Build a Movie Recommendation System in Python using Machine Learning
Ever wondered how Netflix or Hotstar recommends new movies based on the watch history, how Amazon or Flipkart suggests new products based on your order or search history?
These suggestions or recommendations are done by a system called a recommendation system. This engine makes suggestions by learning and understanding the patterns in your watch history (let’s say) and then applies those patterns and findings to make new suggestions.
About Movie Recommendation Project
In this machine learning project, we build a recommendation system from the ground up to suggest movies to the user based on his/her preferences.
Project Dataset
There are several datasets available to build a movie recommendation system. But for this project, we are going to use a dataset that contains the metadata (cast, crew, budget, etc..) of the movie.
Please download movie dataset: Movie Recommendation Dataset
Tools and Libraries used
- Python – 3.x
- Pandas – 1.2.4
- Scikit-learn – 0.24.1
To install the above libraries on your machine, use the following command.
pip install pandas scikit-learn
Download Movie Recommendation System Project Code
Please download the python source code of movie recommendation system: Movie Recommendation System Project Code
What is a Recommendation System?
Before moving on to build a recommender engine for movies, let’s discuss recommendation systems.
Recommendation systems are computer programs that suggest recommendations to users depending on a variety of criteria.
These systems estimate the most likely product that consumers will buy and that they will be interested in. Netflix, Amazon, and other companies use recommender systems to help their users find the right product or movie for them.
There are 3 types of recommendation systems.
- Demographic Filtering: The recommendations are the same for every user. They are generalized, not personalized. These types of systems are behind sections like “Top Trending”.
- Content-based Filtering: These suggest recommendations based on the item metadata (movie, product, song, etc). Here, the main idea is if a user likes an item, then the user will also like items similar to it.
- Collaboration-based Filtering: These systems make recommendations by grouping the users with similar interests. For this system, metadata of the item is not required.
In this project, we are building a Content-based recommendation engine for movies.
How to build a Movie Recommendation System using Machine Learning
The approach to build the movie recommendation engine consists of the following steps.
- Perform Exploratory Data Analysis (EDA) on the data
- Build the recommendation system
- Get recommendations
Step 1: Perform Exploratory Data Analysis (EDA) on the data
The dataset contains two CSV files, credits, and movies. The credits file contains all the metadata information about the movie and the movie file contains the information like name and id of the movie, budget, languages in the movie that has been released, etc.
Let’s load the movie dataset using pandas.
import pandas as pd path = "./Desktop/TechVidvan/movie_recommendation" credits_df = pd.read_csv(path + "/tmdb_credits.csv") movies_df = pd.read_csv(path + "/tmdb_movies.csv")
Let’s have a peek at our dataframes.
movies_df.head()
Output:
credits_df.head()
Output:

We only need the id, title, cast, and crew columns of the credits dataframe. Let’s merge the dataframes into one on the column ‘id’.
credits_df.columns = ['id','title','cast','crew'] movies_df = movies_df.merge(credits_df, on="id")
Our new dataframe would be:
movies_df.head()
Output:
Step 2: Build the Movie Recommender System
The accuracy of predictions made by the recommendation system can be personalized using the “plot/description” of the movie.
But the quality of suggestions can be further improved using the metadata of movie. Let’s say the query to our movie recommendation engine is “The Dark Knight Rises”. Then the predictions should also include movies directed by the director of the film. It should also include movies with the cast of the given query movie.
For that, we utilize the following features to personalize the recommendation: cast, crew, keywords, genres.
The movie data is present in the form of lists containing strings, we need to convert the data into a safe and usable structure. Let’s apply the literal_eval() function to the features.
from ast import literal_eval
features = ["cast", "crew", "keywords", "genres"]
for feature in features:
movies_df[feature] = movies_df[feature].apply(literal_eval)
movies_df[features].head(10)
Output:
Let’s write some functions to extract information like director from the above features.
The get_director() function extracts the name of the director of the movie.
def get_director(x):
for i in x:
if i["job"] == "Director":
return i["name"]
return np.nan
The get_list() returns the top 3 elements or the entire list whichever is more.
def get_list(x):
if isinstance(x, list):
names = [i["name"] for i in x]
if len(names) > 3:
names = names[:3]
return names
return []
Let’s apply both the functions get_director() and get_list() to our dataset.
movies_df["director"] = movies_df["crew"].apply(get_director)
features = ["cast", "keywords", "genres"]
for feature in features:
movies_df[feature] = movies_df[feature].apply(get_list)
In the above code, we passed the “crew” information to the get_director() function, extracted the name, and created a new column “director”.
For the features cast, keyword and genres we extracted the top information by applying the get_list() function
Let’s see how the data looks like after the above transformations.
movies_df[['title', 'cast', 'director', 'keywords', 'genres']].head()
Output:

The next step would be to convert the above feature instances into lowercase and remove all the spaces between them.
def clean_data(row):
if isinstance(row, list):
return [str.lower(i.replace(" ", "")) for i in row]
else:
if isinstance(row, str):
return str.lower(row.replace(" ", ""))
else:
return ""
features = ['cast', 'keywords', 'director', 'genres']
for feature in features:
movies_df[feature] = movies_df[feature].apply(clean_data)
Now, let’s create a “soup” containing all of the metadata information extracted to input into the vectorizer.
def create_soup(features):
return ' '.join(features['keywords']) + ' ' + ' '.join(features['cast']) + ' ' + features['director'] + ' ' + ' '.join(features['genres'])
movies_df["soup"] = movies_df.apply(create_soup, axis=1)
print(movies_df["soup"].head())
Output:

