SVM in R for Data Classification using e1071 Package
In this article of the TechVidvan’s R tutorial series, we are going to learn about Support Vector Machines or SVM’s. We will study the SVM algorithm. We shall then look into its advantages and disadvantages. Then we will also look at some of the applications of SVM’s in the real world. Later on, we shall study the e1071 package of R. Finally, we will implement the SVM in R using the e1071 package.
So, let’s get started.

Support Vector Machines in R
As we learned in the previous chapter of the TechVidvan’s R tutorial series, the Support vector machine is a classification algorithm in machine learning though it can also be used to perform regression.
An SVM plots input data objects as points in an n-dimensional space, where the dimensions represent the various features of the object. The algorithm then attempts to iteratively find a function that represents a hyperplane that can act as a separator between the spaces occupied by different target output classes.
Although SVM is primarily for binary classification, researches suggest that i SVM’s can be used to perform multi-class classification with i different target output classes.
An SVM model is a representation of the input data objects in a graphical space with a clear gap between groups of points representing different categories. This division is caused by the hyperplane, which is a line (in case of 2D space) or a plane (in case of the 3D plane). The hyperplane is a division curve that splits the space such as it clearly signifies which section of the space is occupied by which category. The following is an example of a trained SVM model.
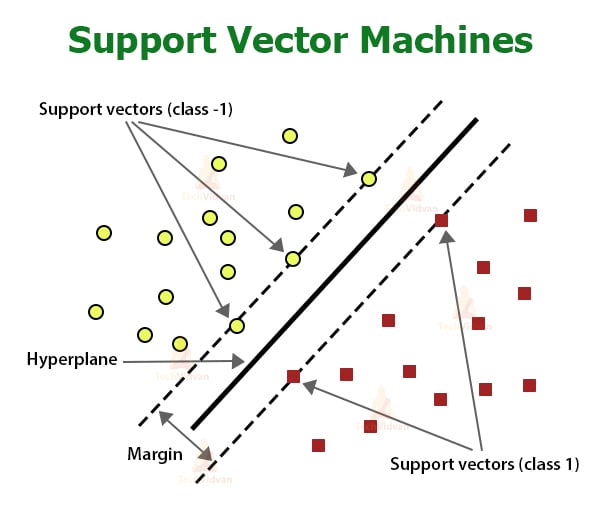
As you might notice in the figure above, the hyperplane has two parallel dotted lines on either side of it. The perpendicular distance between these two lines is called the margin. Margin is the distance between the data points of the two different categories.
In an SVM model, there may exist multiple possible hyperplanes. The goal of the SVM algorithm is to find a hyperplane such that the margin is maximized.
The data points closest to the hyperplane have the largest impact on the position of the hyperplane. these points are called support vectors.
Advantages and Disadvantages of SVM in R
Let us now compare the pros and cons or the advantages and the disadvantages of the SVM algorithm.
Advantages of SVM in R
- SVM works very well with higher-dimensional datasets.
- SVM is one of the most memory-efficient classification algorithms.
- The clearer the margin of separation between the categories, the better the SVM works.
- SVM’s are primarily for linear data, but they also work well with the help of the kernel trick.
- The SVM algorithm is very stable. Minor changes in the data do not reflect great changes in the results.
Disadvantages of SVM in R
- It is not suitable for a very large dataset.
- When the target categories overlap or the data has noise the performance of the algorithm decreases rapidly.
- It is a non-probabilistic classifier i.e. there is no probabilistic explanation for any classification done by an SVM.
Real-Life Applications of R SVM
Like many other machine learning algorithms, SVM’s have also found wide-spread applications in the real world. SVM’s help in solving many day-to-day classification problems all over the world. Let us take a look at some of these one at a time.
1. Handwriting Detection
Many handwriting detection programs use SVM’s to identify handwritten characters.
2. Image-based Searching
SVM’s are an avenue for improving images based searching. This approach should prove to be much faster than query-based searching for images.
