Spam Detection using SVM
With this Machine Learning Project, we will be building an SMS Spam detector using an SVM classifier. Spam detector is very useful software these days to detect any spam message and protect yourself from fraud.
So, let’s build this Detection System using Support Vector Machines.
SMS Spam Detector
So, what is this Spam Detector?
A spam detector is software that will detect any message as spam or not spam. This type of software is very useful to protect people from fraud. As in today’s time, there are a lot of people out there in the world who send people fraud SMS to make fool of them. These SMS contains various kinds of schemes like making money daily or some sort of these things. But all these messages are there to get money out of your pocket.
These SMS are created in such a way that it is hard to detect whether these are real or spam messages for a normal person. That’s why most people get caught in these fraud schemes and lose their hard-earned money. It’s not just about money, there are other types of fraud too that takes place just through SMS.
So it is very necessary to have a system that will detect whether a message is a spam or not.
The Model Architecture
So, how are we going to build such a system that can classify SMS as spam or not spam?
The idea is that all these spammed messages contain some kinds of keywords that are common in spam messages. These keywords such as ‘cheap’, ‘sale’, ‘needy’, etc. We are going to train our model to detect these kinds of words in the sentences and then we are going to classify it as spam or not spam.
So, as you can see it is a classification problem. We can use any classification algorithm in this problem. Most of them will work. But the problem is that these algorithms work on numerical data and not on text data. So we need to convert the words into some sort of numeric data.
For this, we are going to use CountVectorizer which will convert the text data into numeric data. The count Vectorizer has already been explained above in the article.
For this project, we are going to use support vector machines. The reason for choosing the SVM is that it seems to work best for most classification problems.
What is SVM?
SVM is called Support Vector Machines. SVM is an important algorithm in machine learning that is used for classification problems.
SVM is a tool to find a hyperplane in an n-dimensional space that divides the points into two groups, one on either side of the plane. The hyperplane depends upon the number of features. For a 2D space, the hyperplane is a line. For a 3D space, a hyperplane is a 2D plane.
SVM works in a way that it tries to find a hyperplane that can maximize the space between the points. These points in the space are called support vectors. That’s why this algorithm is named Support Vector Machines.
And the distance between the hyperplane and the support vectors is called the margins.
There are two types of SVM:
Linear and Non-linear
- Linear – The Linear SVM is the type of SVM in which the support vectors can be separated linearly by a line.
- NonLinear – The non-linear SVM is the type of SVM in which the support vectors can not be separated linearly by a line. In this, the hyperplane formed can be a circle, hyperbola, etc.
For non-linear problems, we can use kernels. The kernel is a type of function that is used for converting the lower dimensional into a higher dimension problem because separation gets easy when it gets converted into higher dimensions.
So, we are going to first convert the raw SMS text into simple words by removing any kind of punctuation or stop words and keeping only the words that will be helpful in classifying the SMS as spam or not spam. After that, we divide the dataset into training and testing data and fit it into a model that we will create using the Keras library.
This is how we will create our model.
Project Prerequisites
This project requires Python 3.6 to be installed on your computer. The project was completed using a Google Colab notebook. Any notebook will do.
The required modules for this project are –
- Pandas – pip install pandas
- Numpy – pip install numpy
- Nltk – pip install nltk
These are all the libraries that we need for our project.
Spam Detection Project
Please download spam detection machine learning project code and dataset from the following link: Spam Detection Project
Steps to Implement Spam Detection using SVM
1. Import the Modules
import numpy as np from sklearn.preprocessing import LabelEncoder import pandas as pd import nltk import string from sklearn.feature_extraction.text import CountVectorizer from sklearn import svm from sklearn.model_selection import GridSearchCV from nltk.stem.porter import PorterStemmer from sklearn.feature_extraction.text import TfidfVectorizer ps = PorterStemmer()
2. Here we are reading our spam.csv files using pandas
df = pd.read_csv('spam.csv')
df

3. Here we are removing the duplicate rows and keeping only the first one. Also, we are using Label Encoder to assign numbers to labels.
0- not spam
1- spam
encoder = LabelEncoder() df['Label'] = encoder.fit_transform(df['Label']) df = df.drop_duplicates(keep='first')
4. Here, we are creating the functions to extract important features from the text. We are removing any type of punctuation or stop words like the, he, she, etc. Stop words are the words that contribute in the formation of the sentences but these are not useful in detecting whether our SMS is spam or not.
