Unsupervised Learning – Machine Learning Algorithms
In this article, we will be starting with unsupervised learning.
As we know, unsupervised learning is an important aspect of ML. This learning might have few applications, but the concept of the applications is very useful. Even though we might not get that many applications of unsupervised learning, it is still important to learn about it.
For this article, we will be looking at what unsupervised learning is, what are the methods and algorithms related to it, and how can we improve the algorithm’s shortcomings.
So, let’s begin.
What is Unsupervised Learning?
Unsupervised learning is a learning methodology in ML. Unlike its other variant (supervised learning), here we do not label the data with which we want to train the model. Labelling the data means to classify the data into different categories. This labelling mainly takes place in supervised learning. But, in unsupervised learning, there is no labelling.
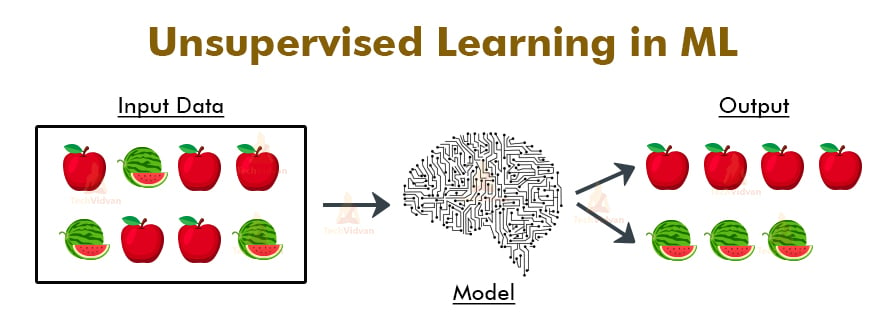
The model learns through training itself from the data. To understand it’s working let’s take an example and also an algorithm based on unsupervised learning. In this case, we will use the clustering algorithm. This algorithm helps to form clusters of similar data.
So, let’s take data of apples and watermelons mixed up together. The aim is to make the model learn to differentiate between an apple and a watermelon. The algorithm will classify based on shape, size, and colour.
Apple is small in size, round in shape, and red in colour. Whereas watermelon is large in size, ellipsoidal in shape, and greenish in colour. The model will learn and differentiate based on these credentials. The data-points similar to that of an apple will form one cluster. The same will be for watermelon and it will form a different cluster.
This is what unsupervised learning does. It trains the model by making it learn about the data and work on it from the very start.
Also, after the data is clustered and classified, we can easily label the data in separate categories as the data is already solved now.
Advantages of Unsupervised Learning
There are some reasons why we sometimes choose unsupervised learning in place of supervised learning. Here are some of the advantages:
- Labeling of data demands a lot of manual work and expenses. Unsupervised learning solves the problem by learning the data and classifying it without any labels.
- The labels can be added after the data has been classified which is much easier.
- It is very helpful in finding patterns in data, which are not possible to find using normal methods.
- Dimensionality reduction can be easily accomplished using unsupervised learning.
- This is the perfect tool for data scientists, as unsupervised learning can help to understand raw data.
- We can also find up to what degree the data are similar. This can be accomplished with probabilistic methods.
- This type of learning is similar to human intelligence in some way as the model learns slowly and then calculates the result.
Disadvantages of Unsupervised Learning
Now, let’s have a look at some cons of unsupervised learning algorithm:
- The result might be less accurate as we do not have any input data to train from.
- The model is learning from raw data without any prior knowledge.
- It is also a time-consuming process. The learning phase of the algorithm might take a lot of time, as it analyses and calculates all possibilities.
- For some projects involving live data, it might require continuous feeding of data to the model, which will result in both inaccurate and time-consuming results.
- The more the features, the more the complexity increases.
Algorithms related to Unsupervised Machine Learning
Now let’s look at some algorithms which are based on unsupervised learning.
As we discussed, the algorithms and applications might be limited, but they are of extreme significance.
a. K-means Clustering in ML
K means is a clustering algorithm type. It is an iterative clustering approach. This algorithm states that similar data points should be in close proximity. For this we will select the value of k. The value of k is the number of data points. Now, select centroids in the data set. The centroids will act as data accumulation areas.
Take each centroid and measure the distance of k datapoints. The once near the centroid will get clustered. For this, we use methods like Euclidean distance as measuring options.
b. KNN Clustering
KNN or K-nearest neighbor is also a clustering-based algorithm. This method is used for those datapoints which can be selected in any class or for those who don’t have any class or cluster assigned. The algorithm starts with the selection of the point which we want to work on. Then we have to select the value of k. K will be the number of points around the selected points. These points can belong to multiple clusters.
Now, measure the distance of each point with the test point using Euclidean or Manhattan distance measuring techniques. Sort the results in ascending order.
The test point will end up in the cluster whose points were the closest to the test point.
c. Hierarchical Clustering in ML
In this, we form multiple clusters, which are distinct to each other, but the contents inside the cluster are highly similar to each other. For this, we would use the distance matrix for calculation purposes, and then for the visual representation of the clusters, a dendrogram would be formed.
The algorithm works in a specific way.
The algorithm would treat each observation as a separate cluster. Then it would find two most similar clusters and merge them. This step goes on iteratively until all the clusters merge together. The main result is the dendrogram. It would show the similarity between the clusters. There are some other methods of finding similarity as well like distance criteria and linkage criteria.
The process of merging the clusters is agglomerative clustering. These were some of the main algorithms or types of unsupervised learning that we have discussed now.
Applications of Unsupervised Machine Learning Algorithm
As stated in the above pages of the article, the applications for this learning are quite limited.
But still, we will look at the ones which are widely popular.
- It is mainly useful in fraud detection in credit cards.
- Useful for genome analyzing.
- Useful in data preprocessing.
Better Learning Methods than Unsupervised Learning
Semi-supervised learning might be a good substitute for unsupervised learning. It is a combination of both supervised and unsupervised learnings. The main advantage of this type of learning is that it reduces the errors of both supervised and unsupervised learnings.
For instance, it will only cluster the unlabeled data which is possible to cluster and the result will be classified automatically after being labeled. This consumes less computational power and is less time-consuming.
Conclusion
Finally, in this article, we learned about what unsupervised learning is, how it works, what are its pros and cons, it’s types and applications.
At last, we also looked at the better substitute for unsupervised learning which is of-course semi-supervised learning. This learning methodology has great significance. Although it does not have that many applications, it can be very helpful in research.
It is very useful especially for data scientists who analyze data constantly.