Data Manipulation in R – Alter, Sample, Reduce & Elaborate Datasets
In this R tutorial of TechVidvan’s R tutorial series, we will learn the basics of data manipulation. We shall study the sort() and the order() functions that help in sorting or ordering the data according to desired specifications. Also, we will take a look at the different ways of making a subset of given data. Then, we shall study the working and uses of the sample function. Next up will be merging datasets, where we will look at the cbind(), rbind() and the merge() functions. Finally, we shall then study the apply() family of functions.
As you can see, we have a packed schedule ahead of us. So, let’s get started.
Data Manipulation in R

In a data analysis process, the data has to be altered, sampled, reduced or elaborated. Such actions are called data manipulation. Data has to be manipulated many times during any kind of analysis process. Performing mathematical calculations on a column or making a subset of the data for a predictive sample analysis everything counts as manipulating the data.
Sorting and Ordering the Data
The sort() and the order() functions are included in the base package of R and are used to sort or order the data in the desired order. Let’s take a look at these functions one-by-one.
1. The sort function
The sort() function sorts the elements of a vector or a factor in increasing or decreasing order. The syntax of the sort function is:
Code:
Sort(x, decreasing = FALSE, na.last = NA, . . .)
Here,
xis the input vector or factor that has to be sorted.decreasingis a boolean that controls whether the input vector or factor is to be sorted in decreasing order (when set toTRUE) or in increasing order (when set toFALSE).na.lastis an argument that controls the treatment of theNAvalues present inside the input vector/factor. Ifna.lastis set asTRUE, then theNAvalues are put at the last. If it is set asFALSE, then theNAvalues are put first. Finally, if it is set asNA, then theNAvalues are removed.
Let us take a look at an example of the sort function:
Code:
sort(c(3,16,34,77,29,95,24,47,92,64,43), decreasing = FALSE)
Output:
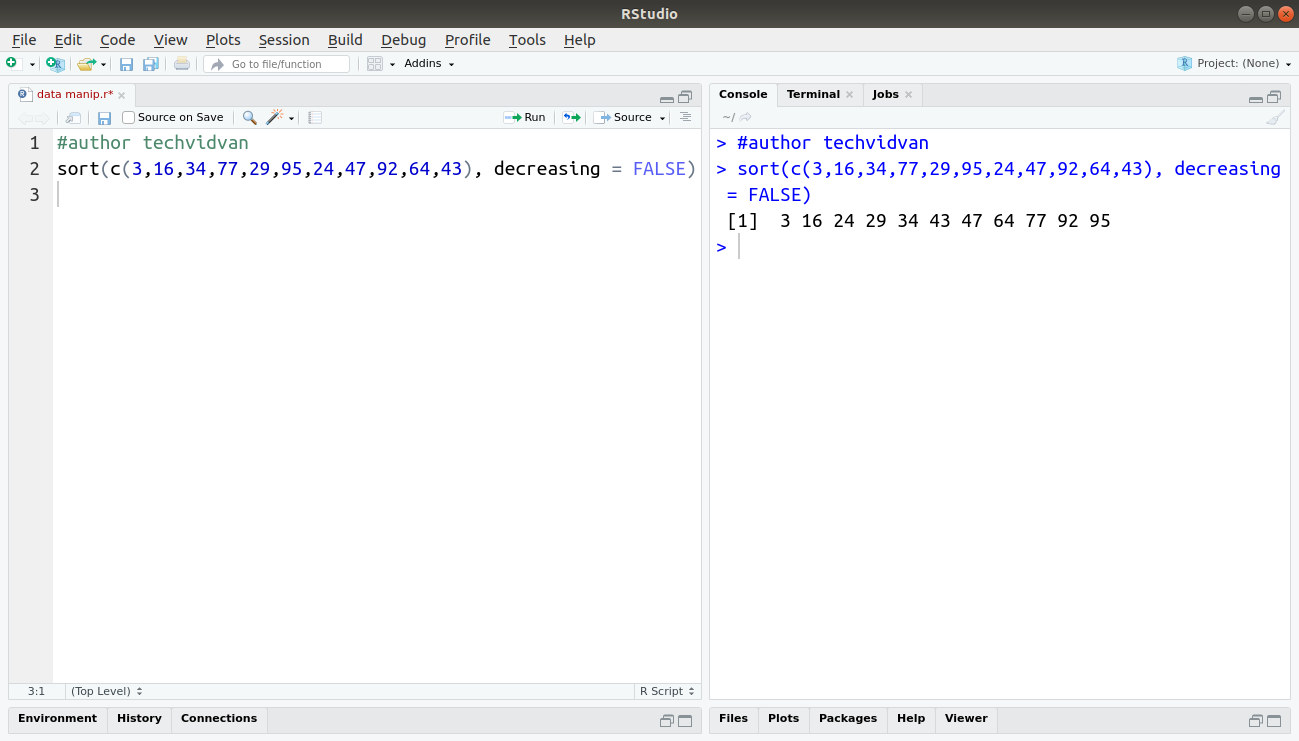
2. The order function
The order() function returns the indices of the elements of the input objects in ascending or descending order. Here is the syntax of the order function.
