Hadoop Partitioner – Learn the Basics of MapReduce Partitioner
The main goal of this Hadoop Tutorial is to provide you a detailed description of each component that is used in Hadoop working. In this tutorial, we are going to cover the Partitioner in Hadoop.
What is Hadoop Partitioner, what is the need of Partitioner in Hadoop, What is the default Partitioner in MapReduce, How many MapReduce Partitioner are used in Hadoop?
We will answer all these questions in this MapReduce tutorial.
What is Hadoop Partitioner?
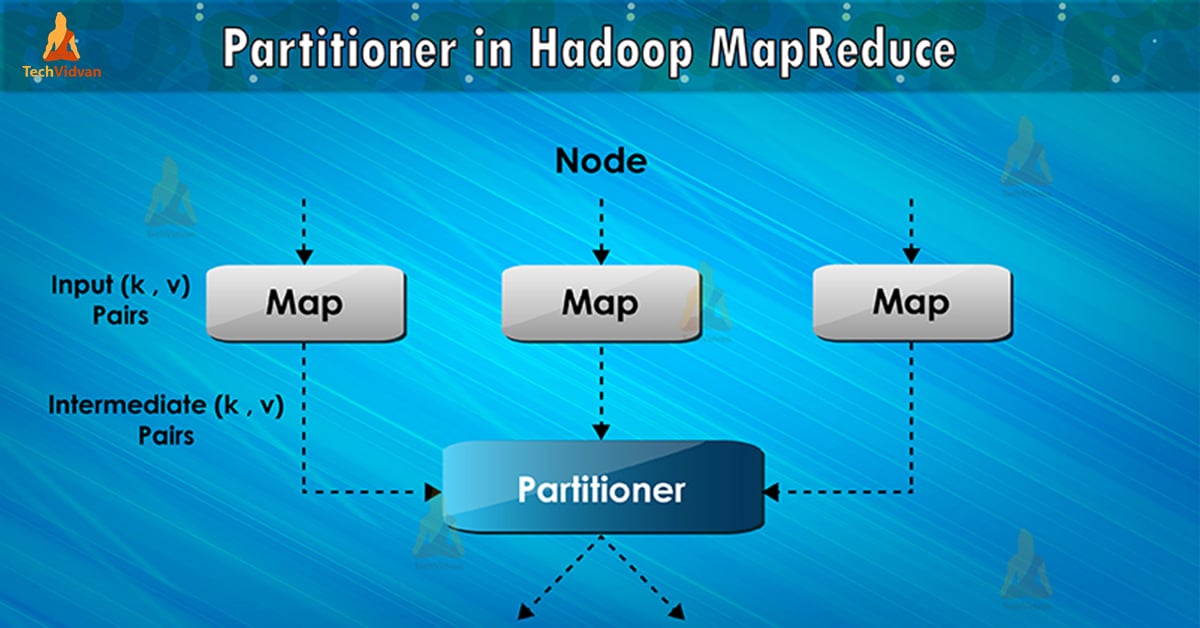
Partitioner in MapReduce job execution controls the partitioning of the keys of the intermediate map-outputs. With the help of hash function, key (or a subset of the key) derives the partition. The total number of partitions is equal to the number of reduce tasks.
On the basis of key value, framework partitions, each mapper output. Records as having the same key value go into the same partition (within each mapper). Then each partition is sent to a reducer.
Partition class decides which partition a given (key, value) pair will go. Partition phase in MapReduce data flow takes place after map phase and before reduce phase.
Need of MapReduce Partitioner in Hadoop
In MapReduce job execution, it takes an input data set and produces the list of key value pair. These key-value pair is the result of map phase. In which input data are split and each task processes the split and each map, output the list of key value pairs.
Then, framework sends the map output to reduce task. Reduce processes the user-defined reduce function on map outputs. Before reduce phase, partitioning of the map output take place on the basis of the key.
Hadoop Partitioning specifies that all the values for each key are grouped together. It also makes sure that all the values of a single key go to the same reducer. This allows even distribution of the map output over the reducer.
Partitioner in a MapReduce job redirects the mapper output to the reducer by determining which reducer handles the particular key.
Hadoop Default Partitioner
Hash Partitioner is the default Partitioner. It computes a hash value for the key. It also assigns the partition based on this result.
How many Partitioner in Hadoop?
The total number of Partitioner depends on the number of reducers. Hadoop Partitioner divides the data according to the number of reducers. It is set by JobConf.setNumReduceTasks() method.
Thus the single reducer processes the data from single partitioner. The important thing to notice is that the framework creates partitioner only when there are many reducers.
Poor Partitioning in Hadoop MapReduce
If in data input in MapReduce job one key appears more than any other key. In such case, to send data to the partition we use two mechanisms which are as follows:
- The key appearing more number of times will be sent to one partition.
- All the other key will be sent to partitions on the basis of their hashCode().
If hashCode() method does not distribute other key data over the partition range. Then data will not be sent to the reducers.
Poor partitioning of data means that some reducers will have more data input as compared to other. They will have more work to do than other reducers. Thus the entire job has to wait for one reducer to finish its extra-large share of the load.
How to overcome poor partitioning in MapReduce?
To overcome poor partitioner in Hadoop MapReduce, we can create Custom partitioner. This allows sharing workload across different reducers.
Conclusion
In conclusion, Partitioner allows uniform distribution of the map output over the reducer. In MapReducer Partitioner, partitioning of map output take place on the basis of the key and value.
Hence, we have covered the complete overview of Partitioner in this blog. Hope you liked it. If any doubt comes into your mind about Hadoop Partitioner, so don’t forget to share with us.