Reinforcement Learning Algorithms and Applications
Reinforcement learning is one of the three main types of learning techniques in ML. They are supervised, unsupervised and reinforcement learnings.
For this article, we are going to look at reinforcement learning.
Unlike supervised and unsupervised learnings, reinforcement learning has a feedback type of algorithm. In other words, for every result obtained the algorithm gives feedback to the model under training.
So, in this article, we will look at everything related to reinforcement learning and we might as well see some coding examples for better knowledge.
So, let’s start.
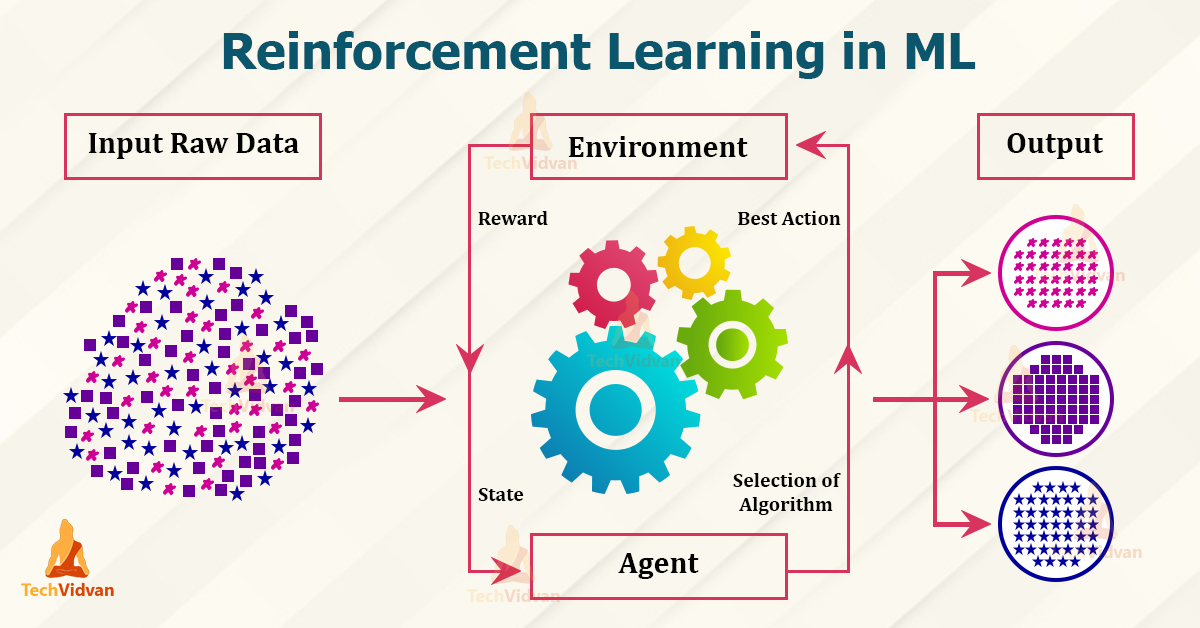
What is Reinforcement Learning?
Reinforcement Learning is a type of learning methodology in ML along with supervised and unsupervised learning. But, when we compare these three, reinforcement learning is a bit different than the other two. Here, we take the concept of giving rewards for every positive result and make that the base of our algorithm.
For an easier explanation, let’s take the example of a dog.
We can train our dog to perform certain actions, of course, it won’t be an easy task. You would order the dog to do certain actions and for every proper execution, you would give a biscuit as a reward. The dog will remember that if it does a certain action, it would get biscuits. This way it will follow the instructions properly next time.
We can take another example, in this case, a human child.
Kids often make mistakes. Adults try to make sure they learn from it and try not to repeat it again. In this case, we can take the concept of feedbacks. If the parents are strict, they will scold the children for any mistakes. This is a negative type of feedback. The child will remember it as if it does a certain wrong action, the parents will scold the kid.