Code:
order(. . . , na.last = TRUE, decreasing = FALSE, method = c("auto", "shell", "radix"))
Where:
. . . is a sequence of numeric, character, logical or complex vectors or is a classed R object. This is the first argument of the function and is the object(s) that has to be ordered.
na.last is the argument that controls the treatment of NA values.
decreasing controls whether the order of the object will be decreasing or increasing.
method is a character string that specifies the algorithm to be used. method can take the value of “auto”, “radix”, or “shell”.
Let’s take a look at this function through an example:
Code:
a <- c(20,40,70,10,50,30,90,60) order(a) a[order(a)]
Output:
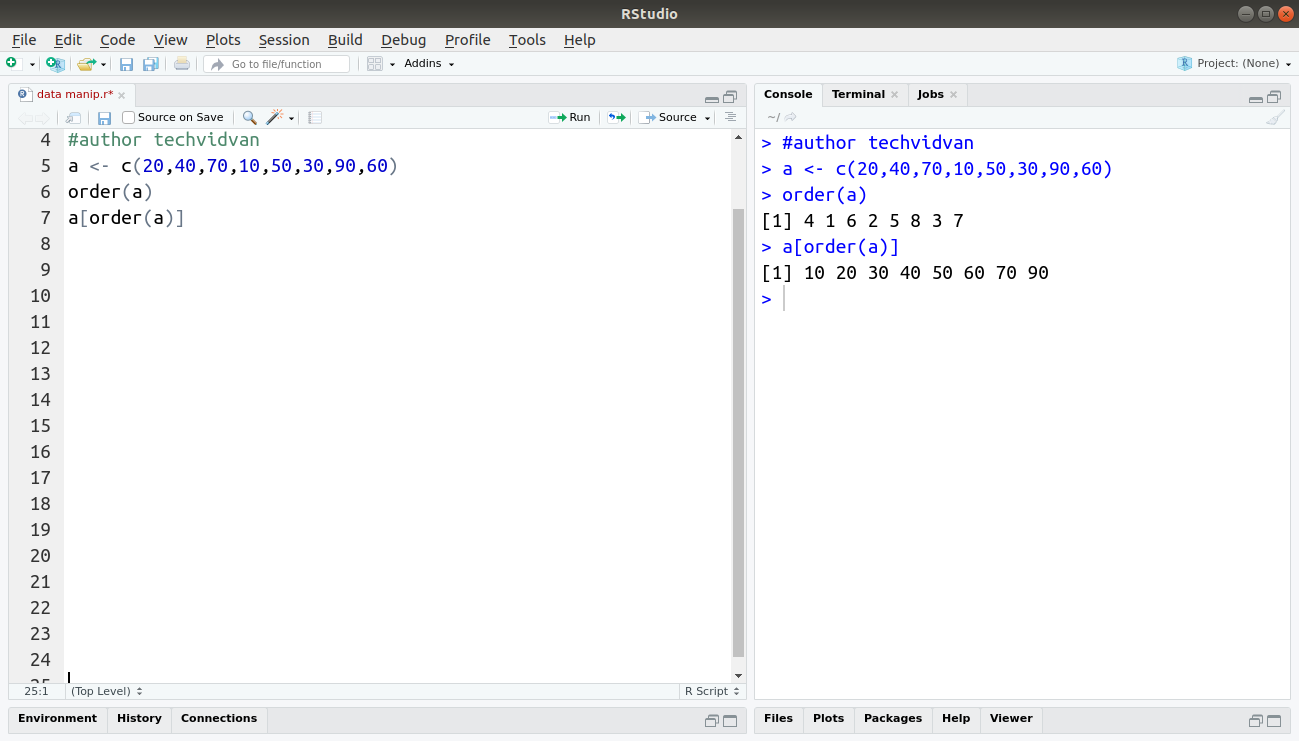
Subsetting a Dataset
There are multiple ways to make subsets of a dataset in R. Depending on the shape and size of the subset, you can either use different operators to index certain parts of a dataset and assign those parts to a variable. These operators are:
1. The $ operator
The $ sign can be used to access a single variable(column) of a dataset. The result of using this notation is a single length vector.
2. The [[ operator
The [[ operator selects a single element like the $ notation. Unlike the $ operator, the [[ operator can be used by specifying the target position instead of the name of the target element.
3. The [ operator
The [ operator takes a numeric, character, or a logical vector to identify its target. This operator returns multiple elements depending on the given target indices.
