Hadoop MapReduce Tutorial for Beginners
If you want to know everything about Hadoop MapReduce, you have landed in the right place. This MapReduce Tutorial provides you the complete guide about each and everything in Hadoop MapReduce.
In this MapReduce Introduction, you will explore what Hadoop MapReduce is, How the MapReduce framework works. The article also covers MapReduce DataFlow, Different phases in MapReduce, Mapper, Reducer, Partitioner, Cominer, Shuffling, Sorting, Data Locality, and many more.
We have also enlisted the advantages of the MapReduce framework.
Let us first explore why we need Hadoop MapReduce.
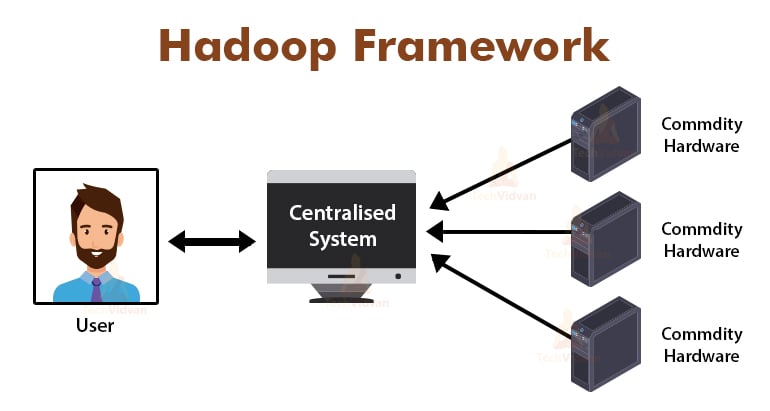
Why MapReduce?

The above figure depicts the schematic view of the traditional enterprise systems. The traditional systems normally have a centralized server for storing and processing data. This model is not suitable for processing huge amounts of scalable data.
Also, this model could not be accommodated by the standard database servers. Additionally, the centralized system creates too much bottleneck while processing multiple files simultaneously.
By using the MapReduce algorithm, Google solved this bottleneck issue. The MapReduce framework divides the task into small parts and assigns tasks to many computers.
Later on, the results are collected at a commonplace and are then integrated to form the result dataset.
Introduction to MapReduce Framework
MapReduce is the processing layer in Hadoop. It is a software framework designed for processing huge volumes of data in parallel by dividing the task into the set of independent tasks.
We just need to put the business logic in the way the MapReduce works, and the framework will take care of the rest things. The MapReduce framework works by dividing the job into small tasks and assigns these tasks to the slaves.
The MapReduce programs are written in a particular style influenced by the functional programming constructs, specifical idioms for processing the lists of data.
In MapReduce, the inputs are in the form of a list and the output from the framework is also in the form of a list. MapReduce is the heart of Hadoop. The efficiency and powerfulness of Hadoop are due to the MapReduce framework parallel processing.
Let us now explore how Hadoop MapReduce works.
How Hadoop MapReduce Works?
The Hadoop MapReduce framework works by dividing a job into independent tasks and executing these tasks on slave machines. The MapReduce job is executed in two stages that are map phase and the reduce phase.
The input to and output from both the phases are key, value pairs. The MapReduce framework is based on the data locality principle (discussed later) which means it sends the computation to the nodes where data resides.
- Map phase − In the Map phase, the user-defined map function processes the input data. In the map function, the user puts the business logic. The output from the Map phase is the intermediate outputs and is stored on the local disk.
- Reduce phase – This phase is the combination of the shuffle phase and the reduce phase. In the Reduce phase, the output from the map stage is passed to the Reducer where they are aggregated. The output of the Reduce phase is the final output. In the Reduce phase, the user-defined reduce function processes the Mappers output and generates the final results.
During the MapReduce job, the Hadoop framework sends the Map tasks and the Reduce tasks to appropriate machines in the cluster.
The framework itself manages all the details of the data-passing such as issuing tasks, verifying the task completion, and copying data between the nodes around the cluster. The tasks take place on the nodes where data resides in order to reduce the network traffic.
MapReduce Data Flow
You all might want to know how these key value pairs are generated and how MapReduce processes the input data. This section answers all of these questions.
Let us see How data has to flow from various phases in Hadoop MapReduce to handle upcoming data in a parallel and distributed manner.
1. InputFiles
The input dataset, which is to be processed by the MapReduce program is stored in the InputFile. The InputFile is stored in the Hadoop Distributed File System.
2. InputSplit
The record in the InputFiles is split into the logical model. The split size is generally equal to the HDFS block size. Each split is processed by the individual Mapper.
3. InputFormat
InputFormat specifies the file input specification. It defines the way to the RecordReader in which the record from the InputFile is converted into the key, value pairs.
4. RecordReader
RecordReader reads the data from the InputSplit and converts records into the key, value pairs, and presents them to the Mappers.
