Supervised Learning Algorithm in Machine Learning
In this article, we will discuss a type of ML learning method known as supervised learning. Unlike, unsupervised learning, supervised learning is more widely used. We will now learn about supervised learning.
So now, let’s start.
What is Supervised Learning
Supervised learning, as we know is one of the most common types of ML learning methodology. The concept of this learning focuses on labelling of training data.
Unlike unsupervised learning, the model first learns from the given training data. The training data contains different patterns, which the model will learn. In other words, the outputs are already available. But, for a collection of data, various outputs are there.
Supervising here means helping out the model to predict the right things. The data will contain inputs with corresponding outputs. This has hidden patterns in it. The algorithm will learn these patterns and will try to apply the same knowledge to unseen data. The aim is to predict future values.
Mathematically, supervised learning can be shown as a linear function, i.e., y=f(x).
Let’s take a real-life example to understand this.
House Price prediction is a good example. Let’s say you bought a house in 2013.
You bought it for supposing Rs. 1000 per square foot. It is 2020 now and you want to predict the price of your house square foot.The real estate price is increasing at Rs. 500 per year in your area. Now you want to predict the value of the present. The data is present in front of us. The model will train itself with the training data.
The pattern is Rs. 500 increase per year. By, learning this pattern and calculating the amounts. It will present to you the price as the predicted output.
Also, the thing with supervised learning is that labelling of training data happens. The labels for this problem would be price and year.
This is different from unsupervised learning as there is no label for the data and the model would have to learn and execute from scratch.
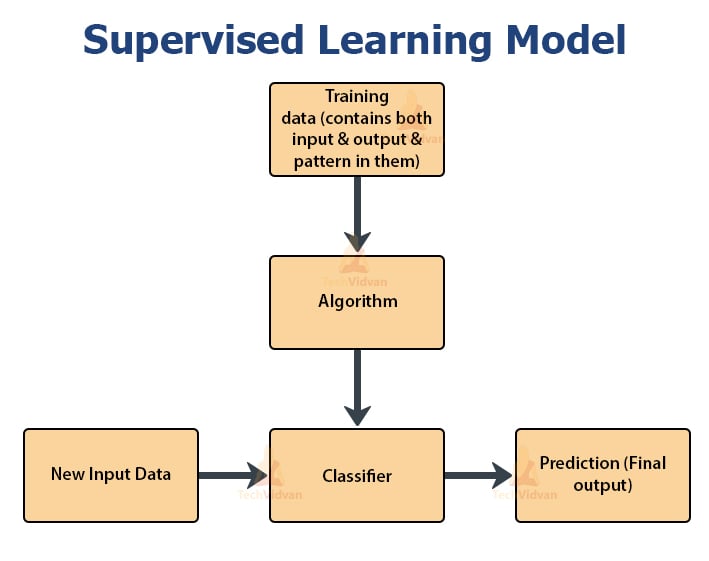
The above flowchart is about supervised learning.
Advantages of Supervised Learning
1. This type of learning is easy to understand. It is the most common type of learning method. For, learning ML, people should start by practicing supervised learning.
2. The training data is only necessary for training the model. Since it is large it occupies a lot of space. But, it’s removed from the memory as it is of no importance after training is complete.
3. We would already know the number of classes in the data.
4. After training, the model would for which specific data the output needs to be predicted as all the data in the collection is not important.
5. It is very helpful in solving real-world computational problems.
6. This learning method can also help the model to learn from previous experiences and to improve its accuracy in prediction.
Disadvantages of Supervised Machine Learning
1. It’s performances are limited to the fact that it can’t handle complex problems in ML.
2. It cannot create labels of its own. This means that, it cannot discover data on its own like unsupervised learning.
3. If we enter new data, it has to be from any of the given classes only. If you enter watermelon data in a collection of apples and oranges, it might classify the watermelon into one of these classes, which won’t be right.
4. It would require a good computer with quality processors to train a supervised learning-based model. It requires high computation power, which not all PC’s might have.