Here is an example of all three of the above operators.
Code:
mtcars$hp mtcars[[4]] mtcars[4]
Output:
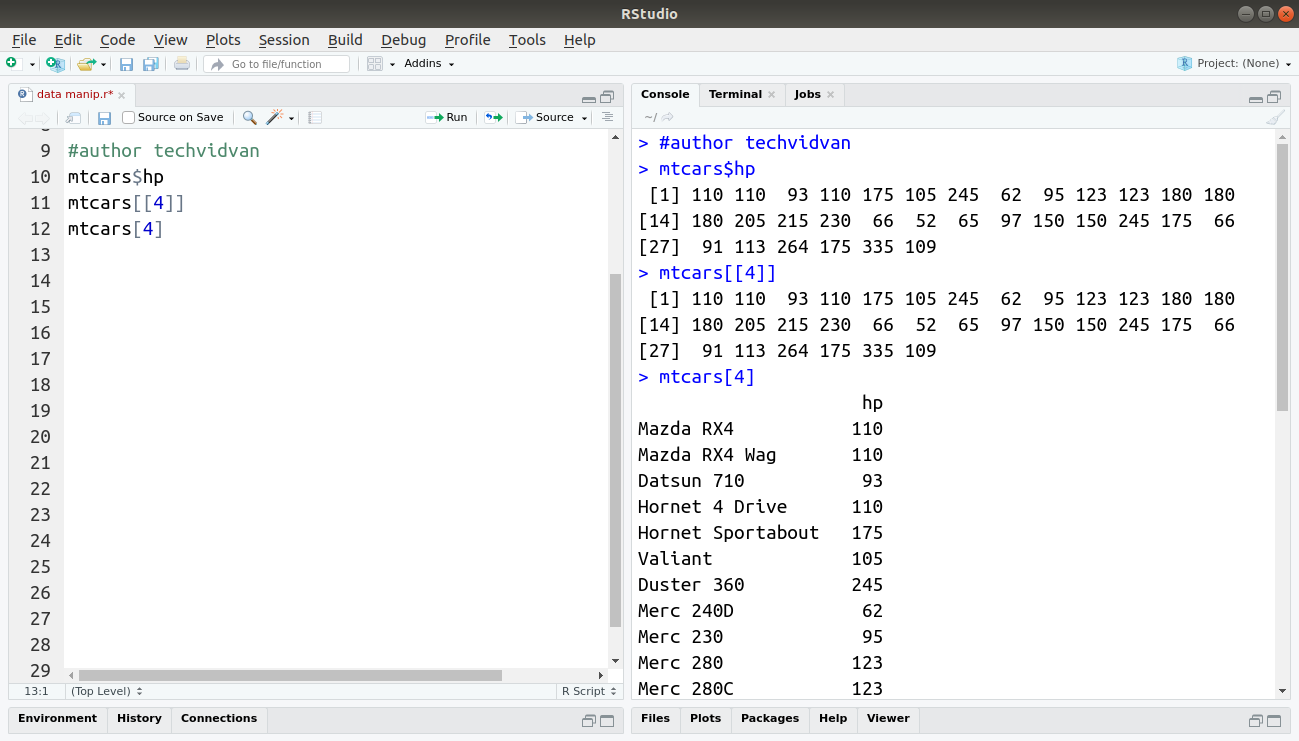
The sample function
The sample() function returns random samples of the given data. The arguments of the function can be used to specify how big the samples need to be and also how many samples should be returned. Here is an example of the sample function in action.
