Category: Spark Tutorials
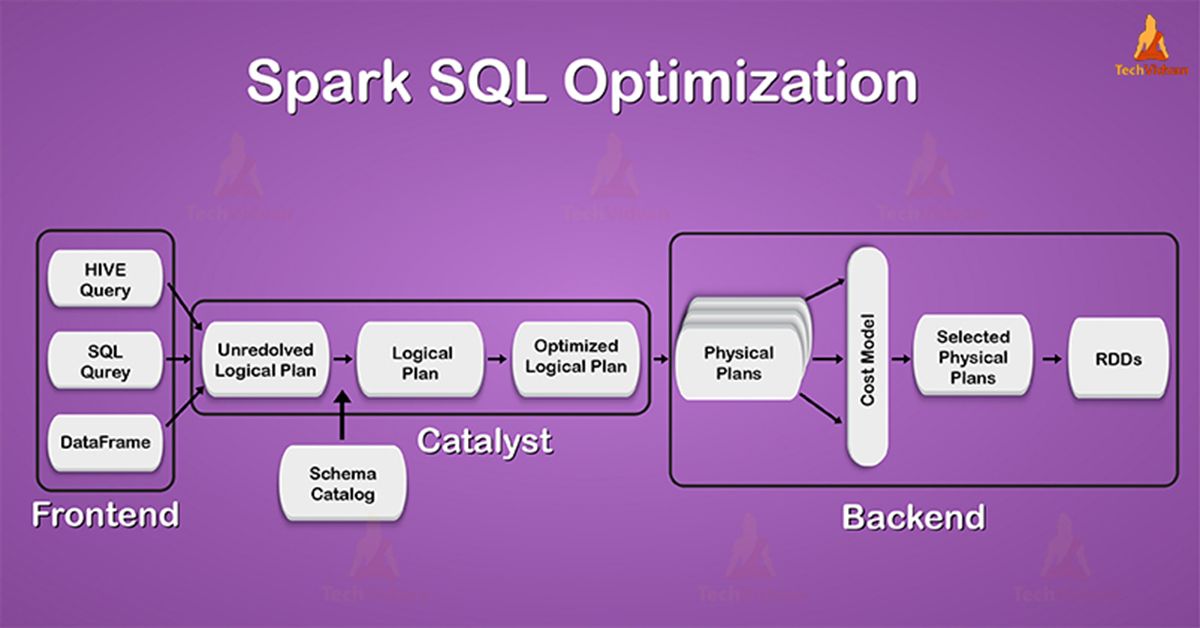
In this Spark tutorial, we will learn about Spark SQL optimization – Spark catalyst optimizer framework. Optimization refers to a process in which we use fewer resources, yet it works efficiently. We will learn,...
At a rapid pace, Apache Spark is evolving either on the basis of changes or on the basis of additions to core APIs. The most disruptive areas of change we have seen are a...
Spark SQL is Spark module that works for structured data processing. In this spark dataframe tutorial, we will learn the detailed introduction on Spark SQL DataFrame, why we need SQL DataFrame over RDD, how...
This blog completely aims to learn detailed concepts of Apache Spark SQL, supports structured data processing. Also, offers to work with datasets in Spark, integrated APIs in Python, Scala, and Java. In this sparkSQL...
Apache Spark supports the various transformation techniques. In this blog, we will learn about the Apache Spark Map and FlatMap Operation and Comparison between Apache Spark map vs flatmap transformation methods. This article is...