Our movie recommendation engine works by suggesting movies to the user based on the metadata information. The similarity between the movies is calculated and then used to make recommendations. For that, our text data should be preprocessed and converted into a vectorizer using the CountVectorizer. As the name suggests, CountVectorizer counts the frequency of each word and outputs a 2D vector containing frequencies.
We don’t take into account the words like a, an, the (these are called “stopwords”) because these words are usually present in higher amounts in the text and don’t make any sense.
There exist several similarity score functions such as cosine similarity, Pearson correlation coefficient, etc. Here, we use the cosine similarity score as this is just the dot product of the vector output by the CountVectorizer.
We also reset the indices of our dataframe.
from sklearn.feature_extraction.text import CountVectorizer from sklearn.metrics.pairwise import cosine_similarity count_vectorizer = CountVectorizer(stop_words="english") count_matrix = count_vectorizer.fit_transform(movies_df["soup"]) print(count_matrix.shape) cosine_sim2 = cosine_similarity(count_matrix, count_matrix) print(cosine_sim2.shape) movies_df = movies_df.reset_index() indices = pd.Series(movies_df.index, index=movies_df['title'])
Output:

Create a reverse mapping of movie titles to indices. By this, we can easily find the title of the movie based on the index.
indices = pd.Series(movies_df.index, index=movies_df["title"]).drop_duplicates() print(indices.head())
Output:

Step 3: Get recommendations for the movies
The get_recommendations() function takes the title of the movie and the similarity function as input. It follows the below steps to make recommendations.
- Get the index of the movie using the title.
- Get the list of similarity scores of the movies concerning all the movies.
- Enumerate them (create tuples) with the first element being the index and the second element is the cosine similarity score.
- Sort the list of tuples in descending order based on the similarity score.
- Get the list of the indices of the top 10 movies from the above sorted list. Exclude the first element because it is the title itself.
- Map those indices to their respective titles and return the movies list.
Create a function that takes in the movie title and the cosine similarity score as input and outputs the top 10 movies similar to it.
def get_recommendations(title, cosine_sim=cosine_sim):
idx = indices[title]
similarity_scores = list(enumerate(cosine_sim[idx]))
similarity_scores= sorted(similarity_scores, key=lambda x: x[1], reverse=True)
similarity_scores= sim_scores[1:11]
# (a, b) where a is id of movie, b is similarity_scores
movies_indices = [ind[0] for ind in similarity_scores]
movies = movies_df["title"].iloc[movies_indices]
return movies
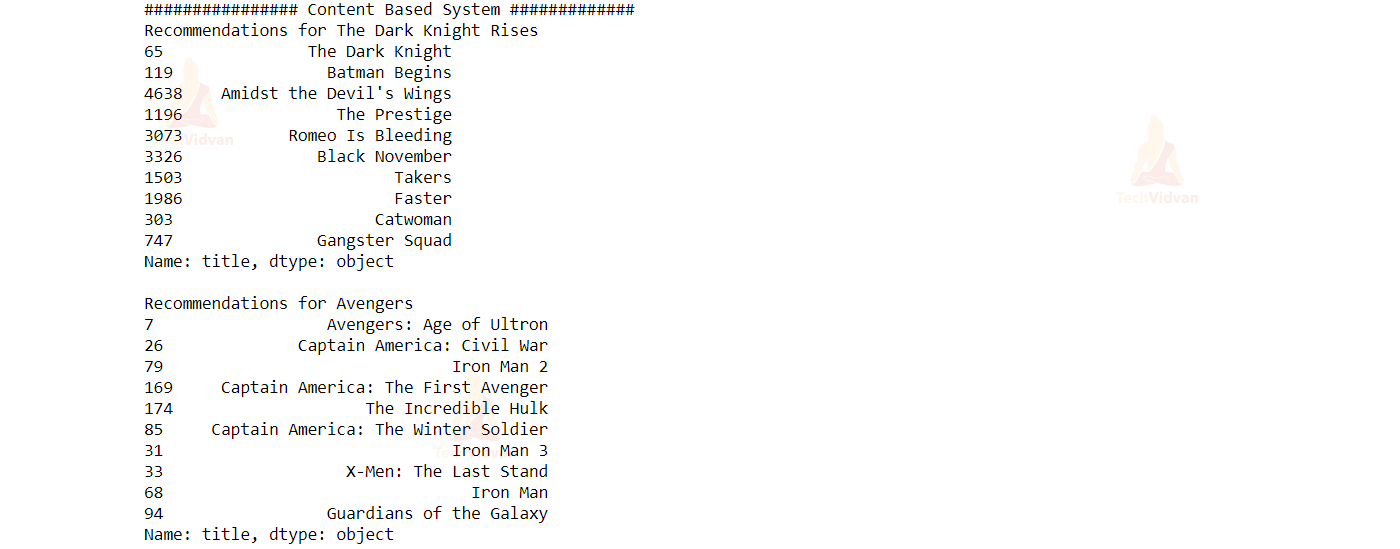
print("################ Content Based System #############")
print("Recommendations for The Dark Knight Rises")
print(get_recommendations("The Dark Knight Rises", cosine_sim2))
print()
print("Recommendations for Avengers")
print(get_recommendations("The Avengers", cosine_sim2))
Output:
Here goes our movie recommendation engine.
Summary
In this machine learning project, we build movie recommendation systems. We built a content-based recommendation engine that makes recommendations given the title of the movie as input.