Spark SQL Optimization- The Spark Catalyst Optimizer
In this Spark tutorial, we will learn about Spark SQL optimization – Spark catalyst optimizer framework. Optimization refers to a process in which we use fewer resources, yet it works efficiently.
We will learn, how it allows developers to express the complex query in few lines of code, the role of catalyst optimizer in spark. At last, we will also focus on its fundamentals of working and includes phases of Spark execution flow.
Spark Catalyst Optimizer – Spark SQL Optimization
Spark SQL Optimization
First, let’s understand the term Optimization. It means the design of the system is in a way that it works efficiently with fewer resources. One of the components of Apache Spark ecosystem is Spark SQL.
At the very core of Spark SQL is catalyst optimizer. It is based on functional programming construct in Scala. Advanced programming language feature is one of the advantages of catalyst optimizer. It includes Scala’s pattern matching and quasi quotes. Also, offers to build an extensible query optimizer.
Furthermore, catalyst optimizer in Spark offers both rule-based and cost-based optimization as well. But, In rule-based optimization, there are set of rule to determine how to execute the query. While in cost-based by using rules many plans are generated and then their cost is computed.
In addition, there is a general library to show trees and apply rules to manipulate them. There are libraries specific to relational query processing, on top of this framework, for example, expressions, logical query plans.
It also attains the various set of rules for different phases of query execution such as analysis, logical optimization, physical planning, and code generation. These are used to compile parts of queries to Java bytecode.
Moreover, it uses another Scala feature, quasi quotes. That makes it easy to generate code at runtime from composable expressions. Ultimately, catalyst offers several public extension points, including external data sources & user-defined types.
Role of Catalyst Optimizer in Apache Spark
There are two purposes to design catalyst optimizer, like:
- To add easily new optimization techniques and features to Spark SQL. For the purpose of handling various problems going with big data issues like semistructured data and advanced analytics.
- To enable external developers to extend the optimizer.
Fundamentals of Apache Spark Catalyst Optimizer
Let’s discuss the tree and rules one by one in detail-
1. Trees
Tree constituted is the main data type in a catalyst. Each node has a node and can have zero or more children. In Scala, new node types are explained as subclasses of the tree node class. Since these objects are immutable in nature. By using functional transformations, we can manipulate them easily.
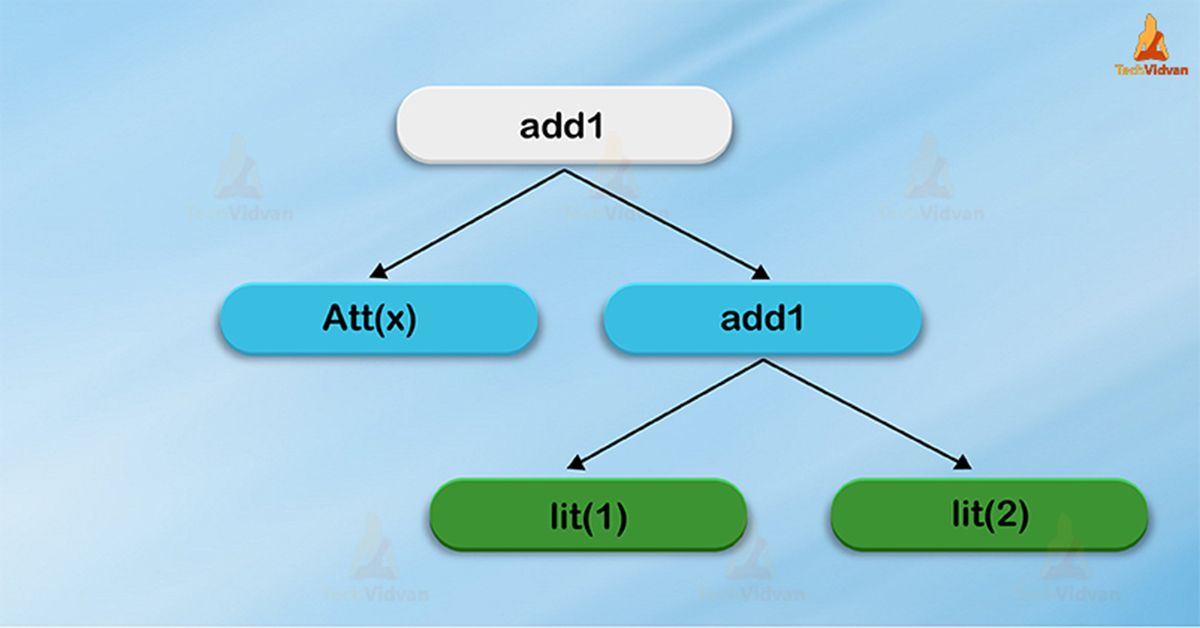
By using a simple example, suppose for a very simple expression language, we have 3 node classes:
- Lit(value: Int): a constant value
- Att(name: String): an attribute from an input row, e.g.,“x”
- Add1(left: TreeNode, right: TreeNode): sum of two expressions.