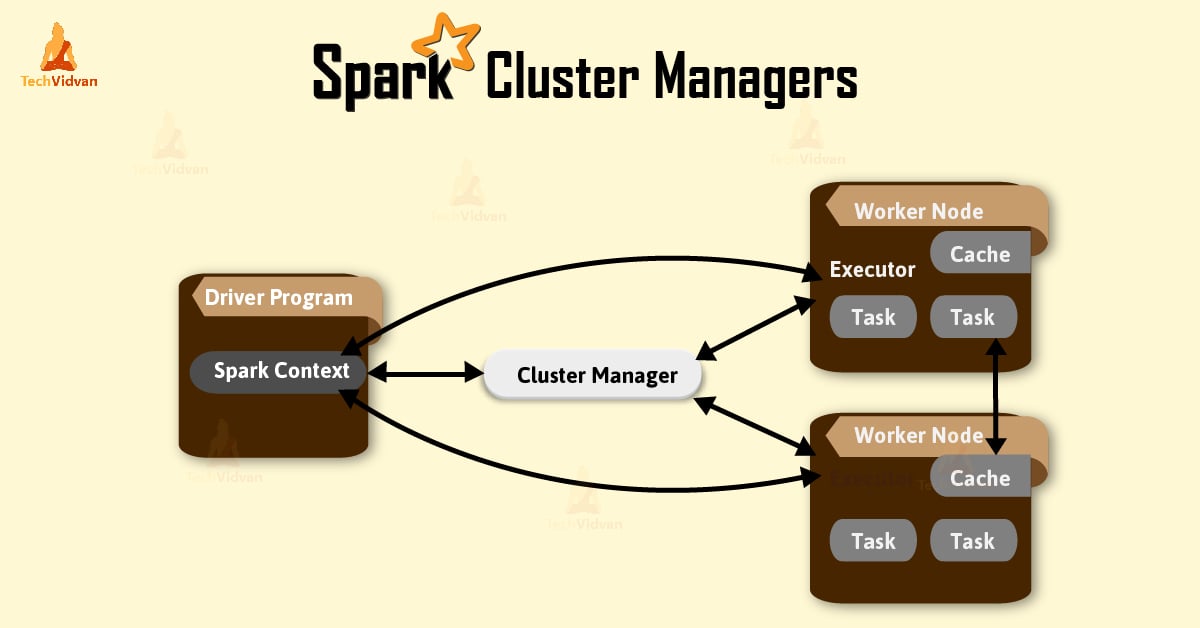
This tutorial gives the complete introduction on various Spark cluster manager. There are three Spark cluster manager, Standalone cluster manager, Hadoop YARN and Apache Mesos. Apache Spark supports these three type of cluster manager....
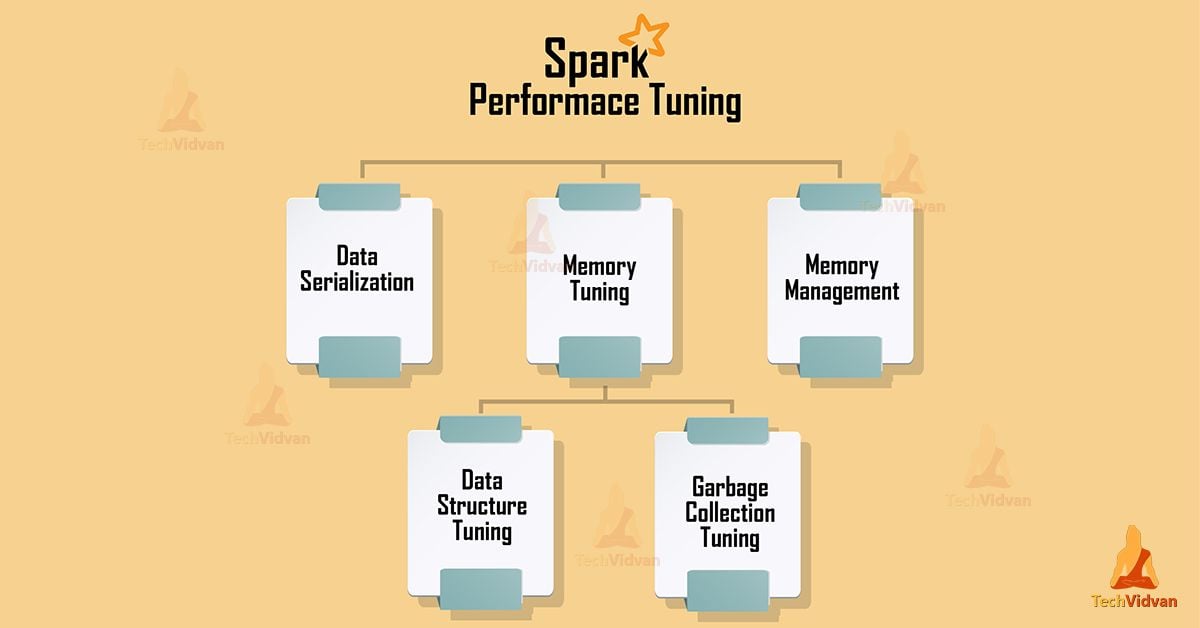
In this tutorial, we will learn the basic concept of Apache Spark performance tuning. The process of tuning means to ensure the flawless performance of Spark. This process also guarantees to prevent bottlenecking of...