Code:
sample(mtcars, 3)
Output:
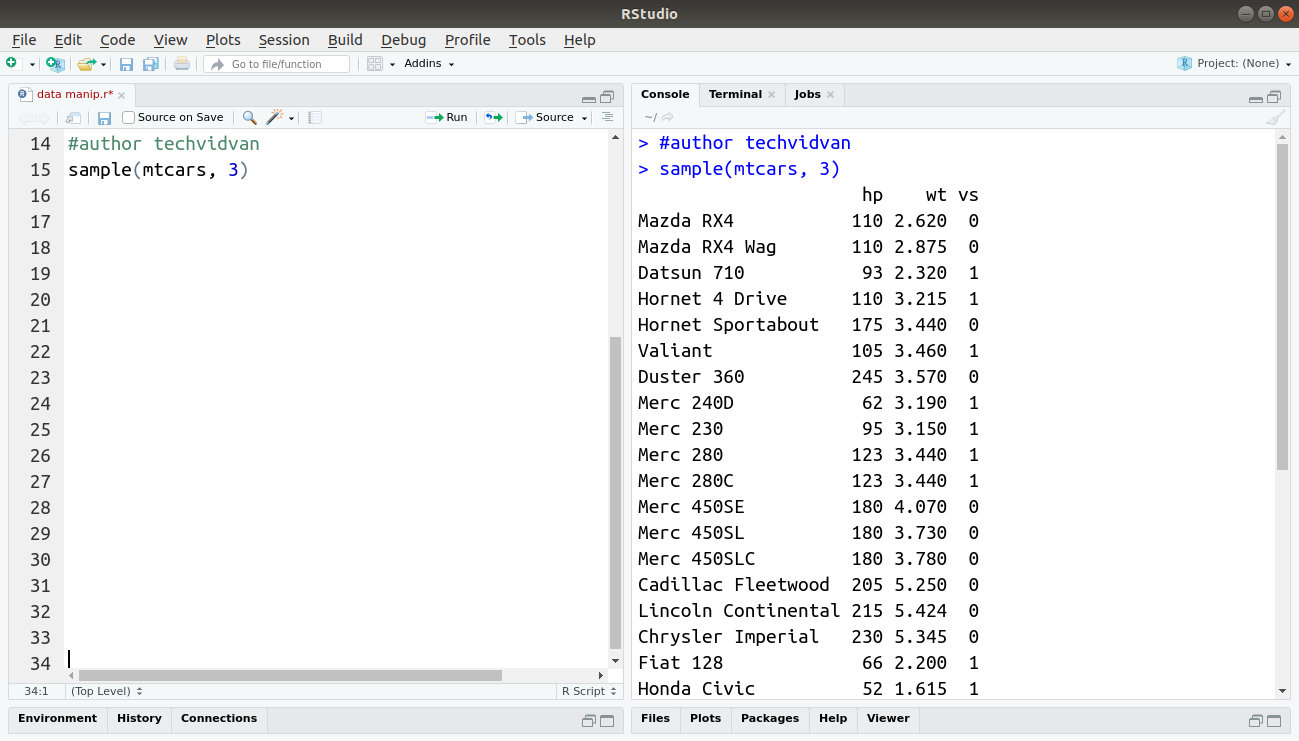
Merging Datasets
There are multiple ways to merging/combining datasets in R. We will be taking a look at the cbind(), the rbind(), and the merge() functions of R that allow us to do so.
1. The cbind function
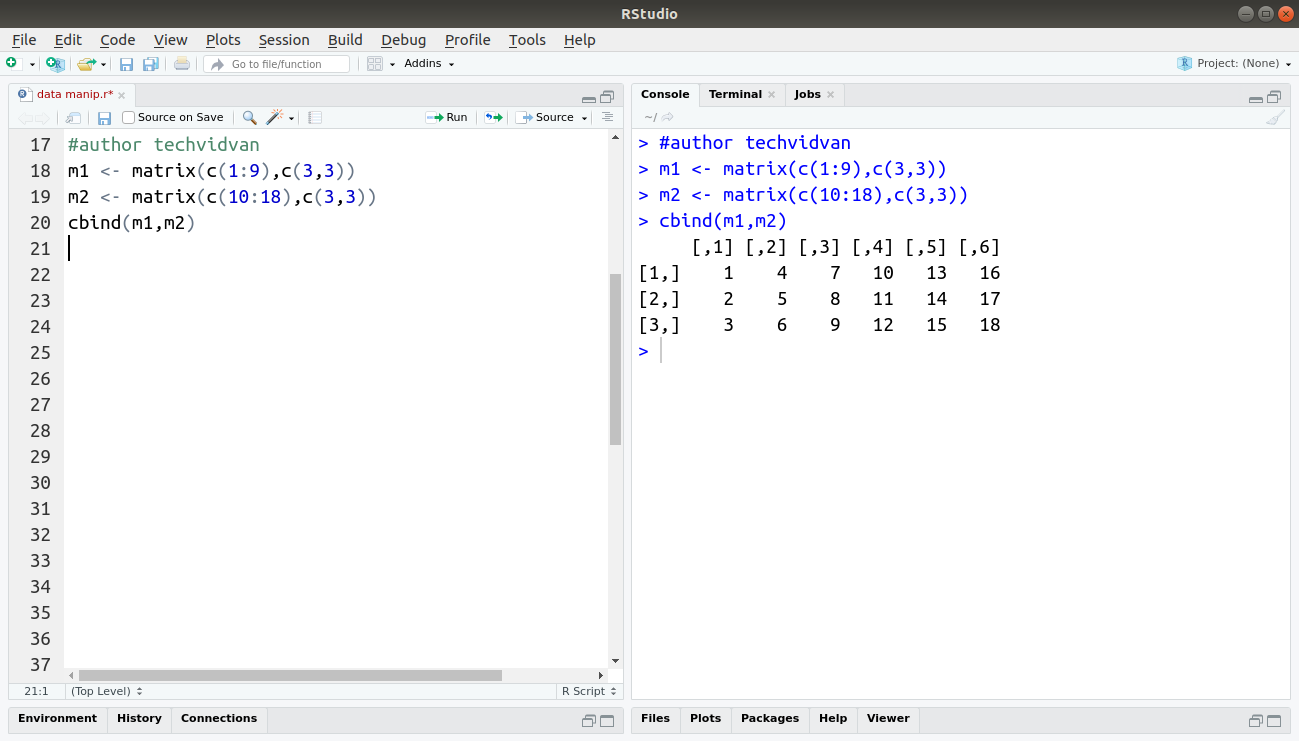
The cbind() function combines two dataset (or data frames) along their columns.
