R Classification – Algorithms, Applications and Examples
In this R tutorial, we are going to learn about R Classification and various classification techniques and algorithms in machine learning and R. We will start off with what is classification in R? We are then going to look at the differences between clustering and classification. Then we will learn the various types of classification algorithms and look at them in detail. Finally, we shall implement a classification algorithm in R.
What is R Classification?
Classification is the process of predicting a categorical label of a data object based on its features and properties. In classification, we locate identifiers or boundary conditions that correspond to a particular label or category. We then try to place various unknown objects into those categories, by using the identifiers. An example of this would be to predict the type of water(mineral, tap, smart, etc.), based on its purity and mineral content.
R Clustering vs R Classification
In clustering in R, we try to group similar objects together. The principle behind R clustering is that objects in a group are similar to other objects in that set and no objects in different groups are similar to each other.
In classification in R, we try to predict a target class. The possible classes are already known and so are all of the classes’ identifying properties. The algorithm needs to identify which class does a data object belong to.
Basic Terminologies of R Classification
1. Classifier: A classifier is an algorithm that classifies the input data into output categories.
2. Classification model: A classification model is a model that uses a classifier to classify data objects into various categories.
3. Feature: A feature is a measurable property of a data object.
4. Binary classification: A binary classification is a classification with two possible output categories.
5. Multi-class classification: A multi-class classification is a classification with more than two possible output categories.
6. Multi-label classification: A multi-label classification is a classification where a data object can be assigned multiple labels or output classes.
Classification Algorithms in R
There are various classifiers or classification algorithms in machine learning and R programming. We are going to take a look at some of these classifiers.
1. R Logistic Regression
As we studied in the logistic regression tutorial, it is a regression algorithm that predicts the value of a categorical variable. It finds the value of a variable that can only take two possible values (ex: pass or fail). Logistic regression finds the relationship between a categorical dependent variable and several independent variables. We can also state this as logistic regression finds the relationship between which class does a data object lies into and said object’s features. Not only does the algorithm find a class for an object, but it also gives justification and reasoning for that object to be in a specific class.
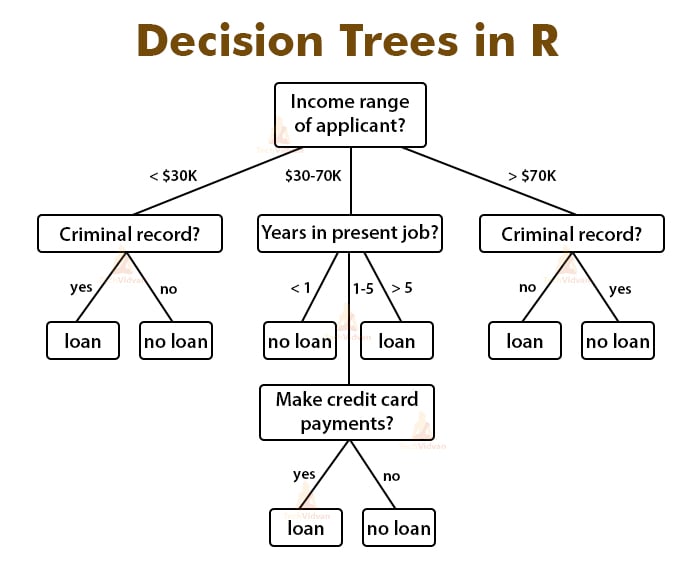
2. Decision Trees in R
Decision trees represent a series of decisions and choices in the form of a tree. They use the features of an object to decide which class the object lies in. These classes usually lie on the terminal leavers of a decision tree. Decision trees can be binary or multi-class classifiers. They use multiple rules with binary results to form a series of checks that judge and tell the class of an object according to its features. Decision trees are an example of divide and conquer algorithms as they use the rules to divide the objects repeatedly until a final decision has been made.