To build up trees, we use all of these, for example, we can represent a tree, for an expression like x+(1+2) in Scala code as follows:
Add(Att(x), Add(Lit(1), Lit(2)))
Fundamentals of Apache Spark Catalyst Optimizer – Spark SQL Optimization
2. Rules
By using rules, we can manipulate trees. Those are functions from a tree to another tree. By using rule we can run arbitrary code on its input tree. Moreover, this approach is to use a set of pattern matching functions.
That find and replace subtrees with a specific structure, trees offer a transform method in a catalyst. On all nodes of a tree, we apply pattern matching method recursively. Through, transforming the ones it matches each pattern to a result.
By using this example, implementing a rule, that folds add operations between constants:
For Example
tree.transform {
case Add(Lit(c1), Lit(c2)) => Lit(c1+c2)
}
On applying this to the tree for x+(1+2), it would make the new tree x+3. In this expression, case keyword is Scala’s standard pattern matching syntax, we use it to match the type of an object. It also used to give names to extracted values (c1 and c2 here).
An expression of pattern matching is passed to transform is a partial function. That means, it only needs to match to a subset of all possible input trees.
It is monitor by a catalyst, which parts of a tree is, skipping over and descending into subtrees that do not match. Therefore, as we add new types of operators to the system, so no need to modify rules.
In the same transform call, rules can match multiple patterns. It makes it very concise to implement multiple transformations at once:
tree.transform {
case Add(Lit(c1), Lit(c2)) => Lit(c1+c2)
case Add(left, Lit(0)) => left
case Add(Lit(0), right) => right
}
Furthermore, to fully transform a tree, rules may need to execute multiple times. Catalyst groups rules into batches, it executes each batch until it reaches a fixed point. In other words, until the tree stops changing after applying its rules.
Ultimately, rule conditions contain arbitrary Scala code. It provides catalyst more power than domain-specific languages for optimizers while keeping it concise for simple rules.
While on immutable trees, it applies functional transformations. That makes the optimizer very easy to debug. Also, enables parallelization in the optimizer.
Using Catalyst in Spark SQL
There are 4 phases in which we can use catalyst’s general tree transformation framework. This is list-up below:
- By analyzing a logical plan to resolve references.
- With logical plan optimization.
- By Physical Planning.
- With code generation to compile parts of the query to Java bytecode.