3. Face Detection
Every smartphone has a face detection feature in its camera these days. SVM separates the faces from the rest of the picture.
4. Bioinformatics
SVM’s are used to classify people based on genes and other biological features.
5. Cancer Detection
SVM’s can detect malignant tumors from benign ones by considering their images.
e1071 Package in R
e1071 is a package for R programming that provides functions for statistic and probabilistic algorithms like a fuzzy classifier, naive Bayes classifier, bagged clustering, short-time Fourier transform, support vector machine, etc..
When it comes to SVM, there are many packages available in R to implement it. However, e1071 is the most intuitive package for this purpose.
The svm() function of the e1071 package provides a robust interface in the form of the libsvm. This interface makes implementing SVM’s very quick and simple. It also facilitates probabilistic classification by using the kernel trick. It provides the most common kernels like linear, RBF, sigmoid, and polynomial.
Practical implementation of an SVM in R
Let us now create an SVM model in R to learn it more thoroughly by the means of practical implementation. We will be using the e1071 packages for this.
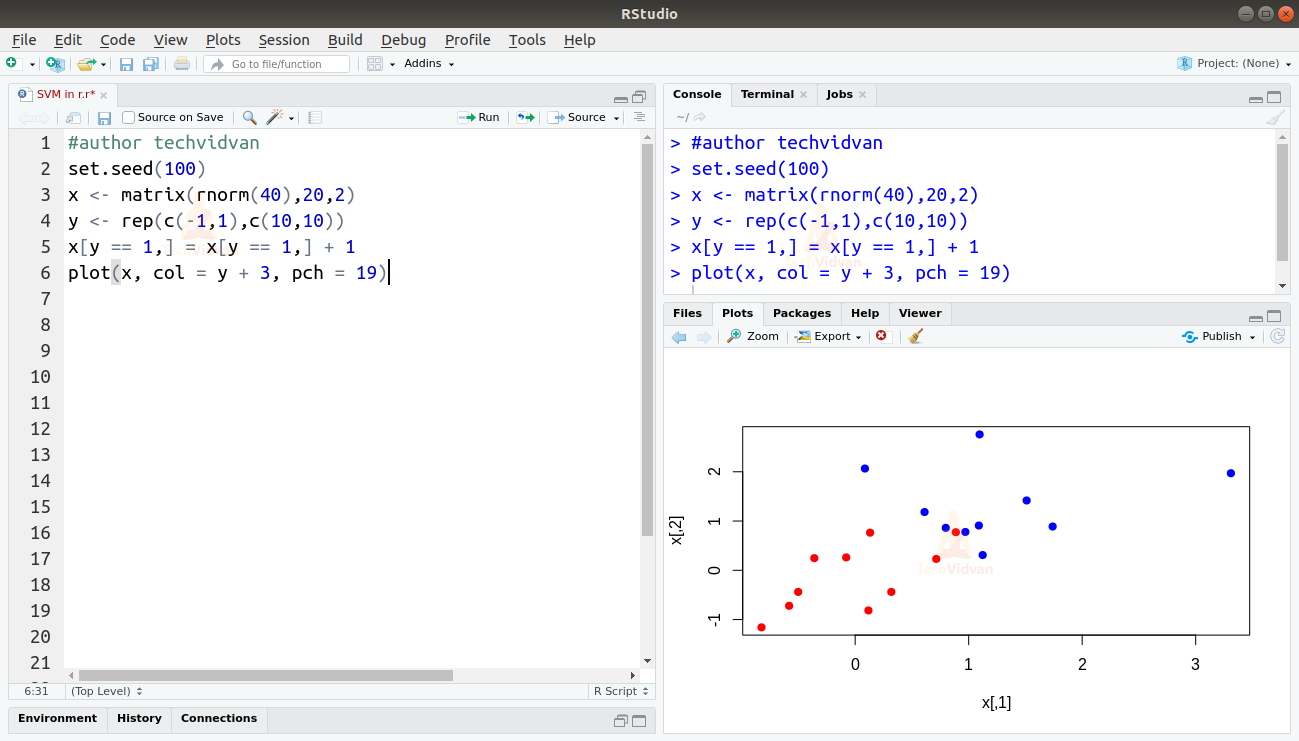
1. Let us generate some 2-dimensional data. We will generate 20 random observations of 2 variables in the form of a 20 by 2 matrix. This gives us 20 objects with 2 features each.