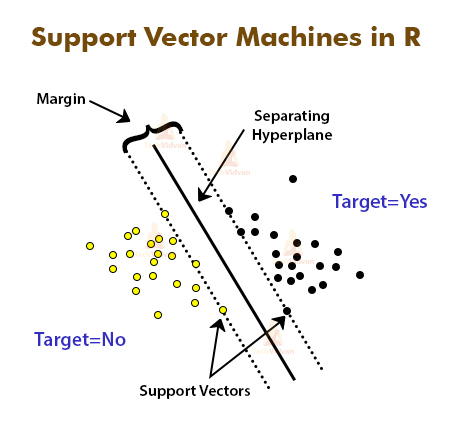
3. Support Vector Machines in R
A support vector machine represents data objects as points in space. It then devises a function that can split the space according to the target output classes. SVM uses the training set to plot objects in space and to fine-tune the function that splits the space. Once the function is finalized, it places the objects in different parts of the space depending on which class they fall into. SVM’s are very lightweight and highly efficient in higher dimensional spaces.
4. Naive Bayes Classifier
Naive Bayes classifier is a classification algorithm based on Bayes’s theorem. It considers all the features of a data object to be independent of each other. They are very fast and useful for large datasets. They achieve very accurate results with very little training. The following is the equation for the Bayes’s theorem:
P(Ci|x1,x2,…,xn)=P(x1,x2,…,xn).P(Ci)/P(x1,x2,…,xn)
Where C is the target category,
And x1, …. , xn are features of a particular object.
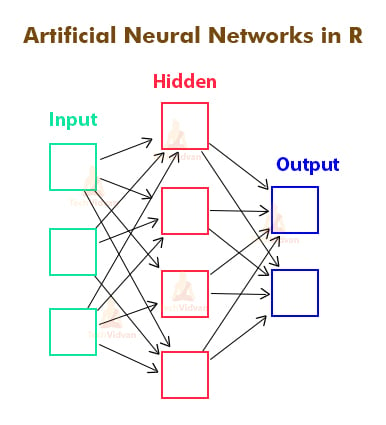
5. Artificial Neural Networks in R
Artificial neural networks are collections of connections or neurons that connect various nodes. Each connection between two nodes in a neural network represents a relationship between those two nodes. These neurons are arranged in layers in an artificial neural network. Each node contains a non-linear function that it applies to the input and then passes on the output to the next layer. They are feed-forward networks which means that each layer passes on the output to the next layer until a final result is obtained. During the training of the model, different weights are assigned to different layers, connections, and nodes. These weights tell which values and outputs are to be preferred more and by how much. Neural networks are very good when dealing with noisy data.
6. K – Nearest Neighbor in R
K-nearest neighbor is a lazy learning algorithm. It maps and stores all of the objects in the training set in an n-dimensional space. It uses the labeled objects to label other objects that are not labeled or classified yet. To label a new object, it looks at its k nearest neighbors. A count is then carried out and the label carried by the majority of the neighbors is assigned to the unlabeled object. This algorithm is very robust for noisy data and also works fine for large datasets. It is, however, more computationally heavy than other classification techniques.
Applications of R Classification Algorithms
Now that we have looked at the various classification algorithms. Let’s take a look at their applications:
1. Logistic regression
- Weather forecast
- Word classification
- Symptom classification
2. Decision trees
- Pattern recognition
- Pricing decisions
- Data exploration
3. Support Vector Machines
- Investment suggestions
- Stock comparison
4. Naive Bayes Classifier
- Spam filters
- Disease prediction
- Document classification
5. Artificial Neural Network
- Handwriting analysis
- Object recognition
- Voice recognition
6. k-Nearest Neighbor
- Industrial task classification
- Video recognition
- Image recognition
Summary
In this chapter of TechVidvan’s R tutorial series, we learned about R classification. We learned what is classification in machine learning and R programming. We studied the difference between R clustering and R classification and looked at the basic terminologies of classification in R. Then we studied different classification algorithms in machine learning and R. Further we learned about logistic regression, decision trees, SVM’s Naive Bayes’s classifiers, neural networks, and also about the k-nearest neighbor algorithm. Finally, we looked at the real-world applications of the various classification algorithms.