Apache Spark Cluster Manager: YARN, Mesos and Standalone
This tutorial gives the complete introduction on various Spark cluster manager. There are three Spark cluster manager, Standalone cluster manager, Hadoop YARN and Apache Mesos. Apache Spark supports these three type of cluster manager.
We will also highlight the working of Spark cluster manager in this document. In closing, we will also learn Spark Standalone vs YARN vs Mesos.
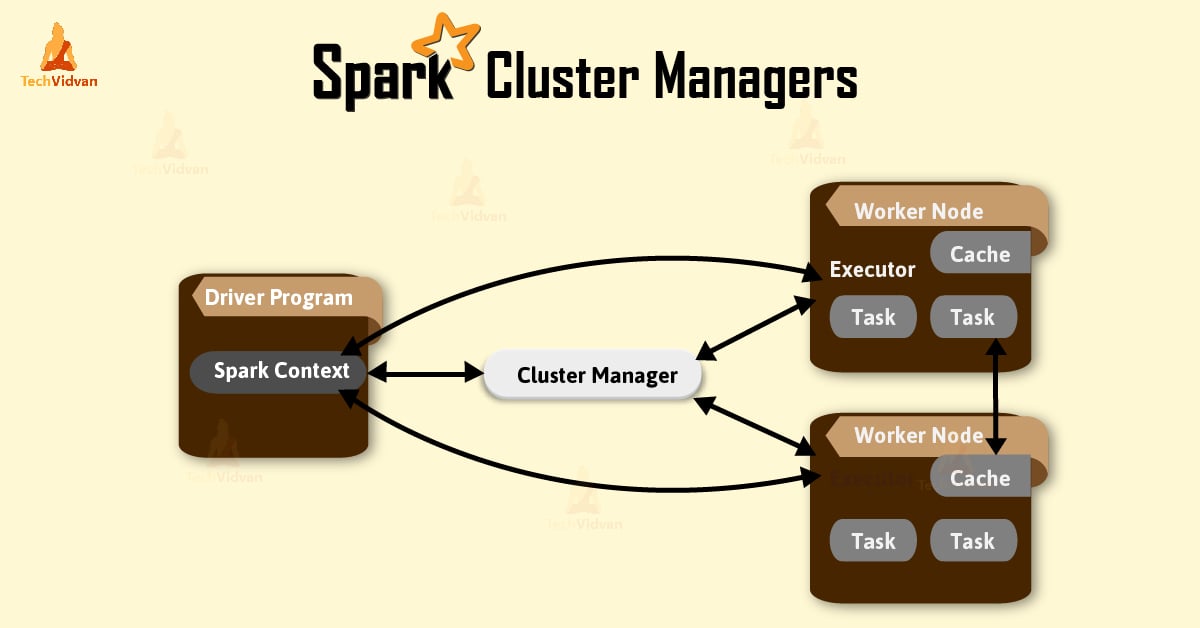
What is Cluster Manager in Apache Spark?
Cluster manager is a platform (cluster mode) where we can run Spark. Simply put, cluster manager provides resources to all worker nodes as per need, it operates all nodes accordingly.
We can say there are a master node and worker nodes available in a cluster. That master nodes provide an efficient working environment to worker nodes.
There are three types of Spark cluster manager. Spark supports these cluster manager:
- Standalone cluster manager
- Hadoop Yarn
- Apache Mesos
Apache Spark also supports pluggable cluster management. The main task of cluster manager is to provide resources to all applications. We can say it is an external service for acquiring required resources on the cluster.
Let’s discuss all these cluster managers in detail:
1. Standalone Cluster Manager
It is a part of spark distribution and available as a simple cluster manager to us. Standalone cluster manager is resilient in nature, it can handle work failures. It has capabilities to manage resources according to the requirement of applications.
We can easily run it on Linux, Windows, or Mac. It can also access HDFS (Hadoop Distributed File System) data. This is the easiest way to run Apache spark on this cluster. It also has high availability for a master.
Working with Standalone Cluster Manager
As we discussed earlier, in cluster manager it has a master and some number of workers. It has available resources as the configured amount of memory as well as CPU cores. In this cluster, mode spark provides resources according to its core. We can say an application may grab all the cores available in the cluster by default.
If in any case, our master crashes, so zookeeper quorum can help on. It recovers the master using standby master. We can also recover the master by using several file systems. All the applications we are working on has a web user interface.
This interface works as an eye keeper on the cluster and even job statistics. It helps in providing several pieces of information on memory or running jobs.
This cluster manager has detailed log output for every task performed. Web UI can reconstruct the application’s UI even after the application exits.
2. Hadoop Yarn
This cluster manager works as a distributed computing framework. It also maintains job scheduling as well as resource management. In this cluster, masters and slaves are highly available for us. We are also available with executors and pluggable scheduler.
We can also run it on Linux and even on windows. Hadoop yarn is also known as MapReduce 2.0. It also bifurcates the functionality of resource manager as well as job scheduling.