We are also using the potter stem function. This is used to bring all the words to the root. That means, suppose we have words as teaching, teach, taught. These all have the same meaning so we are using the potter stem function which will convert all these words into the root word for example ‘teach’ in our case. If we don’t do this then CountVector will treat them as different words and make separate columns for them and they will be treated as words with different meanings but this is not true.
def get_importantFeatures(sent):
sent = sent.lower()
returnList = []
sent = nltk.word_tokenize(sent)
for i in sent:
if i.isalnum():
returnList.append(i)
return returnList
def removing_stopWords(sent):
returnList = []
for i in sent:
if i not in nltk.corpus.stopwords.words('english') and i not in string.punctuation:
returnList.append(i)
return returnList
def potter_stem(sent):
returnList = []
for i in sent:
returnList.append(ps.stem(i))
return " ".join(returnList)
5. Here, we are just applying the above functions.
df['imp_feature'] = df['EmailText'].apply(get_importantFeatures) df['imp_feature'] = df['imp_feature'].apply(removing_stopWords) df['imp_feature'] = df['imp_feature'].apply(potter_stem)
6. Here, we are using the train_test_split function to convert our dataset into training and testing.
from sklearn.model_selection import train_test_split X = df['imp_feature'] y = df['Label'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
7. Here we are creating our SVM model using inbuilt function of keras.
tfidf = TfidfVectorizer()
feature = tfidf.fit_transform(X_train)
tuned_parameters = {'kernel':['linear','rbf'],'gamma':[1e-3,1e-4], 'C':[1,10,100,1000]}
model = GridSearchCV(svm.SVC(),tuned_parameters)
model.fit(feature, y_train)
8. Here, we are finally predicting the result. Also, we are using pickle to save our trained model. Later we will use this model in Tkinter to create GUI.
y_predict = cv.transform(X_test)
print("Accuracy:",model.score(y_predict,y_test))
import pickle
filename = 'finalized_model.sav'
pickle.dump(model, open(filename, 'wb'))

9. The code below is the code for creating the GUI of our project. The GUI is created using Tkinter. In the GUI, I have created two labels and a text field where the user will get the input text. Then, after clicking the submit button, it will call the function check_spam() which will check whether the input text is spam or not.
from tkinter import *
import tkinter as tk
spam_model = pickle.load(open("finalized_model.sav",'rb'))
def check_spam():
text = spam_text_Entry.get()
is_spam = spam_model.predict(tfidf.transform([text]))
if is_spam == 1:
print("text is spam")
my_string_var.set("Result: text is spam")
else:
print("text is not spam")
my_string_var.set("Result: text is not spam")
win = Tk()
win.geometry("400x600")
win.configure(background="cyan")
win.title("Sms Spam Detector")
title = Label(win, text="SMS Spam Detector", bg="gray",width="300",height="2",fg="white",font=("Calibri 20 bold italic underline")).pack()
spam_text = Label(win, text="Enter your Text: ",bg="cyan", font=("Verdana 12")).place(x=12,y=100)
spam_text_Entry = Entry(win, textvariable=spam_text,width=33)
spam_text_Entry.place(x=155, y=105)
my_string_var = StringVar()
my_string_var.set("Result: ")
print_spam = Label(win, textvariable=my_string_var,bg="cyan", font=("Verdana 12")).place(x=12,y=200)
Button = Button(win, text="Submit",width="12",height="1",activebackground="red",bg="Pink",command=check_spam,font=("Verdana 12")).place(x=12,y=150)
win.mainloop()
Spam Detection Output
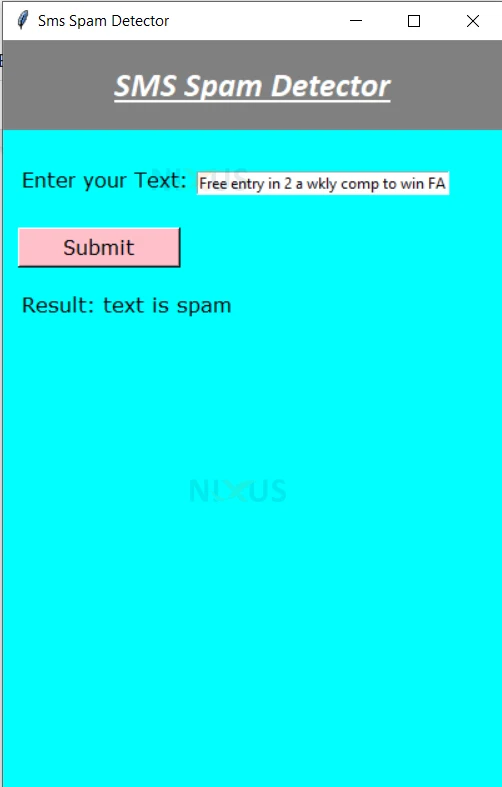
Summary
In this Machine Learning project, we built a spam detector that will detect any SMS as spam or not spam. We have used an SVM classifier for our project. We hope you like the project.