Then there is positive feedback, where the parent might praise them for doing something right. This type of learning is called enforced learning.
Here, we enforce or try to force a correct action in a certain way.
So, in short, reinforcement learning is the type of learning methodology where we give rewards of feedback to the algorithm to learn from and improve future results.
This type of learning is on the many research fields on a global scale, as it is a big help to technologies like AI.
Advantages of Reinforcement Learning
- It can solve higher-order and complex problems. Also, the solutions obtained will be very accurate.
- The reason for its perfection is that it is very similar to the human learning technique.
- This model will undergo a rigorous training process that can take time. This can help to correct any errors.
- Due to it’s learning ability, it can be used with neural networks. This can be termed as deep reinforcement learning.
- Since the model learns constantly, a mistake made earlier would be unlikely to occur in the future.
- Various problem-solving models are possible to build using reinforcement learning.
- When it comes to creating simulators, object detection in automatic cars, robots, etc., reinforcement learning plays a great role in the models.
- The best part is that even when there is no training data, it will learn through the experience it has from processing the training data.
- For various problems, which might seem complex to us, it provides the perfect models to tackle them.
Disadvantages of Reinforcement Learning
- The usage of reinforcement learning models for solving simpler problems won’t be correct. The reason being, the models generally tackle complex problems.
- We will be wasting unnecessary processing power and space by using it for simpler problems.
- We need lots of data to feed the model for computation. Reinforcement Learning models require a lot of training data to develop accurate results.
- This consumes time and lots of computational power.
- When it comes to building models on real-world examples, the maintenance cost is very high.
- Like for building driverless vehicles, robots, we would require a lot of maintenance for both hardware and software.
- Excessive training can lead to overloading of the states of the model. This will result in the model for getting the result.
- This may happen if too much memory space goes out in processing the training data.
Applications of Reinforcement Learning
Reinforcement learning is a vast learning methodology and its concepts can be used with other advanced technologies as well.
Here, we have certain applications, which have an impact in the real world:
1. Reinforcement Learning in Business, Marketing, and Advertising
In money-oriented fields, technology can play a crucial role. Like, here RL models of companies can analyze customer preferences and help in the better advertisement of the products.
We know that business requires proper strategizing. The steps need careful planning for a product or the company to gain profit.
RL here helps to devise proper strategies by analyzing various possibilities and by that; it tries to improve the profit margin in each result. Various multinational companies use these models. Also, the cost of these models is high.
2. Reinforcement Learning in Gaming
One of the prime usages of RL is in gaming. We have various high-end algorithms already existing in the market.
Gaming is a booming industry and is gradually advancing with technology. The games are now becoming more realistic and have many more details for them.
We have environments like PSXLE or PlayStation Reinforcement Learning Environment that focus on providing better gaming environments by modifying the emulators.
We have Deep learning algorithms like AlphaGo, AlphaZero that are gaming algorithms for games like chess, shogi and go.
With these platforms and algorithms, gaming is now more advanced and is helping in creating games, which have countless possibilities.
These can also be helpful in making story-mode games of PlayStation.
3. Reinforcement Learning in Recommendation systems
RL is now a big help in recommendation systems like news, music apps, and web-series apps like Netflix, etc. These apps work as per customer preferences.
In the case of web-series apps like Netflix, the variety of shows that we watch become a list of preferences for the algorithm.
Companies like these have sophisticated recommendation systems. They consider many things like user preference, trending shows, related genres, etc. Then according to these preferences, the model will show you the latest trending shows.
These models are very much cloud-based, so as users, we will use these models in our daily lives through information and entertainment platforms.
4. Reinforcement Learning in Science
AI and ML technologies nowadays have become an important part of the research. There are various fields in science where reinforcement learning can come in handy.
The most talked-about is in atomic science. Both the physics behind atoms and their chemical properties are researched.
Reinforcement learning helps to understand chemical reactions. We can try to have cleaner reactions that yield better products. There can be various combinations of reactions for any molecule or atom. We can understand their bonding patterns with machine learning.