Working with Hadoop Yarn Cluster Manager
If we talk about yarn, whenever a job request enters into resource manager of YARN. It computes that according to the number of resources available and then places it a job. Yarn system is a plot in a gigantic way.
It is the one who decides where the job should go. This is an evolutionary step of MapReduce framework. It works as a resource manager component, largely motivated by the need to scale Hadoop jobs.
We can optimize Hadoop jobs with the help of Yarn. The yarn is the aim for short but fast spark jobs. It is neither eligible for long-running services nor for short-lived queries. It is not stated as an ideal system.
That resource demand, execution model, and architectural demand are not long running services. The yarn is suitable for the jobs that can be re-start easily if they fail. Yarn do not handle distributed file systems or databases.
While yarn massive scheduler handles different type of workloads. The yarn is not a lightweight system. It is not able to support growing no. of current even algorithms.
3. Apache Mesos
It is a distributed cluster manager. As like yarn, it is also highly available for master and slaves. It can also manage resource per application. We can run spark jobs, Hadoop MapReduce or any other service applications easily.
Apache has API’s for Java, Python as well as c++. We can run Mesos on Linux or Mac OSX also.
Working with Apache Mesos Cluster Manager
Now, let’s look at what happens over on the Mesos side. It determines the availability of resources at first. Then it makes offer back to its framework. Even there is a way that those offers can also be rejected or accepted by its framework.
This is a two level scheduler model in which schedulings are pluggable. This model is also considered as a non-monolithic system. It allows an infinite number of scheduled algorithms.
This is only possible because it can also decline the offers. So it can accommodate thousand number of schedules on the same cluster.
As we discussed, it supports two-level scheduling. So it decides which algorithm it wants to use for scheduling the jobs that it requires to run. This model is somehow like the live example that how we run many apps at the same time on a laptop or smartphone.
Mesos is the arbiter in nature. It can control all applications. One of the best things about this model on basis of years of the operating system. It is a distributed systems research which is very scalable.
Comparison between Spark Standalone, YARN and Mesos
There are following points through which we can compare all three cluster managers. They are mention below:
1. High Availability (HA)
As we discussed earlier in standalone manager, there is automatic recovery is possible. By using standby masters in a ZooKeeper quorum recovery of the master is possible.
We can also recover master manually using the file system, this cluster is resilient in nature. It helps the worker failures regardless of whether recovery of the master is enabled or not.
The mesos cluster manager also supports ZooKeeper to the recovery of a master. It also enables recovery of the master. In the case of any failure, Tasks can run continuously those are currently executing.
Apache Hadoop YARN supports both manual recovery and automatic recovery through Zookeeper resource manager. Manual recovery means using a command line utility.
Thus, like mesos and standalone manager, no need to run separate ZooKeeper controller. In this system to record the state of the resource managers, we use ZooKeeper.
2. Security
Like Apache Spark supports authentication through shared secret for all these cluster managers. In the standalone manager, it is a need that user configures each of the nodes with the shared secret only. We use SSL(Secure Sockets Layer) to encrypt data for the communication protocols.
For block transfers, SASL(Simple Authentication and Security Layer) encryption is supported. We also have other options for data encrypting. To access the Spark applications in the web user interface, access control lists can be used.
In Mesos for any entity interacting with the cluster, it provides authentication. This includes the slaves even the master, applications on cluster and operators. These entities can be authorized by the user to use authentication or not.
In Mesos, access control lists are used to allow access to services. In Mesos communication between the modules is already unencrypted. To encrypt this communication SSL(Secure Sockets Layer) can be enabled.
Hadoop YARN allow security for authentication, service authorization, for web and data security. In Hadoop for authentication, we use Kerberos. To verify each user and service is authenticated by Kerberos.
Kerberos means a system for authenticating access to distributed service level in Hadoop. We can control the access to the Hadoop services via access control lists. We can encrypt data and communication between clients and services using SSL. It encrypts da

ta transferred between the web console and clients by HTTPS.
3. Monitoring
In every Apache Spark application, we have web UI to track each application. That web UI shows information about tasks, jobs, executors, and storage usage. In Spark’s standalone cluster manager we can see the detailed log output for jobs. It can also view job statistics and cluster by available web UI.
In Apache Mesos, we can access master and slave nodes by URL which have metrics provided by mesos.
In Hadoop YARN we have a Web interface for resourcemanager and nodemanager. Node manager defines as it provides information to each node. In a resource manager, it provides metrics over the cluster.
Conclusion
As a result, we have seen that among all the Spark cluster managers, Standalone is easy to set. Also, provides all same features which are available to other Spark cluster managers. If we need many numbers of resource scheduling we can opt for both YARN as well as Mesos managers.
One of the benefits of YARN is that it is pre-installed on Hadoop systems. We can say one advantage of Mesos over others, supports fine-grained sharing option. Finally, Apache Spark is agnostic in nature. So deciding which manager is to use depends on our need and goals.