teaching computers how to read and interpret the text in the same way as humans do. It is a field that is developing methodologies for filling the gap between Data Science and human languages.
Everything we speak or express holds great information and can be useful in making valuable decisions. But extracting this information is not that easy as humans can use a number of languages, words, tones, etc. All these data that we are generating through our conversations, tweets, etc is highly unstructured. The traditional techniques are not capable of extracting insights from this data. But thanks to the advanced technologies like machine learning and NLP that have brought a revolution in the field of Data Science.
Many areas like Healthcare, Finance, Media, Human Resources, etc are using NLP for utilizing the data available in the form of text and speech. Many text and speech recognition applications are built using NLP. For example, personal voice assistants like Siri, Cortana, Alexa, etc.
NLP techniques in Data Science
Let us see some of the most widely used NLP techniques in Data Science.
1. Bag of Words
This model counts the number of words in a piece of text. This model works by generating an occurrence matrix for the sentences. The underlying grammar and the order of words are not considered while generating the matrix.
These occurrences or counts are then fed into a classifier as features.
A compound sentence is a sentence formed with two or main clauses joined by a coordinating conjunction.
A simple sentence is a sentence formed with one main clause.
Now let’s generate the occurrence matrix for this:

This approach is very simple to understand but it has several drawbacks also. This model gives no idea about the semantics and the context in which the words are used. Also, some words like “a” or “the” which appear frequently but are not that important may create noise during analysis. Another problem is that in the above example, the word “then” holds more weight than the word “universe” i.e words are not weighted according to their importance.
To overcome these issues, we use an approach called Term Frequency-Inverse Document Frequency (TF-IDF).
2. Term Frequency-Inverse Document Frequency (TF-IDF)
Term Frequency-Inverse Document Frequency or TF-IDF overcomes the drawbacks of Bag of Words by using a weighting factor. It uses statistics for calculating the importance of a word in a document. Let us understand the statistics of TF-IDF.
TF or Term frequency: It measures the frequency of a word in a document. This is calculated by counting the total number of occurrences of the word and dividing it by the total length of the document.
IDF or Inverse Document Frequency: It measures the importance of a word in a document. For example, words such as is, a, of, etc which occur frequently in the document but they do not hold much importance as they are not adjectives or verbs. Thus this technique assigns a weight to any string according to its importance. It is calculated by taking the log of the total number of documents in the dataset divided by the number of documents containing that particular word (also 1 is added to the denominator so that it is never 0).
TF-IDF: Finally it calculates the importance of any word by multiplying the TF and IDF terms i.e TF*IDF.
Thus the words having more importance are assigned higher weights by using these statistics. This technique is mostly used by search engines for scoring and ranking the relevance of any document according to the given input keywords.
3. Tokenization in NLP
This is one of the NLP techniques that segments the entire text into sentences and words. In other words, we can say that it is a process of dividing the text into segments called tokens. This process discards certain characters like punctuations, hyphens, etc. The main purpose of tokenization is to convert the text into a format that is more convenient for analysis. Let us apply this to an example. The result will be like:

In this case, it was quite simple as we have split into blank spaces, but this will not be the case always. Sometimes splitting into blank spaces may break such words into different tokens that should be considered as one token (for example New York or New Delhi).
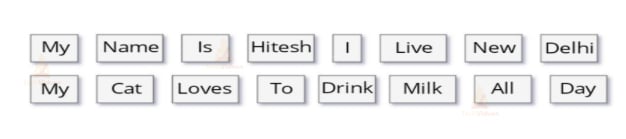
Another problem with tokenization is the removal of punctuations. Sometimes it may lead to complications. For example, in Mr., the period following the abbreviation should be a part of the same token and should not be removed. Because of this, a large number of problems arise while applying tokenization to biomedical text domains having a number of hyphens, parentheses, and punctuations.
4. Stop Words Removal
The objective of Stop Words Removal is similar to tokenization. In this process, the common words which occur most frequently but adds a very little or no value to the result are removed from the text. For example, the common prepositions like and, the, a, etc of the English language. The main purpose behind this is to minimize the noise so that we can focus on the words holding important meaning during the analysis.
Stop words removal can be easily carried out by looking up in a predefined list and removing those words. This helps to free up space and improve performance and processing time. But it should be kept in mind that there is no universal list of the stop words. You can build or generate it using scratch. Another effective approach is to take all the predefined stop words in the beginning and then add new words according to your requirements. Sometimes some important information is lost in this method.
For example, it would be problematic if we discarded words like “not” while performing sentiment analysis. In such cases, you should prefer a list having minimal stop words at first and then add more words later on.
5. Stemming in NLP
The main objective of this NLP techniques is to reduce the words to their root form. This technique works on the principle that certain words having slightly different spellings but nearly the same meaning should be in the same token. Thus, we chop off the affixes of the words for efficient processing. For better understanding, consider the following example.
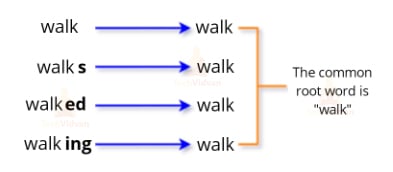
In the above example, all forms refer to the same word “walk”. So it would be better if we map these words to the same token during analysis. But how to decide whether to chop the affix or not. Consider the following example,
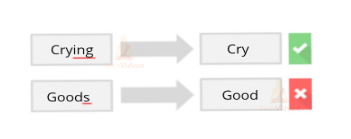
For dealing with such issues, you can refer to some lists containing common affixes and perform stemming accordingly. There are a number of limitations in stemming but on the other hand, it is very efficient in terms of speed and performance.
6. Lemmatization in NLP
Lemmatization has an aim similar to stemming. This NLP technique aims at reducing the inflected forms of a word to their root form and group them together. For example,
- came is converted to come (past tense changed to present tense)
- worst is changed to bad (synonyms to their simpler form)
The aim of stemming and lemmatization is quite similar but the approaches are different.
In Lemmatization, we convert the words into lemma which is the dictionary form of the word. For example,
“Swims”, “swimming” are forms of the word “swim”. So “swim” will be the lemma for these words.
The following image properly indicates the difference between Stemming and Lemmatization.

