What is Map Only job in Hadoop?
In our previous Hadoop blogs we have studied each component of the Hadoop MapReduce process in detail. In this we are going to discuss the very interesting topic i.e. Map Only job in Hadoop.
Firstly, we will take a brief introduction of the Map and Reduce phase in Hadoop Mapreduce, then after we will discuss what is Map only job in Hadoop MapReduce.
At last we will also discuss the advantages and disadvantages of Hadoop Map Only job in this tutorial.
What is Hadoop Map Only Job?
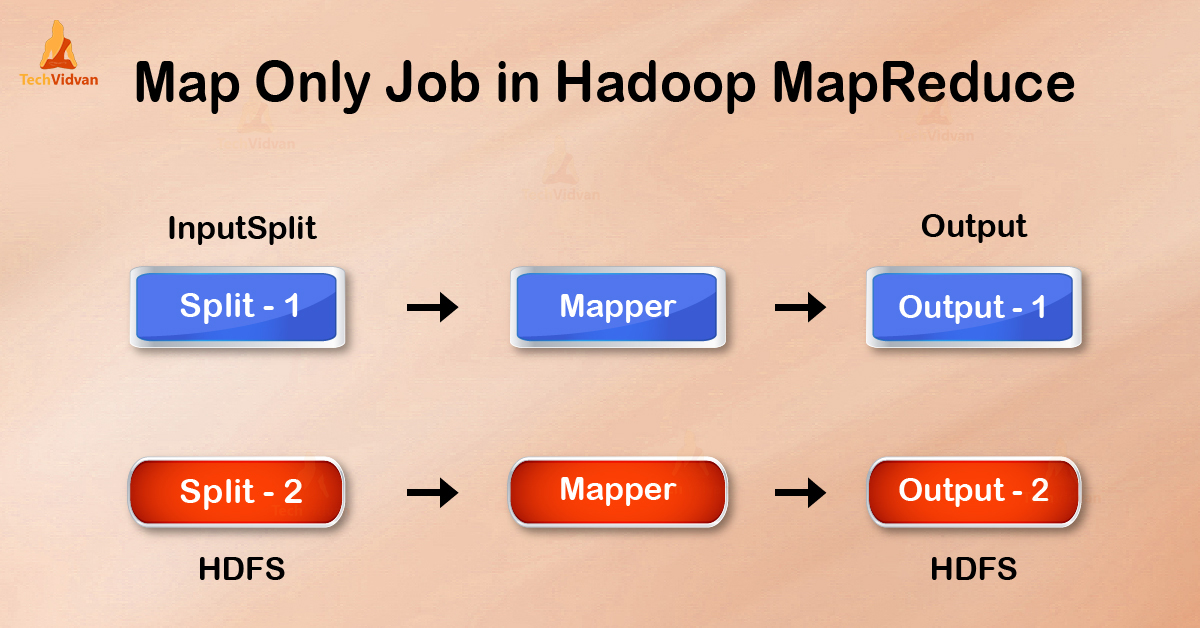
Map-Only job in the Hadoop is the process in which mapper does all tasks. No task is done by the reducer. Mapper’s output is the final output.
MapReduce is the data processing layer of Hadoop. It processes large structured and unstructured data stored in HDFS. MapReduce also processes a huge amount of data in parallel.
It does this by dividing the job (submitted job) into a set of independent tasks (sub-job). In Hadoop, MapReduce works by breaking the processing into phases: Map and Reduce.
- Map: It is the first phase of processing, where we specify all the complex logic code. It takes a set of data and converts into another set of data. It breaks each individual element into tuples (key-value pairs).
- Reduce: It is the second phase of processing. Here we specify light-weight processing like aggregation/summation. It takes the output from the map as input. Then it combines those tuples based on the key.
From this word-count example, we can say that there are two sets of parallel process, map and reduce. In map process, the first input is split to distribute the work among all the map nodes as shown above.
Then framework identifies each word and map to the number 1. Thus, it creates pairs called tuples (key-value) pairs.
In the first mapper node, it passes three words lion, tiger, and the river. Thus, it produces 3 key-value pairs as the output of the node. Three different keys and value set to 1 and the same process repeat for all nodes.
Then it passes these tuples to the reducer nodes. Partitioner carries out shuffling so that all tuples with the same key goes to the same node.
In reduce process what basically happens is an aggregation of values or rather an operation on values that share the same key.
Now, let us consider a scenario where we just need to perform the operation. We don’t need aggregation, in such case, we will prefer ‘Map-Only job’.
In Map-Only job, the map does all tasks with its InputSplit. Reducer does no job. Mappers output is the final output.
How to avoid Reduce Phase in MapReduce?
By setting job.setNumreduceTasks(0) in the configuration in a driver we can avoid reduce phase. This will make a number of reducer as 0. Thus the only mapper will be doing the complete task.
Advantages of Map only job in Hadoop
In MapReduce job execution in between map and reduces phases there is key, sort and shuffle phase. Shuffling –Sorting are responsible for sorting the keys in ascending order. Then grouping values based on the same keys. This phase is very expensive.
If reduce phase is not required, we should avoid it. As avoiding reduce phase would eliminate sorting and shuffle phase as well. Therefore, this will also save network congestion.
The reason is that in shuffling, an output of the mapper travels to reduce. And when the data size is huge, large data needs to travel to the reducer.
The output of the mapper is written to local disk before sending to reduce. But in map only job, this output is directly written to HDFS. This further saves time as well reduces cost.
Conclusion
Hence, we have seen that Map-only job reduces the network congestion by avoiding shuffle, sort and reduce phase. Map alone take care of overall processing and produce the output. BY using job.setNumreduceTasks(0) this is achieved.
I hope you have understood the Hadoop map only job and its significant because we have covered everything about Map Only job in Hadoop. But if you have any query so you can share with us in the comment section.