In most of these cases, for having better quality results, we would require deep reinforcement learning. For that, we can use some deep learning algorithms like LSTM.
Types of Reinforcement Learning
1. Positive Reinforcement Learning
In this type of RL, the algorithm receives a type of reward for a certain result. In other words, here we try to add a reward for every good result in order to increase the likelihood of a good result.
We can understand this easily with the help of a good example.
In order to make a child do a certain task like cleaning their rooms or study hard to get marks, some parents often promise them a reward at the end of the task.
Like, the parents promise to give the child something that he or she loves like chocolate. This rather has a good impact as it automatically makes the child work as they think of the reward. In this learning, we are adding a good reward to increase the likelihood of task completion.
This can have good impacts like improvement in performance, sustaining the change for a longer duration, etc., but its negative side could be that too much of RL could cause overloading of states that could impact the results.
2. Negative Reinforcement Learning
This RL Type is a bit different from positive RL. Here, we try to remove something negative in order to improve performance.
We can take the same child-parent example here as well. Some parents punish kids for not cleaning their rooms.
The punishment can be no video games for one week or sometimes a month. To avoid the punishment the kids often work harder or complete the job assigned to them.
We can also take the example of getting late for the office. People often sleep late and get up late. To avoid being late at the office, they try to change their sleep habits.
From these examples, we understand that the algorithm in this case will receive negative feedback. Hence, it would avoid the process that resulted in negative feedback. This also has it’s good impacts like, the behavior toward performing the task would increase. It would force you to provide better results.
The negative impact is that it would only force you to meet the minimum necessary requirement to complete the job.
Algorithms of Reinforcement Learning
There are several algorithms for reinforcement learning. We will look at the ones that we really need to know for the start.
We have certain categories in these algorithms. These are model-based and model-free algorithms.
We further classify them as on-policy or off-policy.
So, in model-based algorithms, we should have a model that would learn from current actions and from state transitions. After some steps, it would not be feasible, as it would have to store all the state and action data in the memory.
Whereas, in model-free algorithms, you do not have to worry about a model that consumes much space. This algorithm works on a trial and error basis, so you don’t need to store the states and actions.
Now, before we understand on and off policies, we need to understand a few mathematical terms.
‘s’ is the state, ‘a’ is action, ‘π’ is the probability.
There is a Q(s,a) function. This function is for predicting and giving future rewards, it does so by learning from the states and actions and giving the next values.
Whereas, ‘π’ here is for the probability to find maximum reward. So, based on this, a policy is an action ‘a’ in state ‘s’.
So, on-policy learning involves Q(s,a) learning from current state and actions, whereas, off-policy involves Q(s,a) learning from random states and actions.
Markov decision process is the root concept of this process. For understanding the use of the Markov process, you should have a good understanding of mathematics. Also, the concept is too vast to cover as it would require a separate article that would cover the whole mathematics and concept of the Markov process.
But for understanding it in this article, we will have a detailed but brief overview. The conclusions that we drew above were from a very famous formula known as the Bellman’s equation.
Also, the formula has a lot of concepts from automatas, like states and actions.
The Markov process also states that the current is very important, as it will help in determining future states. The past information is not necessary when you have a current state that depicts the same thing.
If the conditional probability of future states depend on a current state and not on the entire process before the current state, then that process has Markov property.
Now, based on this let’s get started:
1. Q-learning
Q-learning is an off-policy, model-free RL algorithm. It is off-policy because the algorithm learns from random actions.
For additional information, Q here is Quality, which means the quality of the action that maximizes the reward that the algorithm gets.
When we code using this algorithm, we construct a reward matrix that stores reward at specific moves. Like if the reward is 100, then it will be stored in the matrix at the position where it got 100.
We have a program in this article based on Q-learning algorithm. There we also have added concepts like learning rate (gamma). We also have two value updating methods for Q-learning. They are Policy Iteration and Value Iteration.