5. Mappers
Mappers take key, value pairs as input from the RecordReader and process them by implementing user-defined map function. In each Mapper, at a time, a single split is processed.
The developer put the business logic in the map function. The output from all the mappers is the intermediate output, which is also in the form of a key, value pairs.
6. Shuffle and Sort
The intermediate output generated by Mappers is sorted before passing to the Reducer in order to reduce network congestion. The sorted intermediate outputs are then shuffled to the Reducer over the network.
7. Reducer
The Reducer process and aggregates the Mapper outputs by implementing user-defined reduce function. The Reducers output is the final output and is stored in the Hadoop Distributed File System (HDFS).
Let us now study some terminologies and advance concepts of the Hadoop MapReduce framework.
Key-Value pairs in MapReduce
The MapReduce framework works on the key, value pairs because it deals with the non-static schema. It takes data in the form of key, value pair, and generated output is also in the form of a key, value pairs.
The MapReduce key Value pair is a record entity that is received by the MapReduce job for the execution. In a key-value pair:
- Key is the line offset from the beginning of the line within the file.
- Value is the line content, excluding the line terminators.
MapReduce Partitioner
The Hadoop MapReduce Partitioner partitions the keyspace. Partitioning keyspace in MapReduce specifies that all the values of each key were grouped together, and it ensures that all the values of the single key must go to the same Reducer.
This partitioning allows even distribution of mapper’s output over Reducer by assuring that the right key goes to the right Reducer.
The default MapReducer partitioner is the Hash Partitioner, which partitions the keyspaces on the basis of the hash value.
MapReduce Combiner
The MapReduce Combiner is also known as the “Semi-Reducer.” It plays a major role in reducing network congestion. The MapReduce framework provides the functionality to define the Combiner, which combines the intermediate output from Mappers before passing them to Reducer.
The aggregation of Mapper outputs before passing to Reducer helps the framework shuffle small amounts of data, leading to low network congestion.
The main function of the Combiner is to summarize the output of the Mappers with the same key and pass it to the Reducer. The Combiner class is used between the Mapper class and the Reducer class.
Data Locality in MapReduce
Data locality refers to “Moving computation closer to the data rather than moving data to the computation.” It is much more efficient if the computation requested by the application is executed on the machine where the data requested resides.
This is very true in the case where the data size is huge. It is because it minimizes the network congestion and increases the overall throughput of the system.
The only assumption behind this is that it is better to move computation closer to the machine where data is present instead of moving data to the machine where the application is running.
Apache Hadoop works on a huge volume of data, so it is not efficient to move such huge data over the network. Hence the framework came up with the most innovative principle that is data locality, which moves computation logic to data instead of moving data to computation algorithms. This is called data locality.
Advantages of MapReduce
1. Scalability: The MapReduce framework is highly scalable. It enables organizations to run applications from large sets of machines, which can involve the use of thousands of terabytes of data.
2. Flexibility: The MapReduce framework provides flexibility to the organization to process data of any size and any format, either structured, semi-structured, or unstructured.
3. Security and Authentication: MapReduce programming model provides high security. It protects any unauthorized access to the data and enhances cluster security.
4. Cost-effective: The framework processes data across the cluster of commodity hardware, which are in-expensive machines. Thus, it is very cost-effective.
5. Fast: MapReduce processes data in parallel due to which it is very fast. It just takes minutes to process terabytes of data.
6. A simple model for programming: The MapReduce programs can be written in any language such as Java, Python, Perl, R, etc. So, anyone can easily learn and write MapReduce programs and meet their data processing needs.
Usage of MapReduce
1. Log analysis: MapReduce is used basically for analyzing log files. The framework breaks the big log files into the split and a mapper search for the different web pages that were accessed.
Every time when a web page is found in the log, then a key, value pair is passed to the reducer where the key is the webpage, and value is “1”. After emitting a key, value pair to Reducer, the Reducers aggregate the number of for certain webpages.
The final result will be the total number of hits for every webpage.
2. Full-text indexing: MapReduce is also used for performing full-text indexing. The mapper in MapReduce will map every phrase or word in one document to the document. The Reducer will write these mappings to an index.
3. Google uses MapReduce for calculating their Pagerank.
4. Reverse Web-Link Graph: MapReduce is also used in Reverse Web-Link GRaph. The Map function outputs the URL target and source, taking input from the webpage (source).
The reduce function then concatenates the list of all the source URLs which are associated with the given target URL and it returns the target and list of sources.
5. Word count in a document: MapReduce framework can be used for counting the number of times the word appears in a document.
Summary
This is all about the Hadoop MapReduce Tutorial. The framework processes huge volumes of data in parallel across the cluster of commodity hardware. It divides the job into independent tasks and executes them in parallel on different nodes in the cluster.
MapReduce overcomes the bottleneck of the traditional enterprise system. The framework works on the key, value pairs. The user defines the two functions that are map function and the reduce function.
The business logic is put into the map function. The article had explained various advanced concepts of the MapReduce framework.