Code:
m1 <- matrix(c(1:9),c(3,3)) m2 <- matrix(c(10:18),c(3,3)) cbind(m1,m2)
Output:
2. The rbind function
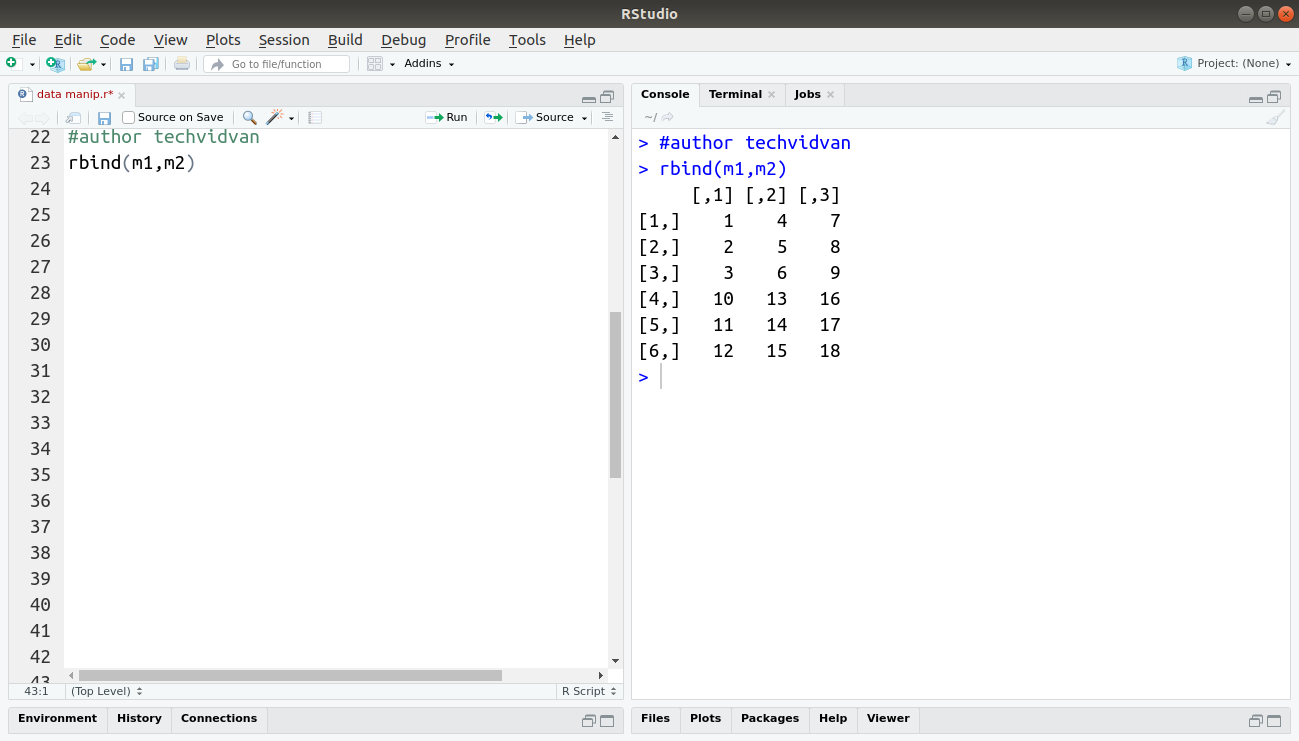
The rbind() function combines two data frames along their rows. If the two data frames have identical variables, then rbind is the easiest way to combine them into one data frame with a larger number of rows.