Policy iteration handles policy improvement and evaluation, policy improvement is responsible for updating the policy with an action that helps in maximizing the value function. It evaluation predicts value function from the last policy improvement. Value iteration just handles the updating of values.
So, it only updates the value of the Value function. Also, in mathematical terms, we represent Q-learning as:
Q(s,a) = (1-α).Q(s,a) + α.(R + γ.max(Q(S2 ,a)).
Here alpha is the learning rate. Gamma is the discount factor. R is a reward. S2 is the next state.
Q(S2 , a) is the future value. The big expression inside the bracket is the learned value.
2. SARSA
The state-Action-Reward-State-Action algorithm has various similarities with the Q-learning approach. But the difference is that it is an on-policy method, unlike Q-learning, which is an off-policy method.
Q-learning learns through a greedy policy (that means learns from random actions). Whereas SARSA is on-policy, therefore it does not follow the greedy approach and it learns from the current state and actions.
3. Deep Q-network
This uses a neural network instead of the two-dimensional array. The reason is, Q-learning agents and methods can’t estimate and update values for the states that they do not know about.
In other words, if there is a completely new and unknown state, normal Q-learning won’t be able to estimate the value. Also, Q-learning follows a dynamic programming approach using the 2-D arrays.
So, in DQN we are replacing the array with neural networks, for better calculation of values.
Challenges in Reinforcement Learning
There are various challenges that occur during making models in reinforcement learning. We will be looking at them here:
- The reward-based functions need to be designed properly.
- Unspecified reward functions can be too risk-sensitive and objective.
- Limited samples to learn are a problem as these would result in the model producing inadequate results.
- Overloading of states is never a good sign as it may drastically impact the results. This happens when too much RL is done on a problem.
- Too many parameters given to the model may cause delays in results and lead to longer processing and consumption of CPU power.
- The coder should use necessary details to explain policies and actions that are there in the algorithm for the system operators.
Program to understand Reinforcement Learning
This program is an example of the Q-learning algorithm in reinforcement learning.
Step-1:
#Import libraries.
import numpy as np import pylab as plt data_points = [(0,1), (1,2), (1,4), (4,5), (4,6), (4,2), (2,7), (0,3), (3,7), (3,1), (3,2), (6,8), (5,8), (1,6)]
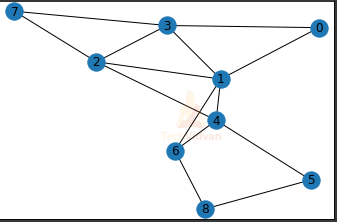
Step-2: Plot datapoints.
goal = 8 import networkx as nx G = nx.Graph() G.add_edges_from(data_points) pos = nx.spring_layout(G) nx.draw_networkx_nodes(G,pos) nx.draw_networkx_edges(G,pos) nx.draw_networkx_labels(G,pos) plt.show()
Step-3: Create reward matrix.
MATRIX_SIZE = 9 R = np.matrix(np.ones(shape=(MATRIX_SIZE, MATRIX_SIZE))) R *= -1
Step-4: Assign points for reaching goal and for not reaching goal.
for point in data_points: print(point) if point[1] == goal: R[point] = 100 else: R[point] = 0 if point[0] == goal: R[point[::-1]] = 100 else: R[point[::-1]] = 0 R[goal,goal] = 100
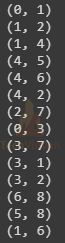
Step-5: Create your model.
