Hadoop MapReduce Job Execution flow Chart
In this Hadoop blog, we are going to provide you an end to end MapReduce job execution flow. Here we will describe each component which is the part of MapReduce working in detail.
This blog will help you to answer how Hadoop MapReduce work, how data flows in MapReduce, how Mapreduce job is executed in Hadoop?
What is MapReduce?
Hadoop MapReduce is the data processing layer. It processes the huge amount of structured and unstructured data stored in HDFS. MapReduce processes data in parallel by dividing the job into the set of independent tasks. So, parallel processing improves speed and reliability.
Hadoop MapReduce data processing takes place in 2 phases- Map and Reduce phase.
- Map phase- It is the first phase of data processing. In this phase, we specify all the complex logic/business rules/costly code.
- Reduce phase- It is the second phase of processing. In this phase, we specify light-weight processing like aggregation/summation.
Steps of MapReduce Job Execution flow
MapReduce processess the data in various phases with the help of different components. Let’s discuss the steps of job execution in Hadoop.
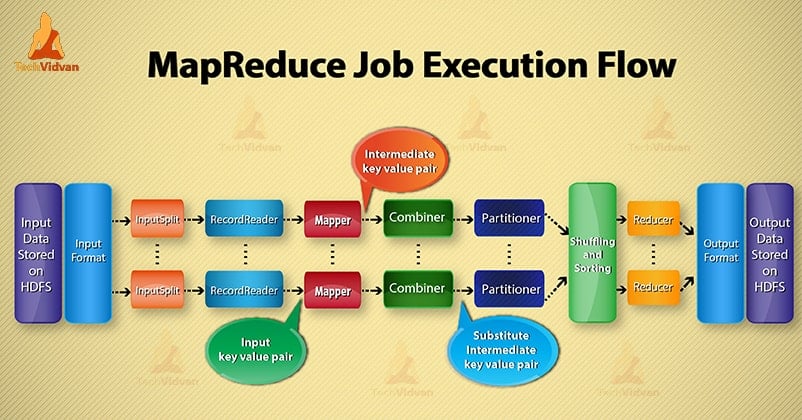
1. Input Files
In input files data for MapReduce job is stored. In HDFS, input files reside. Input files format is arbitrary. Line-based log files and binary format can also be used.
2. InputFormat
After that InputFormat defines how to split and read these input files. It selects the files or other objects for input. InputFormat creates InputSplit.
3. InputSplits
It represents the data which will be processed by an individual Mapper. For each split, one map task is created. Thus the number of map tasks is equal to the number of InputSplits. Framework divide split into records, which mapper process.
4. RecordReader
It communicates with the inputSplit. And then converts the data into key-value pairs suitable for reading by the Mapper. RecordReader by default uses TextInputFormat to convert data into a key-value pair.
It communicates to the InputSplit until the completion of file reading. It assigns byte offset to each line present in the file. Then, these key-value pairs are further sent to the mapper for further processing.
5. Mapper
It processes input record produced by the RecordReader and generates intermediate key-value pairs. The intermediate output is completely different from the input pair. The output of the mapper is the full collection of key-value pairs.
Hadoop framework doesn’t store the output of mapper on HDFS. It doesn’t store, as data is temporary and writing on HDFS will create unnecessary multiple copies. Then Mapper passes the output to the combiner for further processing.
4. Combiner
Combiner is Mini-reducer which performs local aggregation on the mapper’s output. It minimizes the data transfer between mapper and reducer. So, when the combiner functionality completes, framework passes the output to the partitioner for further processing.
5. Partitioner
Partitioner comes into the existence if we are working with more than one reducer. It takes the output of the combiner and performs partitioning.
Partitioning of output takes place on the basis of the key in MapReduce. By hash function, key (or a subset of the key) derives the partition.
On the basis of key value in MapReduce, partitioning of each combiner output takes place. And then the record having the same key value goes into the same partition. After that, each partition is sent to a reducer.
Partitioning in MapReduce execution allows even distribution of the map output over the reducer.
6. Shuffling and Sorting
After partitioning, the output is shuffled to the reduce node. The shuffling is the physical movement of the data which is done over the network. As all the mappers finish and shuffle the output on the reducer nodes.
Then framework merges this intermediate output and sort. This is then provided as input to reduce phase.
7. Reducer
Reducer then takes set of intermediate key-value pairs produced by the mappers as the input. After that runs a reducer function on each of them to generate the output.
The output of the reducer is the final output. Then framework stores the output on HDFS.
8. RecordWriter
It writes these output key-value pair from the Reducer phase to the output files.
9. OutputFormat
OutputFormat defines the way how RecordReader writes these output key-value pairs in output files. So, its instances provided by the Hadoop write files in HDFS. Thus OutputFormat instances write the final output of reducer on HDFS.
Conclusion
We have learned step by step MapReduce job execution flow. I hope this blog helps you a lot to understand the MapReduce working.
If still, you have any query related to MapReduce job execution flow, so you can share with us in the comment section given below. We will try our best to solve them.