Code:
rbind(m1,m2)
Output:
3. The merge function
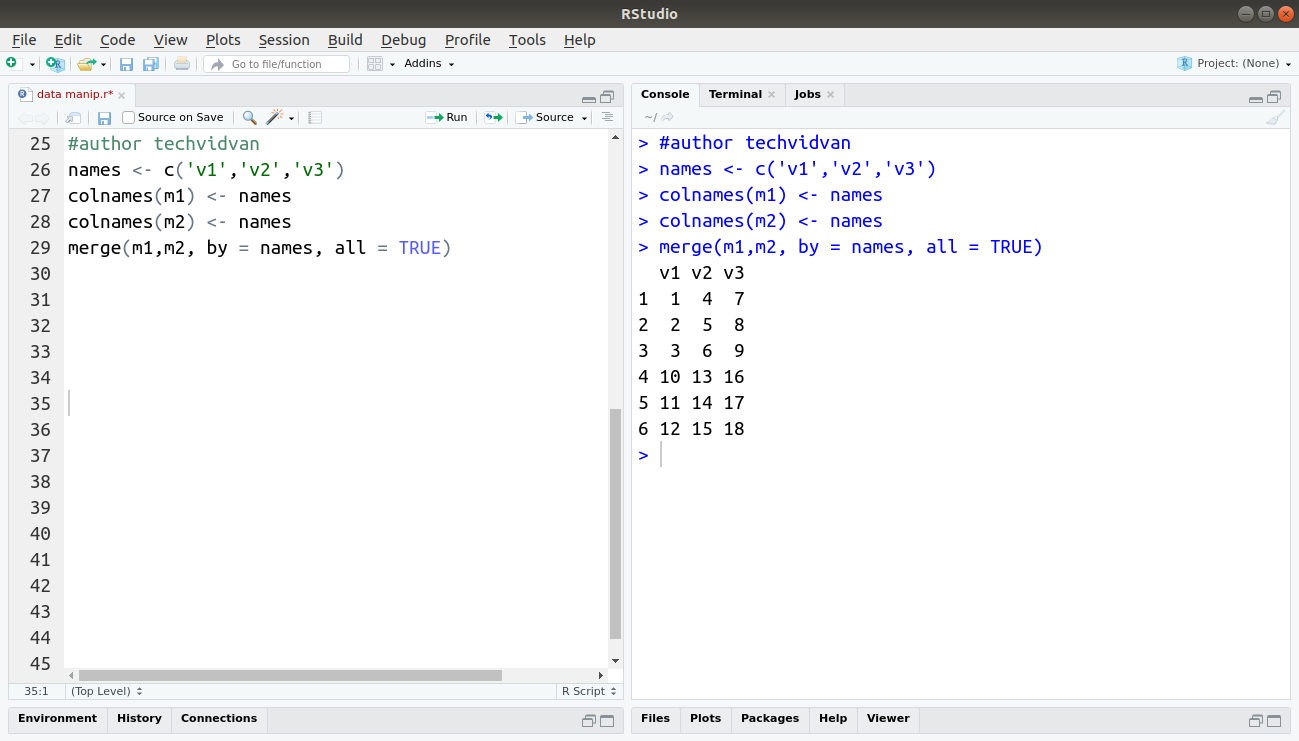
The merge() function performs what is called a join operation in databases. This function combines two data frames based on common columns.
Code:
names <- c('v1','v2','v3')
colnames(m1) <- names
colnames(m2) <- names
merge(m1,m2, by = names, all = TRUE)
Output:
The apply family of functions
The apply collection of functions act like substitutes for loops in R. The functions are different based on their working inputs ad output formats, but the basic idea is the same. These functions apply a function on all the elements of a data structure. Let us take a look at these function one-by-one.
1. The apply function
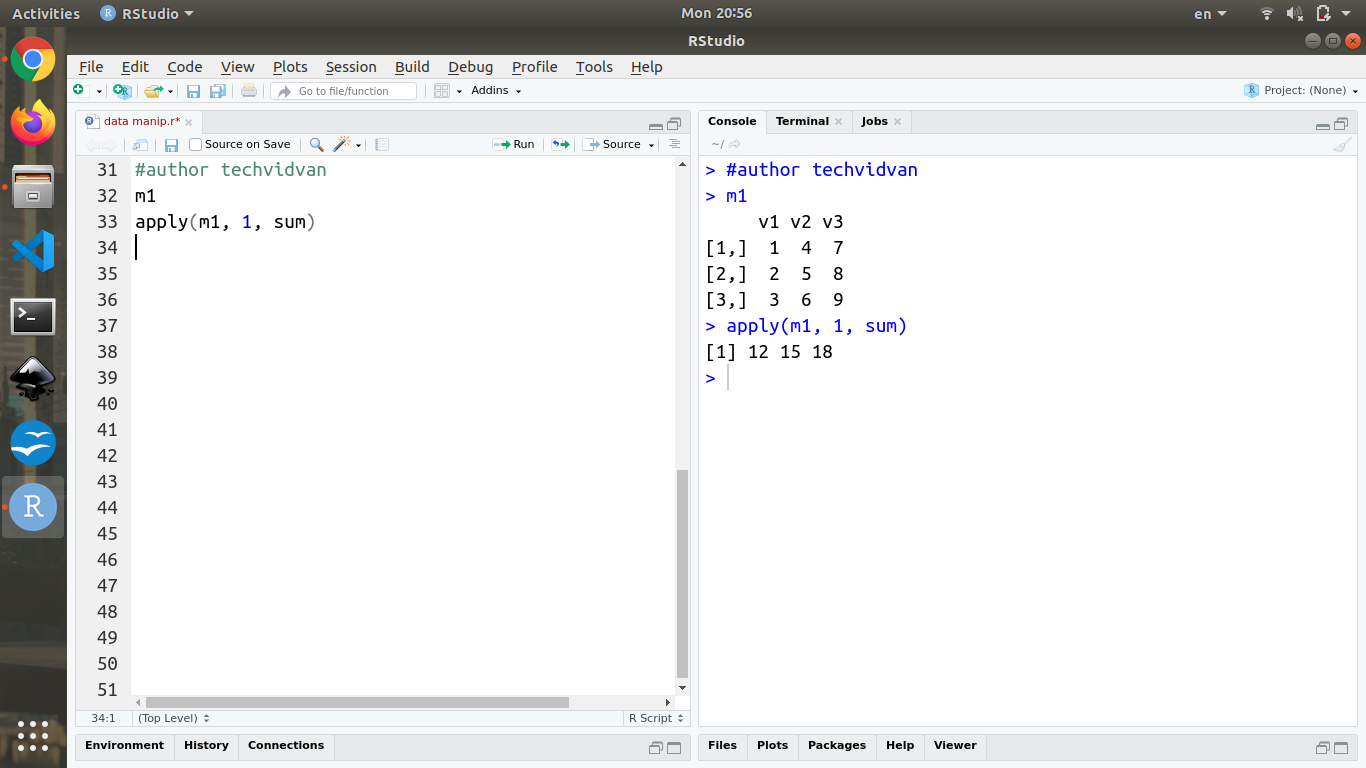
