Introduction on Apache Spark SQL DataFrame
Spark SQL is Spark module that works for structured data processing.
In this spark dataframe tutorial, we will learn the detailed introduction on Spark SQL DataFrame, why we need SQL DataFrame over RDD, how to create SparkSQL DataFrame, Features of DataFrame in Spark SQL: such as custom memory management, optimized execution plan.
To understand better, we will highlight the limitations of Spark SQL Dataframe also.
Introduction to Spark SQL DataFrame
DataFrames are datasets, which is ideally organized into named columns. We can construct dataframe from an array of different sources, like structured data files, hive tables, external databases, or existing RDDs. DataFrames are equal to a table in a relational database or a dataframe in R/Python with good optimizations.
Dataframe is used, for processing of a large amount of structured data. Basically, it contains rows with a schema. Moreover, that schema is nothing but the illustration of the structure of data. It is more powerful than RDD but it attains features of RDD as well.
There are several features those are common to RDD, such as distributed computing capability, immutability, in-memory, resilient. Also, provides higher level abstraction. Generally, it allows users to impose the structure onto a distributed data collection.
It’s API is available on several platforms, such as Scala, Java, Python, and R as well. While we work with Scala and Java, it is represented by a dataset of rows.
Distinctly, dataframe is simply a type alias of dataset[Row] in Scala API. Whereas, users need to use dataset<Row> to represent a dataframe in Java API.
Why DataFrame?
There is always a question which strikes my mind that if we already have RDD, why do we need dataframe than? But, As we discussed earlier, dataframe is one step ahead of RDD. RDD has following limitations, such as:
-
Limitations of RDD
- There is no built-in optimization engine in RDD.
- RDD cannot handle structured data.
These are the following drawbacks, due to which Spark SQL dataframe comes in picture. Dataframe overcomes limitations of RDD as it provides memory management and optimized execution plan. This feature is not available in RDD. Let’s discuss them in detail:
1. Custom Memory Management:
In custom memory management, memory (as data) is stored in off-heap memory in binary format, this process is tungsten project. There is no garbage collection overhead, in memory management. There is no expensive java serialization.
2. Optimized Execution plan:
The other name of this process is query optimizer. An optimized execution plan is created, for the execution of a query. When an optimized plan is created, then only final execution takes place on RDDs.
Features of DataFrame
There are several features of dataframe, such as:
- Dataframes are able to process the data in different sizes, like the size of kilobytes to petabytes on a single node cluster to large cluster.
- It is a distributed collection of data organized in a named column, it is as similar to a table in RDBMS.
- They support different data formats, such as Avro, csv, elastic search, and Cassandra. It also provides storage systems like HDFS, HIVE tables, MySQL, etc.
- The optimizer called as catalyst optimizer supports optimization. Basically, to represent trees, there are general libraries available.
- By analyzing logical plan to solve references.
- With logical plan optimization.
- By physical planning.
- With code generation to compile part of a query to java bytecode.
- We can integrate dataframe with all big data tools and frameworks by spark-core.
- Dataframe provides several API, such as Python, Java, Scala, and R programming.
- It is compatible with a hive. It is possible to run unmodified hive queries on existing hive warehouse.
Creating DataFrames
There are many ways through which we can create a dataframe:
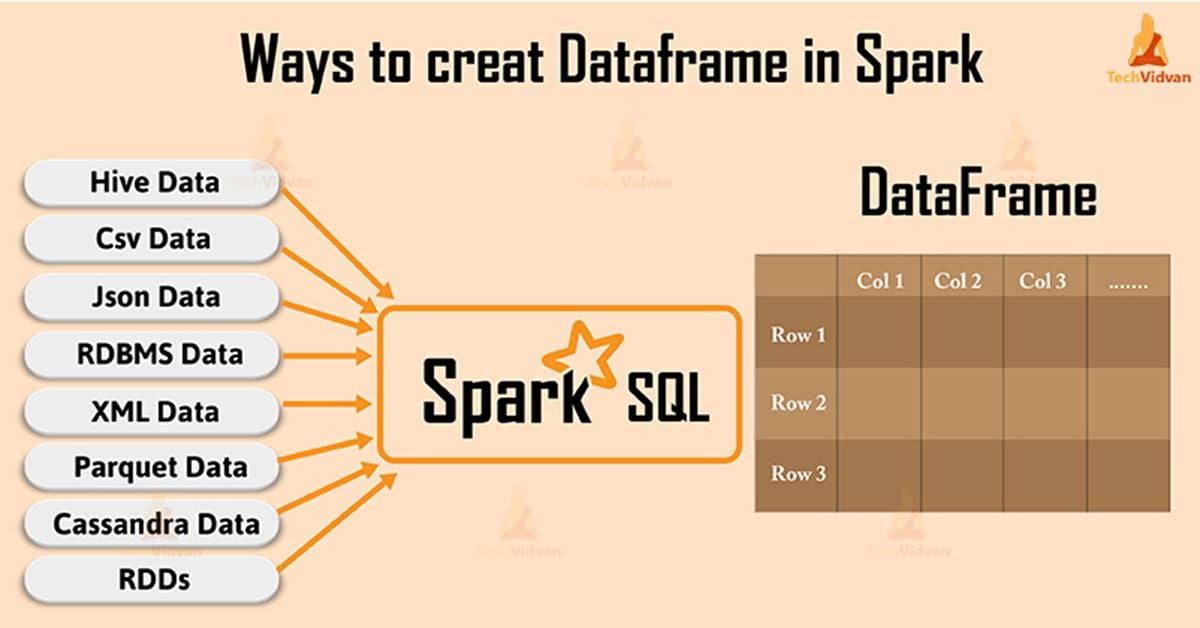
Ways To Create Dataframe In Spark
- We can create it by using different dataformats, such as loading the data from JSON, CSV.
- It is also possible by loading data from existing RDD.
By using Spark session, an application can create dataframe from an existing RDD. It is also possible to create it from hive table or from Spark data sources.
To access the functionality of Spark, we need to create the Spark session class. It is the entry point, to create basic Spark session, we can use the following command:
SparkSession.builder()
By using dataframe interface, Spark SQL can operate on the variety of data sources. We can create a temporary view of using dataframe.in Spark SQL. To run the SQL query on the data, we will need the temporary view of the data frame.
Limitations of SparkSQL DataFrames
There are also some limitations of dataframes in Spark SQL, like:
- In SQL dataframe, there is no compile-time type safety. Hence, as the structure is unknown, manipulation of data is not possible.
- We can convert domain object into dataFrame. But once we do it, then we can not regenerate the domain object.
Conclusion
As a result, we have seen that SQL dataframe API is different from the RDD API. Developers who are familiar with building query plans, for them dataframe API is good. But due to its limitations, it is not good for the majority of developers.
Apparently, it avoids the garbage-collection cost for each row in the dataset. Therefore, dataframe API in Spark SQL improves the performance and scalability of Spark.