Types of Machine Learning – Supervised, Unsupervised, Reinforcement
Machine Learning is a very vast subject and every individual field in ML is an area of research in itself. The subject is expanding at a rapid rate due to new areas of studies constantly coming forward. In this article, we will be looking at those Types of Machine Learning and we will learn about each one of them.
So, let’s start learning right away.
Types of Machine Learning
Here, we will discuss the four basic types of learning that we are all familiar with. This is just a recap on what we studied at the very beginning.
1. Supervised Learning Method
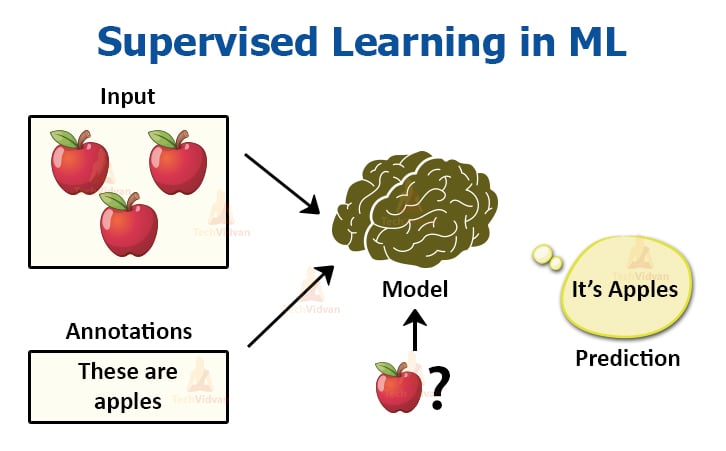
In supervised learning, we require the help of previously collected data in order to train our models. A model based on supervised learning would require both previous data and the previous results as input. By training with this data, the model helps in predicting results that are more accurate.
Also, the data, which we use as input data, is also labelled in this case.
If an algorithm has to differentiate between fruits, the data has to be labelled or classified for different fruits in the collection. The data is divided into classes in supervised learning.
Supervised learning has methods like classification, regression, naïve bayes theorem, SVM, KNN, decision tree, etc.
2. Unsupervised Learning Method
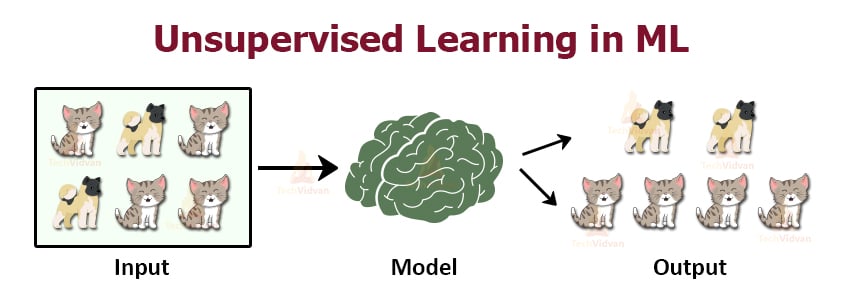
Unsupervised learning needs no previous data as input. It is the method that allows the model to learn on its own using the data, which you give. Here, the data is not labelled, but the algorithm helps the model in forming clusters of similar types of data.
For example, if we have the data of dogs and cats, the model will process and train itself with the data. Since it has no previous experience of the data, it will form clusters based on similarities of features.
Features the same as the dog will end up in one cluster, and the same goes for a cat. In unsupervised learning, we have a clustering method. We have studied algorithms like K-means clustering in the previous articles.
We study various mathematical concepts like Euclidean distance, Manhattan distance in this as well.
3. Semi-supervised Learning Method
This is a combination of supervised and unsupervised learning. This method helps to reduce the shortcomings of both the above learning methods.
In supervised learning, labelling of data is manual work and is very costly as data is huge. In unsupervised learning, the areas of application are very limited. To reduce these problems, semi-supervised learning is used.
In this, the model first trains under unsupervised learning. This ensures that most of the unlabeled data divide into clusters. For the remaining unlabeled data, the generation of labels takes place and classification carries with ease. This technique is very useful in areas like speech recognition and analysis, protein classification, text classification, etc. This is a type of hybrid learning problem.
4. Reinforcement Learning Method
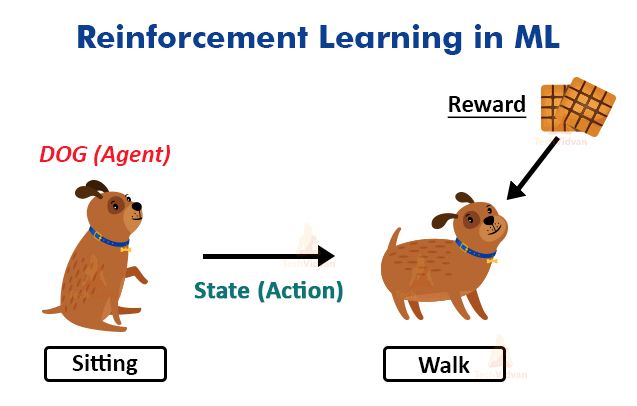
Reinforcement Learning is enforcing models to learn how to make decisions. This type of learning is very awesome to learn and is one of the most researched fields in ML. The algorithm of this method helps to make the model learn based on feedback.
Let’s elaborate on an example.
