What is InputSplit in Hadoop MapReduce?
In our previous Hadoop tutorial, we have studied Hadoop Partitioner in detail. Now we are going to discuss InputSplit in Hadoop MapReduce.
Here, we will cover what is Hadoop InputSplit, the need of InputSplit in MapReduce. We will also discuss how these InputSplits are created in Hadoop MapReduce in great detail.
Introduction to InputSplit in Hadoop
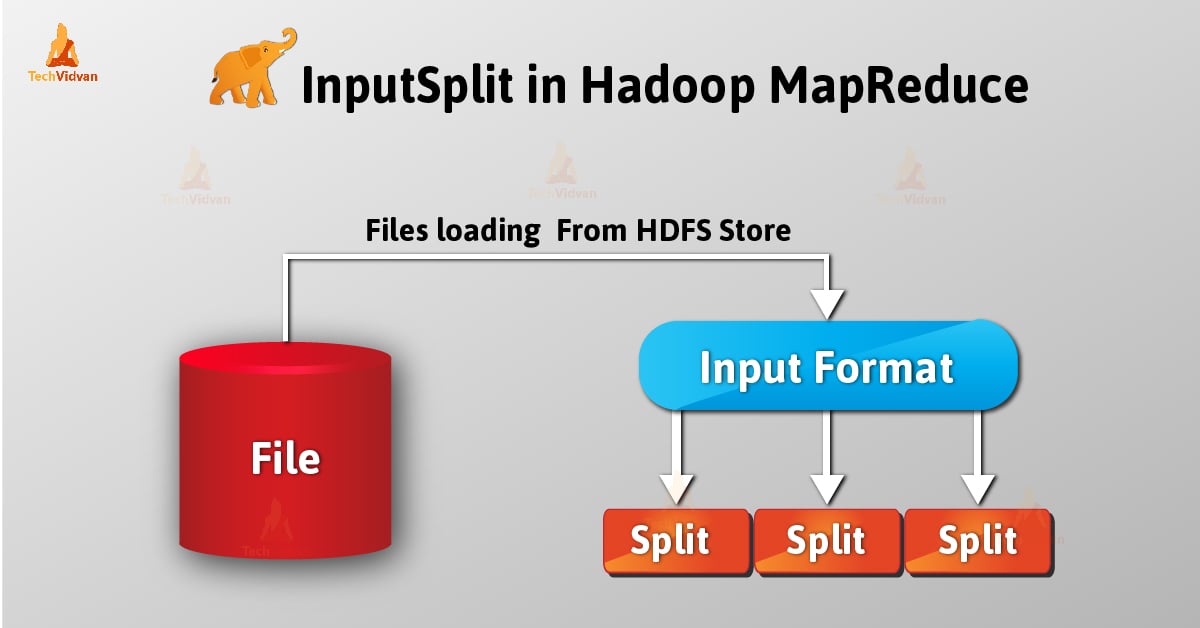
InputSplit is the logical representation of data in Hadoop MapReduce. It represents the data which individual mapper processes. Thus the number of map tasks is equal to the number of InputSplits. Framework divides split into records, which mapper processes.
MapReduce InputSplit length has measured in bytes. Every InputSplit has storage locations (hostname strings). The MapReduce system places map tasks as close to the split’s data as possible by using storage locations.
Framework processes Map tasks in the order of the size of the splits so that the largest one gets processed first (greedy approximation algorithm). This minimizes the job run time.
The main thing to focus is that Inputsplit does not contain the input data; it is just a reference to the data.
How InputSplits are created in Hadoop MapReduce?
As a user, we don’t deal with InputSplit in Hadoop directly, as InputFormat (as InputFormat is responsible for creating the Inputsplit and dividing into the records) creates it. FileInputFormat breaks a file into 128MB chunks.
Also, by setting mapred.min.split.size parameter in mapred-site.xml user can change the value as per requirement. Also by this we can override the parameter in the Job object used to submit a particular MapReduce job.
By writing a custom InputFormat we can also control how the file is broken into splits.
InputSplit is user defined. The user can also control split size based on the size of data in MapReduce program. Hence, In a MapReduce job execution number of map tasks is equal to the number of InputSplits.
By calling ‘getSplit()’, the client calculate the splits for the job. Then it sent to the application master, which uses their storage locations to schedule map tasks that will process them on the cluster.
After that map task passes the split to the createRecordReader() method. From that it obtains RecordReader for the split. Then RecordReader generate record (key-value pair), which it passes to the map function.
Conclusion
In conclusion we can say that, InputSplit represents the data which individual mapper processes. For each split one map task is created. Hence, InputFormat creates the InputSplit.
If you have any query about InputSplit in MapReduce, so, please leave a comment in a section given below.