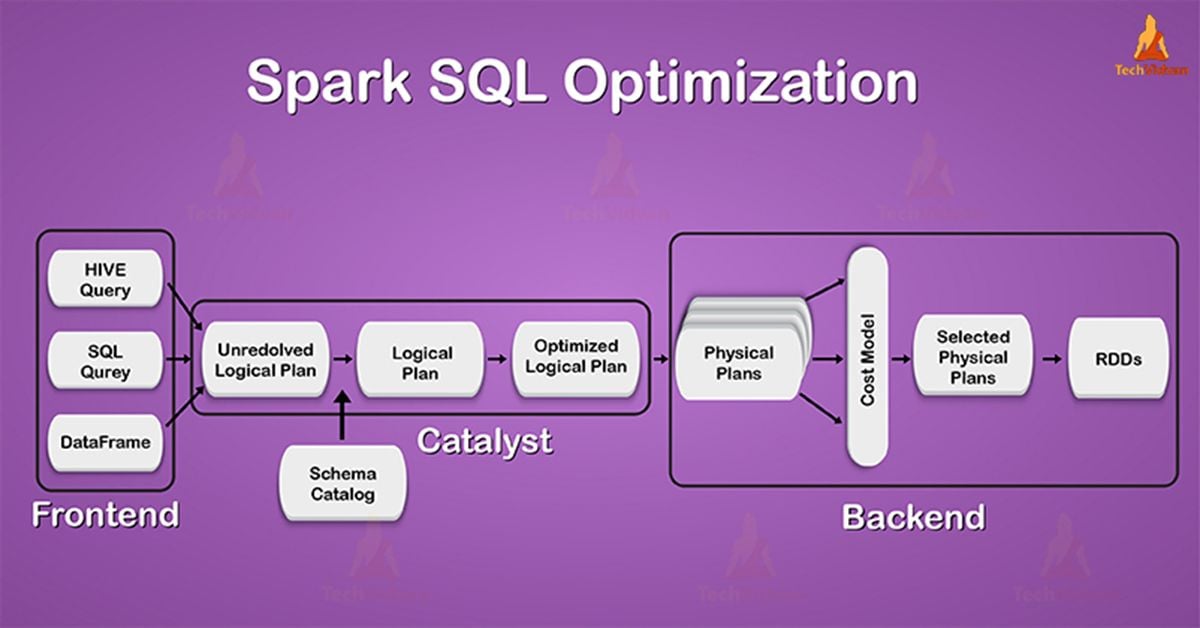
In the third phase, which is physical planning catalyst may generate many plans. They also compare them on the basis of cost. All phases are rule-based except this phase. In each phase, it uses different types of tree nodes. Let’s now discuss each of these phases.

Spark SQL Optimization – Spark Execution plan
1. Analysis
The first phase Spark SQL optimization is analysis. Initially, Spark SQL starts with a relation to be computed. It can be computed by two possible ways, either from an abstract syntax tree (AST) returned by a SQL parser. Using API, a second way is from a dataframe object constructed.
Moreover, on applying any case the relation remains unresolved attribute relations such as, in the SQL query SELECT col FROM sales, or even if it is a valid column name, is not known, until we look up the table.
An attribute remains unresolved if we do not know its type to an input table. To resolve these, SQL uses catalyst rules that track tables in all data sources. It begins by building an “unresolved logical plan” tree with attributes & data types. Afterwards, applies rules that do the following :
– Searching relations as the name of the catalog.
– On mapping named attributes.
– When determining which attributes is similar to a value gives them a unique ID.
– By propagating and pushing types through expressions
2. Logical Optimization
It is the second phase of Spark SQL optimization. In this phase, we apply standard rule-based optimization to the logical plan. There are several rules in this process, for example, predicate pushdown, constant folding and many other rules. Ultimately, it became very easy to add a rule for various situations.
Spark Catalyst Optimizer- Physical Planning
In physical planning rules, there are about 500 lines of code. From the logical plan, we can form one or more physical plan, in this phase. Actually, by using the cost mode, it selects the plan. Only to select join algorithms, it uses cost-based optimization.
The framework supports broader use of cost-based optimization, especially for all relations which are small. Moreover, By using this rule, it can estimate the cost recursively for the whole tree.
Pipelining projections or filters operation, which is physical optimization is also carried out. These projections are rule-based optimizations and it can push operations from the logical plan into data sources. That support predicate or projection pushdown.
Code Generation In Spark Catalyst Optimizer
The code generation is the final phase of SparkSQL optimization. To run on each machine, generation of Java bytecode is involved in it. Also, make code generation easier, as catalyst uses the special Scala feature, “Quasiquotes”. Else, it is very tough to build code generation engines.
We can construct of abstract syntax trees (ASTs) in Scala, using Quasi-quotes. That can be given to the Scala compiler at runtime to generate bytecode. Furthermore, We can easily transform a tree representing an expression in SQL to an AST.
Especially, for Scala code by using a catalyst. Also, helps to evaluate that expression and then compile and run the generated code.
Conclusion
In this blog post, we have covered the internals of Catalyst optimizer in SparkSQL. As a result, use of SQL optimization increases the performance of the queries that they write. Therefore, in Spark SQL optimization enhances the productivity of developers.