What is Hadoop Mapper Class in MapReduce?
In this blog, we will provide you the complete introduction of Hadoop Mapper. I
In this blog, we will answer what is Mapper in Hadoop MapReduce, how hadoop mapper works, what are the process of mapper in Mapreduce, how Hadoop generates Key-value pair in MapReduce.
Introduction to Hadoop Mapper
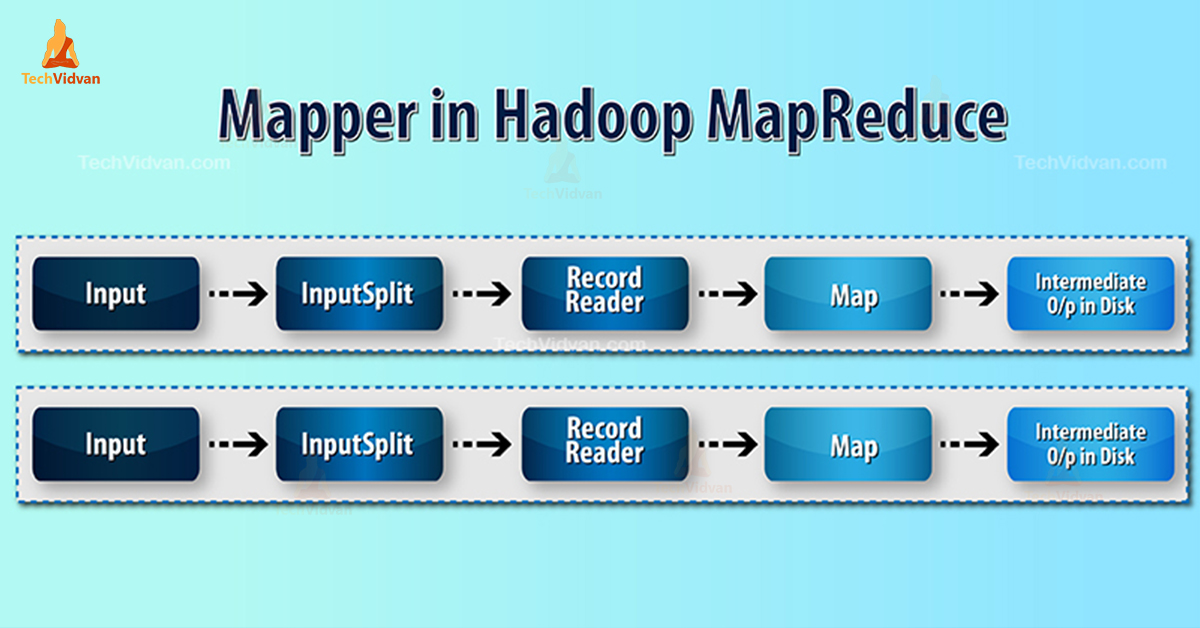
Hadoop Mapper processes input record produced by the RecordReader and generates intermediate key-value pairs. The intermediate output is completely different from the input pair.
The output of the mapper is the full collection of key-value pairs. Before writing the output for each mapper task, partitioning of output take place on the basis of the key. Thus partitioning itemizes that all the values for each key are grouped together.
Hadoop MapReduce generates one map task for each InputSplit.
Hadoop MapReduce only understands key-value pairs of data. So, before sending data to the mapper, Hadoop framework should covert data into the key-value pair.
How is key-value pair generated in Hadoop?
As we have understood what is mapper in hadoop, now we will discuss how Hadoop generate key-value pair?
- InputSplit – It is the logical representation of data generated by the InputFormat. In MapReduce program, it describes a unit of work that contains a single map task.
- RecordReader- It communicates with the inputSplit. And then converts the data into key-value pairs suitable for reading by the Mapper. RecordReader by default uses TextInputFormat to convert data into the key-value pair.
Mapper Process in Hadoop MapReduce
InputSplit converts the physical representation of the blocks into logical for the Mapper. For example, to read the 100MB file, it will require 2 InputSplit. For each block, the framework creates one InputSplit. Each InputSplit create one mapper.
MapReduce InputSplit not always depends on the number of data blocks. We can change the number of a split by setting mapred.max.split.size property during job execution.
MapReduce RecordReader is responsible for reading/converting data into key-value pairs till the end of the file. RecordReader assigns Byte offset to each line present in the file.
Then Mapper receives this key pair. Mapper produces the intermediate output (key-value pairs which are understandable to reduce).
How many Map task in Hadoop?
The number of map tasks depends on the total number of blocks of the input files. In MapReduce map, the right level of parallelism seems to be around 10-100 maps/node. But there is 300 map for CPU-light map tasks.
For example, we have a block size of 128 MB. And we expect 10TB of input data. Thus it produces 82,000 maps. Hence the number of maps depends on InputFormat.
Mapper = (total data size)/ (input split size)
Example – data size is 1 TB. Input split size is 100 MB.
Mapper = (1000*1000)/100 = 10,000
Conclusion
Hence, Mapper in Hadoop takes a set of data and converts it into another set of data. Thus, it breaks individual elements into tuples (key/value pairs).
Hope you like this block, if you have any query for Hadoop mapper, so please leave a comment in a section given below. We will be happy to solve them.