Supervised Learning Algorithms
There are various types of ML algorithms, which we will now study.
a. Linear Regression in ML
It is an ML algorithm, which includes modelling with the help of a dependent variable. As the name suggests, this is a linear model. The format of the projection for this model is Y= ax+b.
Linear regression is an algorithm, which helps us to understand the relationship between two variables.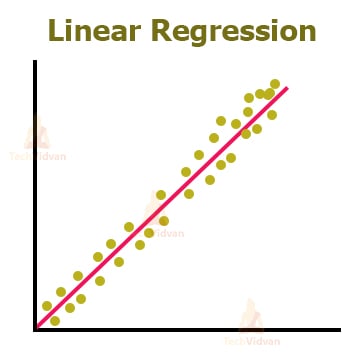
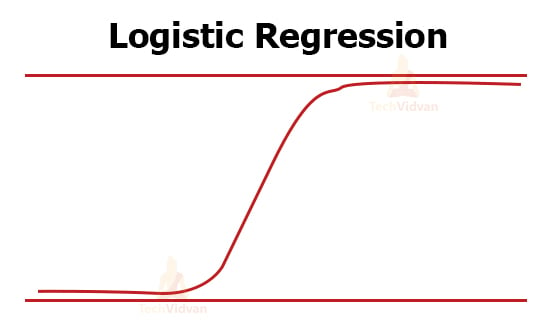
b. Logistics Regression in ML
This type of regression helps us to understand the relationship between one binary dependent variable and an independent variable. This is not a linear relation; it is actually a logarithmic relation.
It is shown as y = ln(P/(1-P)).
The graph for this is S-shaped.
c. Decision Trees in ML
Decision trees are binary trees, which help in the classification, which is a type of supervised learning approach. It might have higher complexity depending on the number of leaves and nodes the tree has. This tree is useful in ‘yes or no’ and ‘if and then’ situations.
d. K-nearest neighbors in ML
This method helps to find in which class does a point belongs using distance. Here, k is the number of points to measure with. If you choose k=3, then the point which you want to classify will be measured with three of it’s nearest neighbors. The point gets classified in the class of which the majority of neighbors are part of.
e. Random Forests in ML
Random forest is a huge collection of decision trees. So, for a situation, there are many possible outcomes that the random forest helps us to see. It is different from a decision tree (as decision trees are always binary and they a single unit) as it has multiple trees.
This algorithm helps to find new patterns and possibilities for anything as the collection of trees helps in analyzing data in many ways. It has a more complex algorithm than a decision tree.
Hence, it would consume a lot more computational power.
f. SVM in ML
SVM or Support Vector Machines are also very popular algorithms used in supervised learning. They help to classify and analyze the data with the help of a hyperplane. The hyperplane is a line or a plane, which divides the data points into two separate categories. The aim is to find an optimal plane, which divides both datapoints.
By maximizing the margin of the hyperplane, we increase the distance between the data points on either side. This is done up to the point where datapoints are distinct from each other. For determining the margins of the hyperplane, support vectors (data points that appear to lie on the plane or are close to it) are necessary.
g. ANN
ANN or Artificial Neural Networks come under modern-day deep learning. In this, we study algorithms that involve neural networks.
Neural networks are very helpful in processing complex problems and in finding more hidden patterns efficiently. They have three layers namely the input layer, hidden layer, and output layer.
The input layer takes the data, the hidden layer has multiple patterns and layers that process the data and analyze the best result. Then comes the output layer.
This concept was created by keeping in mind the functioning of the real neuron. So, that is why it is called an artificial neural network. It is quite significant in modern research and has great potential ahead.
Types of Supervised Learning in ML
There are only two types of supervised learning approaches. Every algorithm comes under these two methodologies.
1. Classification
Classification is a technique with which we can affiliate data under certain labels. We can train algorithms and models to classify data under different classes.
