Apache Sqoop Architecture and Internal Working
Apache Sqoop is used for data transfer between the Hadoop framework and the Relational Database. In this Sqoop architecture article, you will study Sqoop Architecture in detail. The article gives you the complete guide of the Sqoop architecture.
After reading this article, you will learn how Sqoop works. Before learning Sqoop architecture, first, have a short introduction about Sqoop to brush up your Knowledge.
Sqoop Introduction
It is exciting to know the reason behind the name Sqoop. The Sqoop got its name from “SQL to Hadoop & Hadoop to SQL”.
Apache Sqoop is a tool by Apache Software Foundation for transferring data between the Hadoop and the relational database servers like MySQL, SQLite, Oracle RDB, Teradata, Postgres, Netezza, and many more.
In simple words, Sqoop is useful for importing data from relational databases such as Oracle, MySQL to Hadoop HDFS, and for exporting data from HDFS to relational databases.
Apache Sqoop can transfer bulkier data efficiently between the Hadoop system and the external data stores like enterprise data warehouses, RDBMS, etc.
Let us now explore Sqoop architecture and its working.
Sqoop Architecture and Working
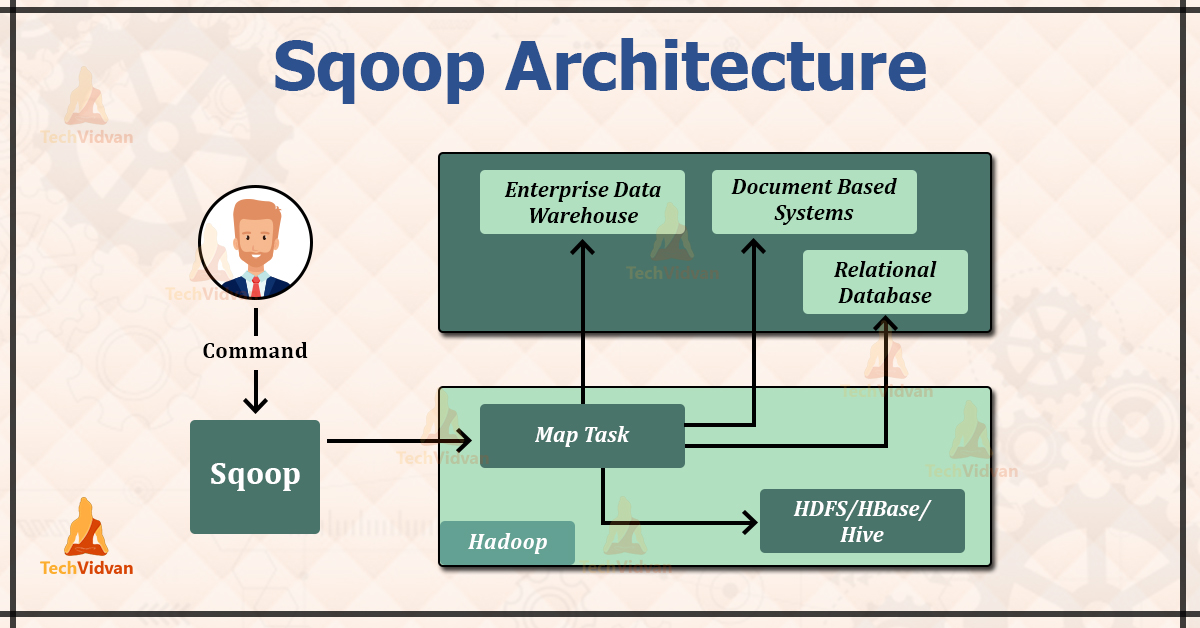
The above image depicts Sqoop Architecture.
Apache Sqoop provides the command-line interface to its end users. We can also access Sqoop via Java APIs. The Sqoop commands which are submitted by the end-user are read and parsed by the Sqoop. The Sqoop launches the Hadoop Map only job for importing or exporting data.
No Reduce job is launched because the Reduce phase is needed only when the aggregations are performed. Apache Sqoop just imports and exports data, and hence it does not perform any aggregations due to which we don’t require a Reduce phase.
Apache Sqoop parses the arguments which are provided in the command line and launches the Map only job. The Map only job launches multiple mappers depending on the number defined by the user in the command line.
For import, each mapper task is assigned with the part of data that is to be imported on the basis of the key defined in a command line. For getting higher performance, Sqoop distributes input data equally amongst all the mappers.
Each mapper then creates a connection with the database by using the JDBC and fetches part of the data assigned by the Sqoop. They then write those data into HDFS or HBase or Hive on the basis of the option provided in the command line.
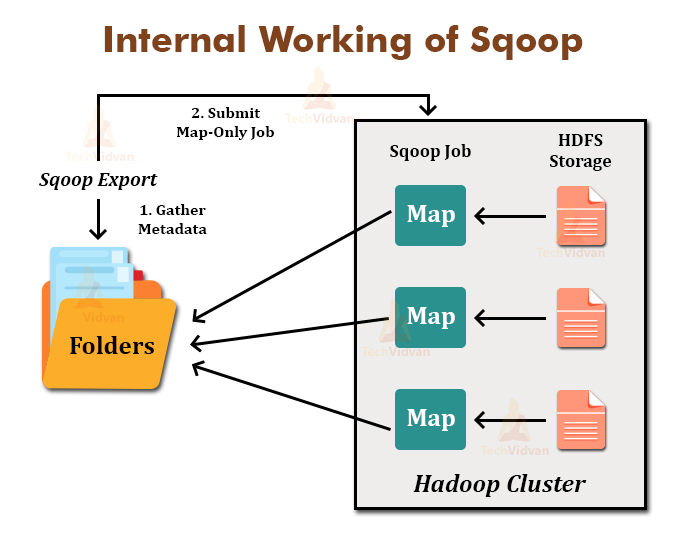
Sqoop Export also works in the same way. The Sqoop Export tool exports the set of files from the Hadoop Distributed File System back to the Relational Database. The files which are given as an input to the Sqoop contain records. These records are called as rows in a table.
When the user submits it Job, then it is mapped into the Map Tasks that bring chunks of data from the Hadoop Distributed File System. These chunks are then exported to any structured data destination.
By combining all these chunks of data, the user receives the entire data at destination, which is generally an RDBMS such as MYSQL, SQL Server, Oracle, etc.
Summary
In short, we can say that Apache Sqoop is a tool for transferring data between RDBMS and Hadoop. The article had clearly explained the Sqoop architecture and working in detail.
I hope now you understand Sqoop architecture and working. If you have any doubts or queries, feel free to share it with us in the comment box.