Q = np.matrix(np.zeros([MATRIX_SIZE,MATRIX_SIZE])) gamma = 0.8 initial_state = 1
All possible available states for one point.
def possible_actions(state): current_state_row = R[state,] av_act = np.where(current_state_row >= 0)[1] return av_act possible_act = possible_actions(initial_state)
Function will take one state at a time randomly.
def sample_action(possible_actions_range): next_action = int(np.random.choice(possible_act,1)) return next_action action = sample_action(possible_act)
# The update function will update the Q matrix. The model will keep a tally or it will update on how well it does.
#The biggest numbers in the Q matrix will become the most efficient routes.
def update(current_state, action, gamma): max_index = np.where(Q[action,] == np.max(Q[action,]))[1] if max_index.shape[0] > 1: max_index = int(np.random.choice(max_index, size = 1)) else: max_index = int(max_index) max_value = Q[action, max_index]
This here below is the modelling function or formula for this model.
Q[current_state, action] = R[current_state, action] + gamma * max_value
print('max_value', R[current_state, action] + gamma * max_value)
if (np.max(Q) > 0):
return(np.sum(Q/np.max(Q)*100))
else:
return (0)
update(initial_state, action, gamma)
![]()
Step-6: Training.
scores = []
for i in range(800):
current_state = np.random.randint(0, int(Q.shape[0]))
possible_act = possible_actions(current_state)
action = sample_action(possible_act)
score = update(current_state,action,gamma)
scores.append(score)
print ('Score:', str(score))
print("Q matrix after training:")
print(Q/np.max(Q)*100)
The output is very long for this.
Step-7: Testing.
current_state = 0
steps = [current_state]
while current_state != 8:
next_step_index = np.where(Q[current_state,]
== np.max(Q[current_state,]))[1]
if next_step_index.shape[0] > 1:
next_step_index = int(np.random.choice(next_step_index, size = 1))
else:
next_step_index = int(next_step_index)
steps.append(next_step_index)
current_state = next_step_index
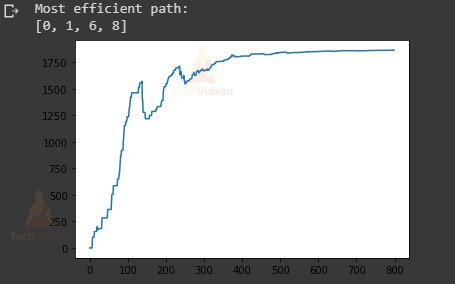
print("Most efficient path:")
print(steps)
plt.plot(scores)
plt.show()
steps = [0, 1, 6, 8]
Reinforcement Learning vs Supervised Learning
1. Supervised Learning
- Supervised learning is more on the passive learning side. Passive means there is a fixed criterion according to which the algorithm will work.
- Here, the model learns from an already provided training data.
- It learns the mapping between the inputs and the outputs. Using that knowledge, it calculates future outputs.
- The input data in the training dataset are somewhat independent.
- For example, if data is about images of cats, then all images will be different. But the algorithm would classify them under the same category.
- Supervised Learning has a classification and regression-based approach to solving problems.
- The data here is labelled and the algorithm maps the labelled inputs with the known outputs.
2. Reinforcement Learning
- Reinforcement learning is more on the active learning side. Active learning means that there are no fixed criteria as per which, the algorithm would work.
- Here, there is no predefined or labelled data. Also, the algorithm does not map the inputs and outputs but, it uses more like a trial and error approach to learning.
- It is more closer to human learning and is more preferable for artificial intelligence models.
- It has a reward-based system for its models to solve problems.
- There is no external supervision, unlike supervised learning.
- Also, an agent here interacts with the environment and learns by performing actions and learning from the rewards earned and the mistakes committed.
Conclusion
From this article, we can conclude that Reinforcement learning is indeed a very important part of ML and AI. The algorithms of RL come in use both as normal and also along with deep learning. Due to its human-like learning approach, it is very helpful in research, and also, it is helpful in making automated robots, simulators, etc.
We also discussed some algorithms and applications regarding this. But, remember that there are actually many more of these out there, we have just covered the ones that are really necessary when it comes to learning RL.
So, a suggestion would be if anyone is trying to study this in terms of research, also try to understand the mathematics behind it.
We also understood the difference between Supervised Learning and Reinforcement Learning. Also, we covered some of the challenges faced in RL.