For example, if you have data of fruits consisting of apples and oranges, your model will learn from the data about the specifications of the fruits.
The next time you enter new data, the model will compare your data and then classify it under either class. There are two types of classifications:
a. Binomial Classification
It classifies data under two classes. This happens in decision trees and in simpler data where there are only two types of data.
b. Multi-Class Classification
It classifies data under more than two classes. This means there is a lot of data and many possibilities. This happens in random forests.
2. Regression
Regression helps us to understand the relationship between various data points and helps us to find hidden patterns among the data.
We have both dependent and independent variables in this case which can help us to understand the relation with the help of graphical representations.
There are many types of regression, but we know the two main ones:
a. Linear Regression
b. Logistics Regression
We have already discussed both of these above.
Supervised Machine Learning Applications
a. It is useful for the prediction of stock markets. It can accurately predict the prices of the stock data by analyzing the pattern of previous data. We can make use of various algorithms for predicting the stock market.
For example, let’s take neural networks. In neural networks also, let us take LSTM or long short-term memory.
This algorithm is actually a type of RNN. But, while processing the data, it will remember the significant output and it will forget the unimportant outcome. This algorithm trains under the training data. For various patterns, the neural network trains itself. It ensures more accuracy by going back and forth and removing unimportant data.
b. It can find patterns in biometrics. It is great for adding fingerprint sensors. Also, eye scanners, eye-lobe scanners come under biometrics. This contains the entire individual’s necessary information. This mainly comes under security providing.
Most smartphones today have this as facial recognition technology.
c. Speech Recognition is one of the major applications of supervised learning. This too can come under security, especially high-level security where you have to undergo several rounds of screening.
Also, we can use it on our smartphones. The voice assistant technology uses this.
For example, SIRI, Alexa, Google Assistant. These use the speech recognition algorithm to remember your voice and match it when you speak. They can assist you with anything in your smartphone.
Also, these assistants come as separate devices too; you can connect your other electronics with Bluetooth if you want to activate them using the assistant.
d. Supervised learning also helps in search history optimization. If you search for something once, the next time you search it, the browser will try to provide much better results. It uses your search history as input data and improves its accuracy of searching with that.
For example, google search.
e. Spam detection is also a very important application. If there are any spam emails, it can help you to block such emails by classifying them as spam. It may even block them from sight. Its main purpose is to block fake things.
f. Object detection is also now becoming a thing with research. Technologies such as raspberry pi are also working on this. It also uses computer vision.
Use Cases of Supervised Learning
a. Security
One of the primary concerns of today’s era is proper data security. On top of that, there is more fear when it comes to the security of monetary credentials like a credit card, bank account number, etc.
With ML techniques, various big IT industries are now investing in newer and more powerful algorithms to tackle problems like anomaly detection, fraud detection in credit cards, etc. They are also helping by creating algorithms for spam filtering, blocking malicious links, emails, etc.
Various supervised learning methods and algorithms are very helpful in certain cases.
b. Marketing and business
There is a lot when it comes to marketing and business. Especially, when the growth of internet is exponential, the number of users gradually increases. This is a clear marketing opportunity for all companies globally to advertise their products.
We have major online retailers like Amazon, Walmart, Flipkart etc.
This is just an example of how online marketing works; hence, we have taken online retailers as an example.
So companies like amazon have a recommendation system. This system helps to analyze the user preference using the search history. Based on that it will start to pop miniature ad feeds of the product on whichever webpage you are browsing. This is online advertising.
Supervised Learning is useful in recommendation systems to analyze user preference. There are many other ML concepts like sentiment analysis, time series analysis, etc., which are used in online marketing.
Conclusion
In this article, we looked at what supervised learning is. We looked at the overall structure of how it exactly works through examples and diagrams. Research and other technically innovative fields are a great area for supervised learning. It is essential as it provides us with a basic understanding of ML.
It is also preferred to teach supervised learning thoroughly as it holds many basic concepts and it’s easy to learn as well.