What is MapReduce Key Value Pair in Hadoop?
In this Hadoop tutorial, we are going to provide you a complete introduction to MapReduce Key Value Pair.
First of all we will discuss what is a key value pair in Hadoop, How key value pair is generated in MapReduce. At last we will explain MapReduce key value pair generation with examples.
What is Key Value Pair in Hadoop?
Key-value pair in MapReduce is the record entity that Hadoop MapReduce accepts for execution.
We use Hadoop mainly for data Analysis. It deals with structured, unstructured and semi-structured data. With Hadoop, if the schema is static we can directly work on the column instead of key value. But, if the schema is not static we will work on a key value.
Keys value is not the intrinsic properties of the data. But they are chosen by user analyzing the data.
MapReduce is the core component of Hadoop, which provides data processing. It performs processing by breaking the job by into two phases: Map phase and Reduce phase. Each phase has key-value as input and output.
MapReduce Key value pair generation in Hadoop
In MapReduce job execution, before sending data to the mapper, first convert it into key-value pairs. Because mapper only key-value pairs of data.
Key-value pair in MapReduce is generated as follows:
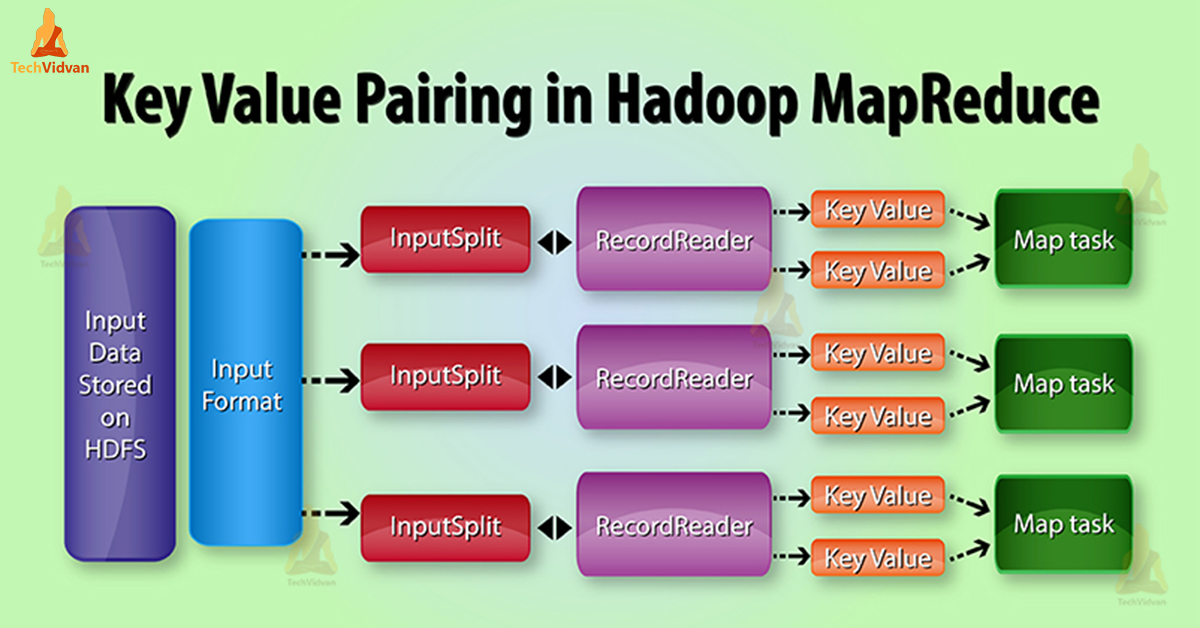
InputSplit – It is the logical representation of data which InputFormat generates. In MapReduce program it describes a unit of work that contains a single map task.
RecordReader – It communicates with the InputSplit. After that it converts the data into key value pairs suitable for reading by the Mapper. RecordReader by default uses TextInputFormat to convert data into key value pairs.
In MapReduce job execution, the map function processes a certain key-value pair. Then emits a certain number of key-value pairs. The Reduce function processes the values grouped by the same key.
Then emits another set of key-value pairs as the output. The Map output types should match the input types of the Reduce as shown below:
- Map: (K1, V1) -> list (K2, V2)
- Reduce: {(K2, list (V2}) -> list (K3, V3)
On what basis is a key-value pair generated in Hadoop?
MapReduce Key-value pair generation totally depends on the data set. Also depends on the required output. Framework specifies key-value pair in 4 places: Map input/output, Reduce input/output.
1. Map Input
Map Input by default takes the line offset as the key. The content of the line is value as Text. We can modify them; by using the custom input format.
2. Map Output
The Map is responsible to filter the data. It also provides the environment to group the data on the basis of key.
- Key– It is field/ text/ object on which the data groups and aggregates on the reducer.
- Value– It is the field/ text/ object which each individual reduces method handles.
3. Reduce Input
Map output is input to reduce. So it’s same as Map-Output.
4. Reduce Output
It totally depends on the required output.
MapReduce Key-value Pair Example
For example, the content of the file which HDFS stores are Chandler is Joey Mark is John. So, now by using InputFormat, we will define how this file will split and read. By default, RecordReader uses TextInputFormat to convert this file into a key-value pair.
- Key – It is offset of the beginning of the line within the file.
- Value – It is the content of the line, excluding line terminators.
Here, Key is 0 and Value is Chandler is Joey Mark is John.
Conclusion
In conclusion, we can say that, key-value is just a record entity that MapReduce accepts for execution. InputSplit and RecordReader generate Key-value pair. Hence, the key is byte offset and value is the content of the line.
Hope you liked this blog. If you have any suggestion or query related to MapReduce key value pair so please leave a comment in a section given below.