Lemmatization has the capability to differentiate between words based on their context. For example words like, a bank which refers both to a financial institution and to land alongside a river body. As we have seen that Lemmatization performs better than Stemming but it also requires more computational power than Stemming.
7. Topic Modeling in NLP
Topic Modeling is a technique in NLP that extracts main topics from the text or document. It works on the assumption that each document is a group of topics and each topic is a group of words. We can relate it with the Dimensionality Reduction. Because in this technique also, we reduce the large text into a smaller number of topics.
The technique of Topic Modeling employs in various Data Science applications like Data Analysis, Classification, Recommender systems, etc. One of the popular techniques for Topic Modeling is LDA which stands for Latent Dirichlet Allocation. LDA is an unsupervised technique for finding the appropriate collection of topics in a document. LDA works in the following way:
Firstly the user defines the number of topics a document should have. The algorithm will then divide the document into topics in such a way that the topics should include all the words in the document.
The algorithm then iteratively assigns the words to any topic based on its probability of belonging to that topic and the probability that it can regenerate the document from those topics.
8. Word Embeddings in NLP
It is a technique for representing words of a document in the form of numbers. Its representation should be such that similar words have a similar representation. The modern approaches represent the words as real-valued vectors.
The length of all word vectors is the same but each vector has a different value. The distance between vectors indicates the similarity between them.
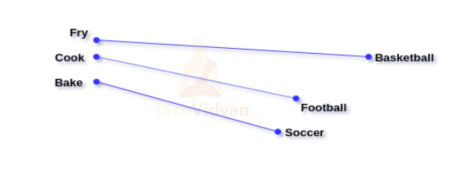
In the above example, the distance between the words fry and cook is less as they are similar while the distance between cook and football is more as they are not similar.
Hope you understood all NLP techniques. Let us now see NLP real life case studies.
Real Life NLP Case Study
Some Examples which shows how businesses are integrating NLP with Data Science for better results:
- In 2015, Uber launched its messenger bot on Facebook Messenger. The aim was to reach more and more customers for collecting more data and Facebook was the best possible way to connect people through social media. This bot helped them in providing a better and personalized customer experience by analyzing the customer data. This bot provided the users with easy and quick access to the service which eventually helped them in gaining more users. The bot also helped them to generate more revenue through advertisements.
- Many e-commerce businesses are using Klevu, a smart search provider based on NLP for providing a better customer experience. This smart search provider automatically learns from the user interactions in the store. It performs various functions like search autocomplete, the addition of relevant contextual synonyms, etc. It also uses the insights gained from the textual data for providing personalized search recommendations.
- In 2016, Mastercard also launched its Chatbot on Facebook Messenger. The aim of this chatbot was to provide various customer support services like an overview of their spending habits, available benefits, etc by analyzing their data. This helped them to provide a better customer experience. This initiative of chatbot also saved their expenses of developing a separate app for customer support.
Summary
So in this tutorial, we have seen the various popular NLP techniques used in Data Science. We have also seen how different companies are using Data Science and NLP for improving their business. These NLP Techniques are very helpful while using NLP in data science.
Do share on Social Medias with your Friends to spread the knowledge!!