set.seed(100) x <- matrix(rnorm(40),20,2) y <- rep(c(-1,1),c(10,10)) x[y == 1,] = x[y == 1,] + 1 plot(x, col = y + 3, pch = 19)
Output
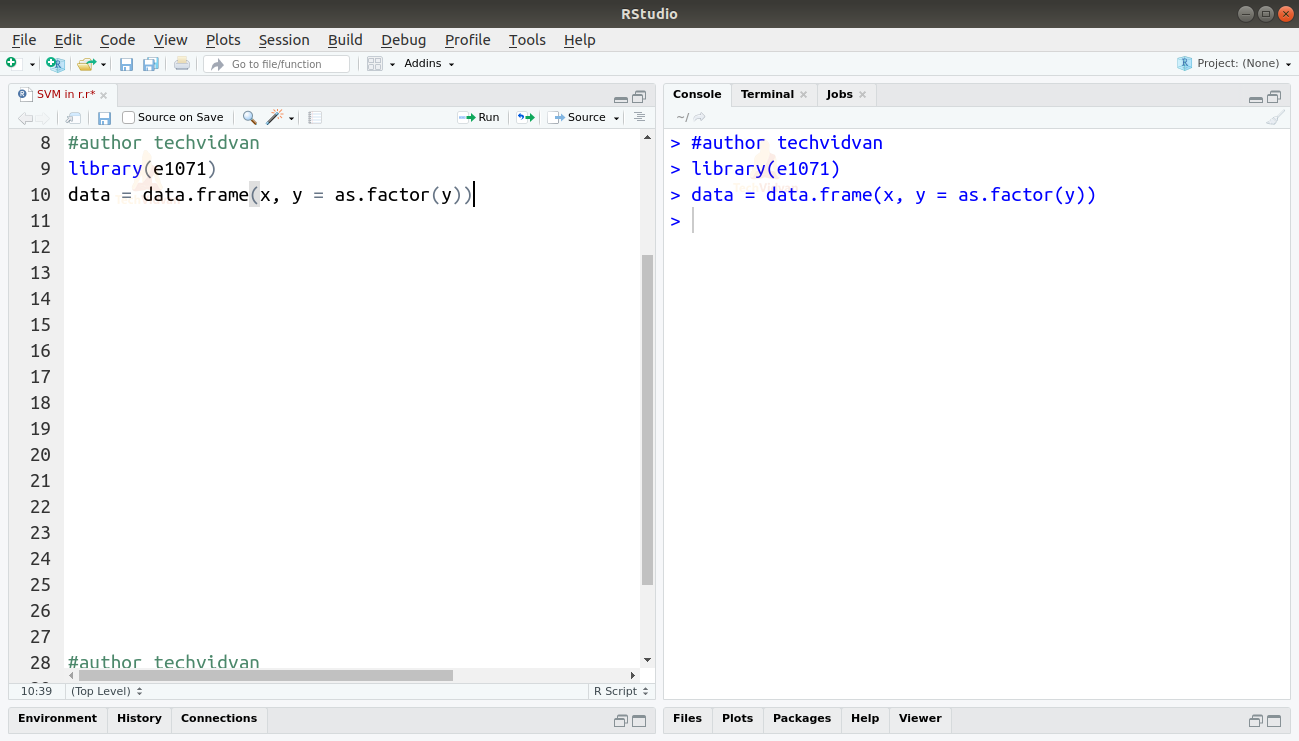
2. Now that our data is ready we should now load the e1071 package. We will then turn the data into a data frame. We will also convert y into a factor.