Let’s say you have a dog and you are trying to train your dog to sit. You would give certain instructions to the dog to try to make it learn. If the dog executes the instruction perfectly, it would get a biscuit as a reward. If not, it would not get anything. The dog learns from this after some tries that it would get a biscuit if it sits.
This is what the gist of reinforcement learning is. The reward here is the feedback received by the dog for sitting. This algorithm has various applications in real life.
It is helpful in making self-driving cars. It also helps in various types of simulations. These were the four most popular methods of ML.
Some More Types of Machine Learning
We have already seen the four most sought after learning methods. Now, based on them, we will see some other popular learning methods.
1. Self-Supervised Learning
You can call it a more advanced version of unsupervised learning which requires supervisory data along with it. Only in this case, the labelling of the data is not done by humans. The model itself extracts and labels the data. It does so with the help of the embedded metadata as supervisory data.
We can understand this from cats’ and dogs’ data. The algorithm gives high emphasis to the position of rectangles of the images. It compares the position of rectangles with that of another image. It uses spatial context as supervisory data for this case and has a very wide range of applications and is very futuristic.
This is very similar to supervised, unsupervised, and semi-supervised learning methods. This makes it a hybrid learning method.
2. Multiple Instance Learning
Multiple Instance Learning or MIL is another variation of supervised learning. Here, the training data isn’t labelled individually, it is nicely arranged in bags.
An arranged set of training data is called bags and the entire bag is labelled. This is a weaker but an interesting form of supervised learning method.
If one entity is fitted with the result, it’s entire bag is given positive. But if it does not fit, the entire bag equates to negative. The goal of this method is to classify unseen bags based on labelled bags. There are some algorithms like diverse density, citation knn, SVM using MIL, etc.
This method helps in areas like computer vision. This model possesses some challenges, but it is still under research and does not have that many applications. It is also a type of hybrid learning.
3. Inductive Learning
Inductive learning involves the creation of a generalized rule for all the data given to the algorithm. In this, we have data as input and the results as output; we have to find the relation between the inputs and outputs.
This can be very complex depending on the data. But, it is an effective method used in ML and used in various fields of ML like facial recognition technology, disease cure, and diagnosis, etc. It uses a bottom-up approach.
This algorithm is crucial as it gives us a relation between data that has a use for future references. It’s used when human expertise doesn’t work when the outputs are varying etc. In short, we can say that in inductive learning, we generalize conclusions from given facts. For example,
a. Apple is a fruit.
b. Apple tastes sweet.
Conclusion: All fruits taste sweet.
This area of ML is still under research as there are many suggestions for improvements regarding the algorithm’s efficiency and speed. Another term for the field is inductive reasoning. It’s the same as supervised learning.
4. Deductive Learning
Just like Inductive reasoning, deductive learning or reasoning is another form of reasoning. In reality, the reasoning is an AI concept and both inductive and deductive learnings are part of it.
Unlike inductive learning, which is based on the generalization of specific facts, deductive learning uses the already available facts and information in order to give a valid conclusion. It uses a top-down approach.
The one major thing to note is that in deductive learning, the results are certain i.e, it is either yes or no. Whereas it’s probability-based on inductive learning i.e, it can range from strong to weak.
Since, deductive reasoning works on pre-available logical facts, let’s have a look.
a. All carnivores eat meat.
b. Lion is a carnivore.
Conclusion: – Lion eats meat.
5. Transductive Learning
In transductive learning, both the training and testing data are pre-analyzed. The knowledge gained from these datasets is the one that is useful.
The model tries to predict the labels for testing datasets after learning from the training dataset. The patterns and the learning process are very helpful while creating labels. This type of learning is mainly used in TSVM or transductive SVM and also some LPAs or Label propagation algorithm.
One of the main differences between transductive and inductive learning is that in inductive learning, the model only works with the training data. Now, the trained model faces a new challenge. It has to run on a completely new dataset, which the model has never encountered before.
Inductive learning has predictive models. In the case of a new data point, it predicts the point instantly. Whereas in transductive learning, the model analyses both training, and testing data and it doesn’t have a predictive model.
When a new data point arrives, it re-runs and re-trains the entire model. This is very costly and time-consuming.
6. Multi-task learning
Many organizations are currently working on this type of learning because it emphasizes a model to be able to perform multiple tasks at the same time without any problem. It is of great use in deep learning and neural network technology as this is quite useful there.
This type of learning helps in NLP, voice recognition, etc. It helps in predictions as well as it helps to get better accuracy in finding results. It can also help in the production of multiprocessor technologies.
7. Active Learning
It is a type of semi-supervised learning approach. In this, we build a powerful classifier to process the data. We also have to keep in mind that the dataset needs to consist of only valuable data points and not any unwanted data.
As size of the dataset can alter processing speed. This is better than passive learning which includes processing larger datasets with more range of data. These also include unwanted data. To reduce this, active learning selects the data points based on certain instances.
For example, if you want to predict heart ailments. The criteria are to predict heart ailments in patients above the age of 50. In the passive method, all patients will undergo checking and the data is then analyzed after that.
But, in an active method, we will create an instance where we say, heart ailments in patients above 50 years of age who eat food with high cholesterol.
That way, it gets easier to classify and segregate the data. This is what active learning is about.
Conclusion
By studying all these algorithms and learning methods, we can conclude this article. In this article, we had a quick overview of the four most sought after learning methods. We then studied the newer learning methods that are now under research.
Knowing these learning methodologies is very important as they can help us immensely while working on future ML problems or while studying some new algorithms.