As we very well know that Apache Spark is the lightning fast big data solution. Somehow, it has revealing development API’s. Spark allows data workers to do streaming, it requires continuous access to datasets....
In Apache Spark, Key-value pairs are known as paired RDD. In this blog, we will learn what are paired RDDs in Spark in detail. To understand in deep, we will focus on following methods...
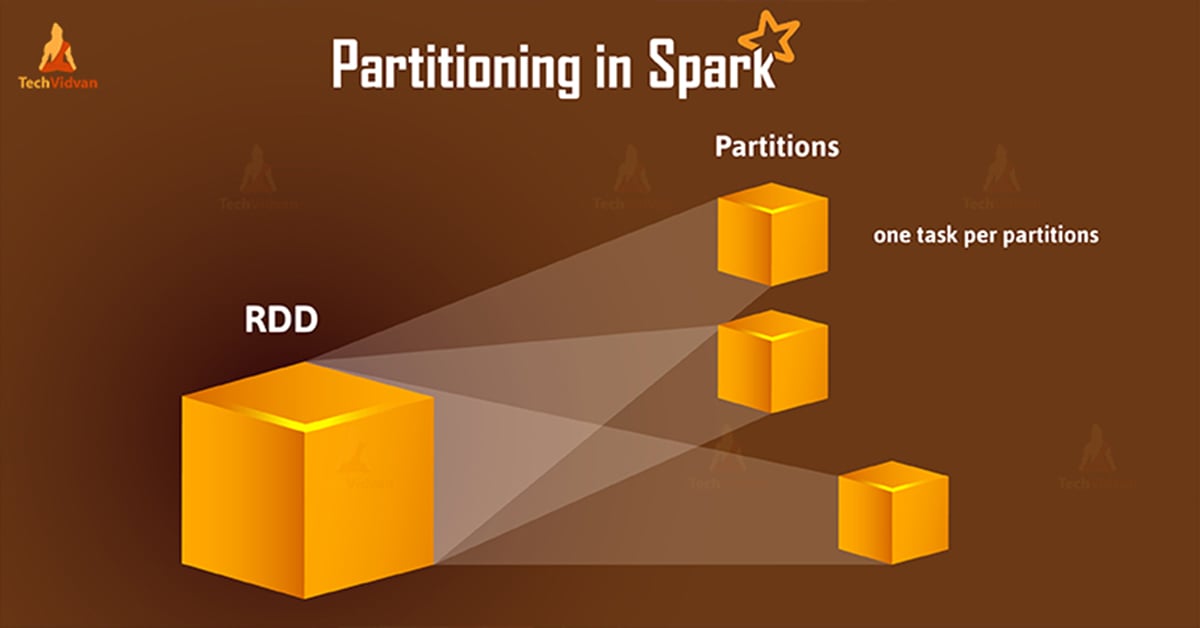
Partitioning is simply defined as dividing into parts, in a distributed system. Partitioning means, the division of the large dataset. Also, store them as multiple parts of the cluster. In this blog post, we...