library(e1071) data = data.frame(x, y = as.factor(y))
Output
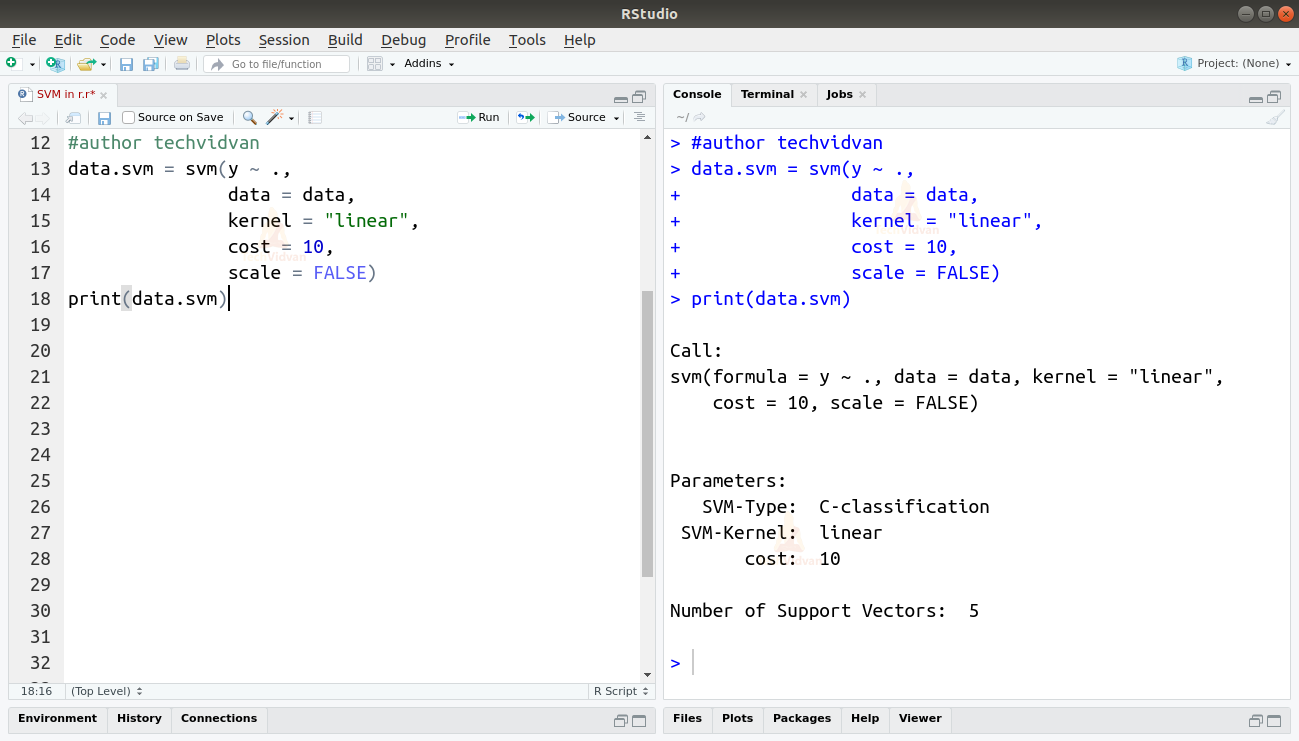
3. After that, let us create our model by using the svm function. We will be specifying the kernel as linear, and cost as 10. As our data is on a relatively smaller scale, we will set the scale argument as FALSE.
data.svm = svm(y ~ ., data = data, kernel = "linear", cost = 10, scale = FALSE) print(data.svm)
Output
4. Finally, we plot the model using the plot() function.
plot(data.svm, data)
Output

Summary
In conclusion, in this chapter of the TechVidvan’s R tutorial series, we learned about support vector machines and their uses in machine learning. We learned what the SVM algorithm is and also what are its advantages and disadvantages. We then looked at the e1071 package of R and its svm() function. Finally, we used the e1071 package and its svm function to implement the SVM algorithm in R.
Do share your feedback in the comment section.