The apply() function applies a function over the margins of the array or a matrix and returns the results in the form of a vector, list or an array.
Code:
apply(m1, 1, sum)
Output:
2. The lapply function
The lapply() function applies a given function over the elements of an input vector. The function returns the results in the form of a list which is of the same length as the input vector.
Code:
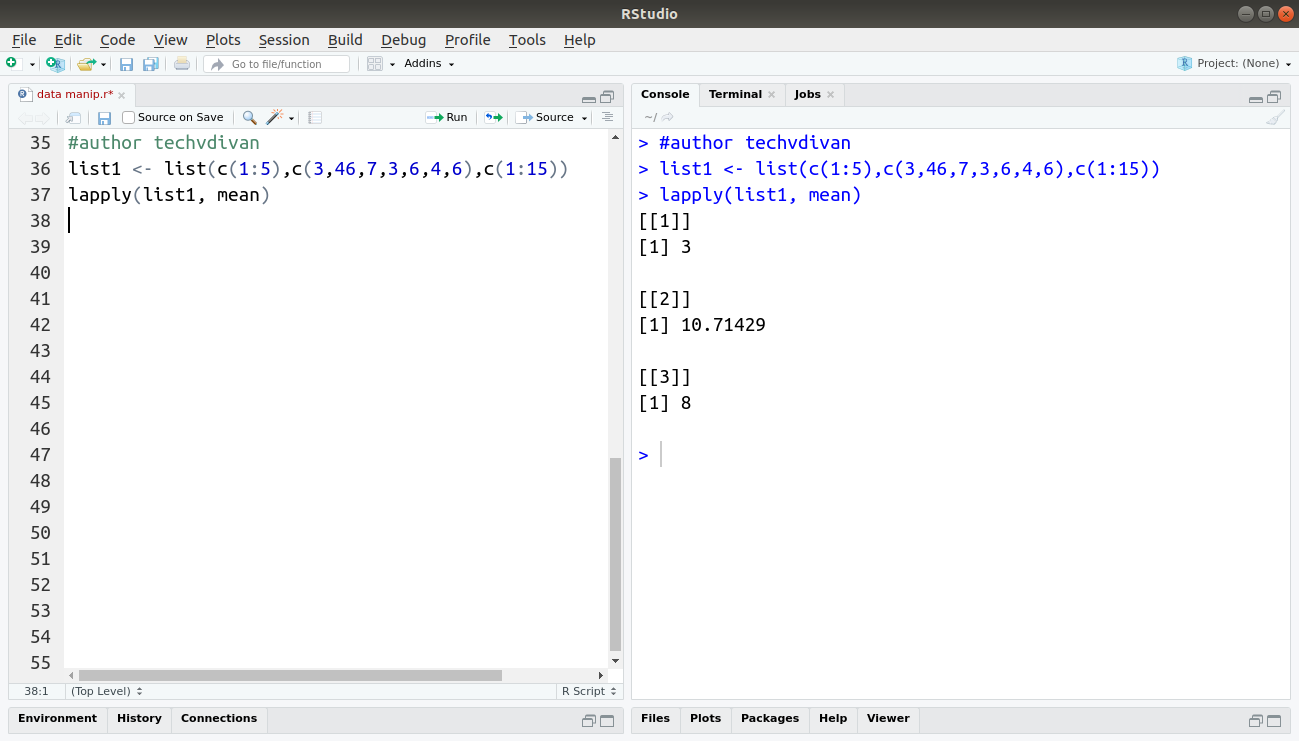
list1 <- list(c(1:5),c(3,46,7,3,6,4,6),c(1:15)) lapply(list1, mean)
Output:
3. The sapply function
The sapply() function does the same job as the lapply() function. The difference being that the sapply function returns the output in the most simplified data structure possible unless the simplify argument is set to FALSE.
