What is Hadoop OutputFormat in MapReduce?
In our previous Hadoop tutorial, we have provided you a detailed description of InputFormat. Now in this blog, we are going to cover the Hadoop OutputFormat.
We will discuss What is OutputFormat in Hadoop, What is RecordWritter in MapReduce OutputFormat. We will also cover the types of OutputFormat in MapReduce.
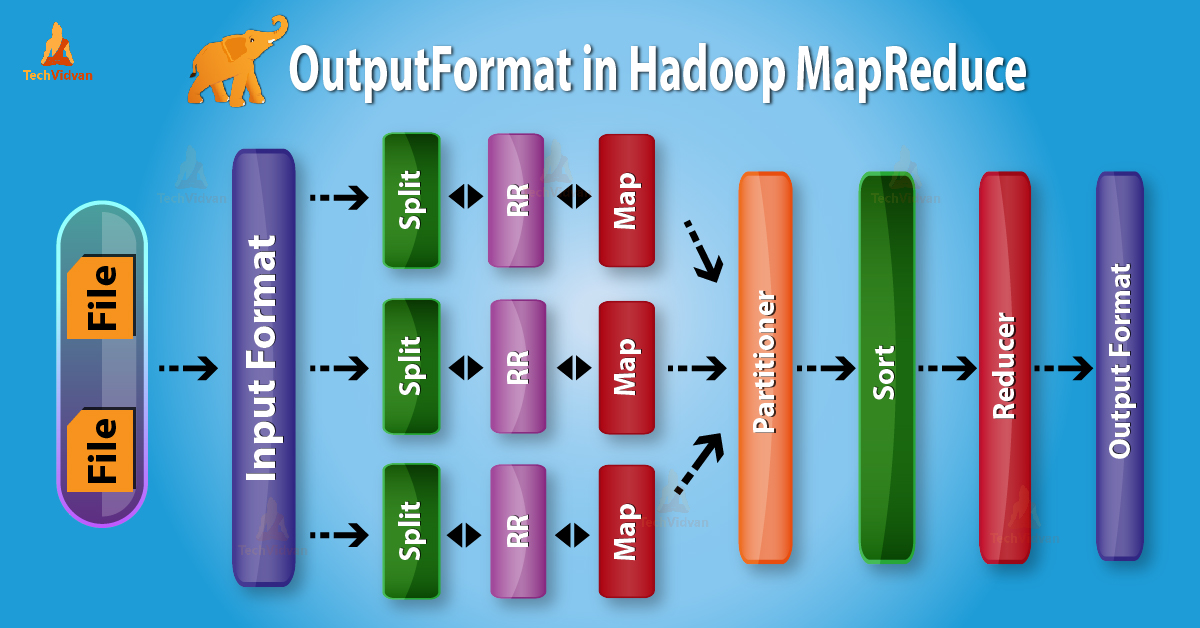
Introduction to Hadoop OutputFormat
OutputFormat check the output specification for execution of the Map-Reduce job. It describes how RecordWriter implementation is used to write output to output files.
Before we start with OutputFormat, let us first learn what is RecordWriter and what is the work of RecordWriter in MapReduce?
1. RecordWriter in Hadoop MapReduce
As we know, Reducer takes Mappers intermediate output as input. Then it runs a reducer function on them to generate output that is again zero or more key-value pairs.
So, RecordWriter in MapReduce job execution writes these output key-value pairs from the Reducer phase to output files.
2. Hadoop OutputFormat
From above it is clear that RecordWriter takes output data from Reducer. Then it writes this data to output files. OutputFormat determines the way these output key-value pairs are written in output files by RecordWriter.
The OutputFormat and InputFormat functions are similar. OutputFormat instances are used to write to files on the local disk or in HDFS. In MapReduce job execution on the basis of output specification;
- Hadoop MapReduce job checks that the output directory does not already present.
- OutputFormat in MapReduce job provides the RecordWriter implementation to be used to write the output files of the job. Then the output files are stored in a FileSystem.
The framework uses FileOutputFormat.setOutputPath() method to set the output directory.
Types of OutputFormat in MapReduce
There are various types of OutputFormat which are as follows:
1. TextOutputFormat
The default OutputFormat is TextOutputFormat. It writes (key, value) pairs on individual lines of text files. Its keys and values can be of any type. The reason behind is that TextOutputFormat turns them to string by calling toString() on them.
It separates key-value pair by a tab character. By using MapReduce.output.textoutputformat.separator property we can also change it.
KeyValueTextOutputFormat is also used for reading these output text files.
2. SequenceFileOutputFormat
This OutputFormat writes sequences files for its output. SequenceFileInputFormat is also intermediate format use between MapReduce jobs. It serializes arbitrary data types to the file.
And the corresponding SequenceFileInputFormat will deserialize the file into the same types. It presents the data to the next mapper in the same manner as it was emitted by the previous reducer. Static methods also control the compression.
3. SequenceFileAsBinaryOutputFormat
It is another variant of SequenceFileInputFormat. It also writes keys and values to sequence file in binary format.
4. MapFileOutputFormat
It is another form of FileOutputFormat. It also writes output as map files. The framework adds a key in a MapFile in order. So we need to ensure that reducer emits keys in sorted order.
5. MultipleOutputs
This format allows writing data to files whose names are derived from the output keys and values.
6. LazyOutputFormat
In MapReduce job execution, FileOutputFormat sometimes create output files, even if they are empty. LazyOutputFormat is also a wrapper OutputFormat.
7. DBOutputFormat
It is the OutputFormat for writing to relational databases and HBase. This format also sends the reduce output to a SQL table. It also accepts key-value pairs. In this, the key has a type extending DBwritable.
Conclusion
Hence, different OutputFormats are used according to the need. Hope you find this blog helpful. If you have any query about Hadoop OutputFormat, so please leave a comment in a comment box. We will be glad to solve them.