Code:
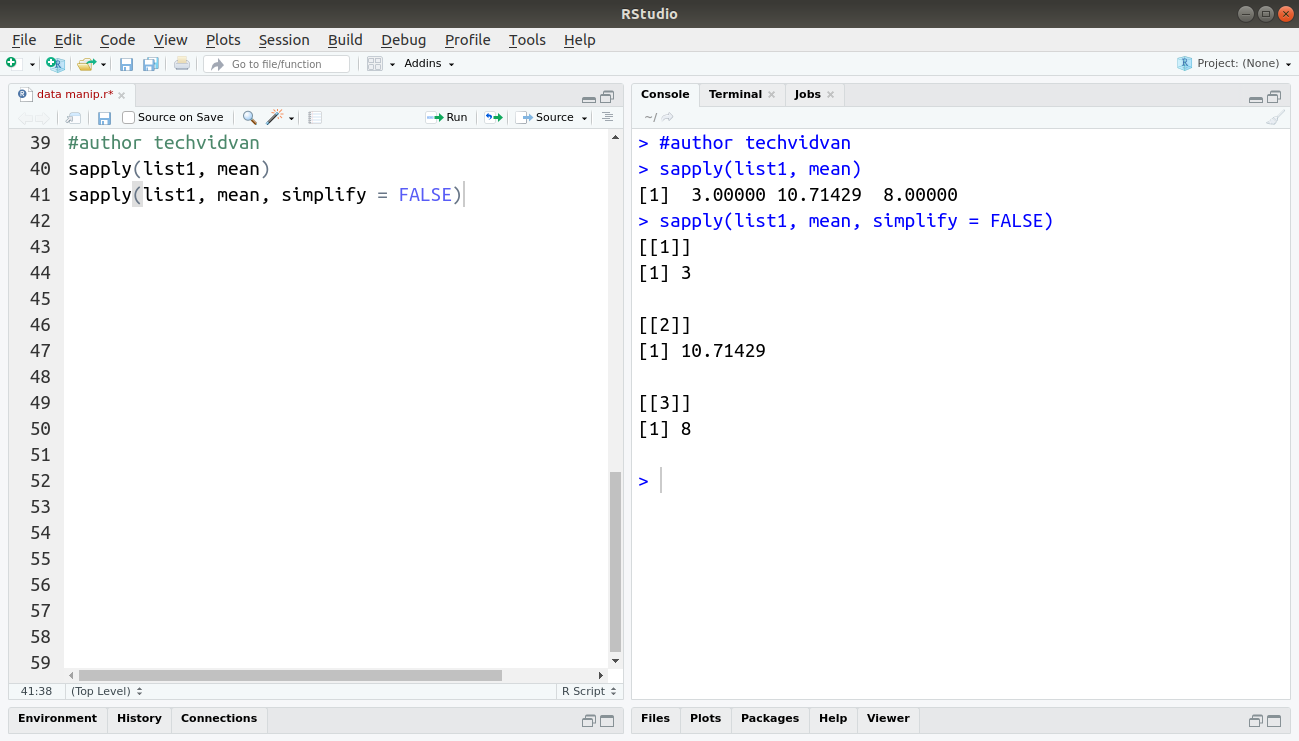
sapply(list1, mean) sapply(list1, mean, simplify = FALSE)
Output:
Summary
In this article of TechVidvan’s R tutorial series, we learned the basics of data manipulation in R. We studied the sort() and the order() function that help in sorting the elements of vectors, arrays, matrices, or data frames. We looked at the different operators that help us in making subsets of our data. Also, learned about the sample() function that allows us to take random samples of a specified length from the given data. We then looked at the functions that help us combine two datasets. Finally, we studied the apply(), the lapply() and the sapply() functions.
I hope now you know data manipulation in R works.
Now, its time to gain more knowledge about your data with Descriptive Statistics in R.
If you still finding any difficulty in it asks our TechVidvan team.
Keep Learning!!