Speculative Execution in Hadoop MapReduce
In this MapReduce Speculative Execution article, you will explore Hadoop speculative execution in detail. You will learn what is speculative execution, what is its need, how we can enable and disable it.
The article also explains whether it is beneficial or not and how it works.
What is Speculative Execution in Hadoop?
The MapReduce model in the Hadoop framework breaks the jobs into independent tasks and runs these tasks in parallel in order to reduce the overall job execution time.
This makes the job execution time-sensitive for the slow-running tasks because only a single slow task can make the entire job execution time longer than expected. When any job consists of thousands or hundreds of tasks then the possibility of the few straggling tasks is very real.
The tasks can be slow because of various reasons, such as software misconfiguration or hardware degradation. But the cause that makes the job run slow is hard to detect because the tasks still complete successfully, though it takes a longer time than expected.
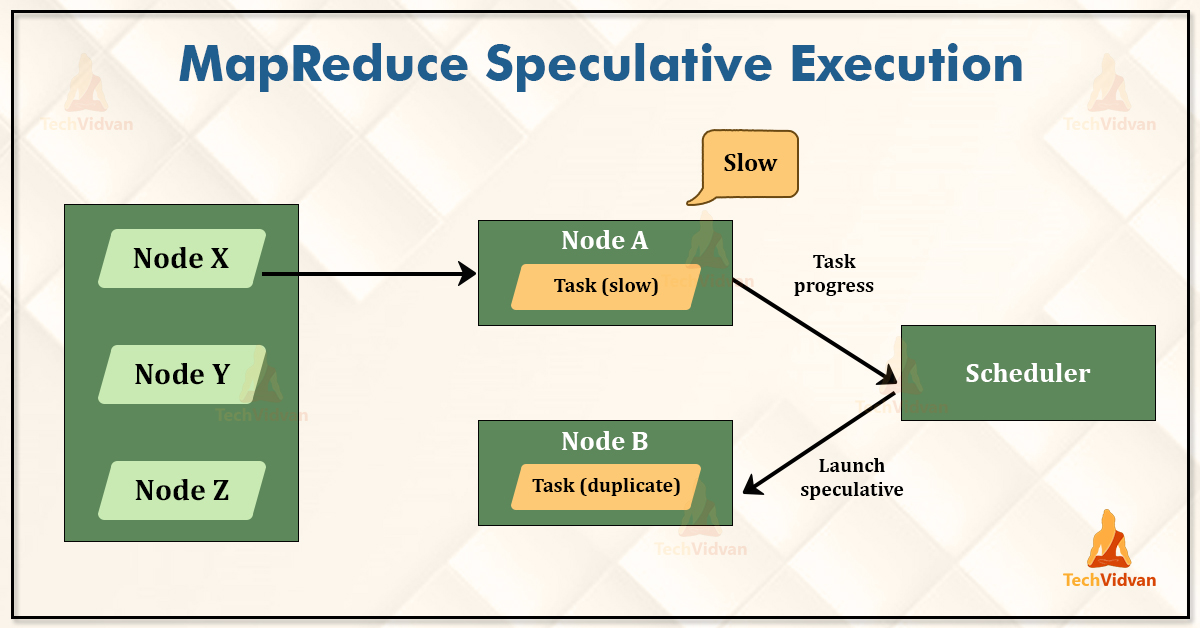
The Hadoop framework does not try to diagnose or fix the slow-running tasks. The framework tries to detect the task which is running slower than the expected speed and launches another task, which is an equivalent task as a backup.
The backup task is known as the speculative task, and this process is known as speculative execution in Hadoop.
What is the need for speculative execution in Hadoop?
In the Hadoop framework, the input file is partitioned into multiple blocks, and those blocks were stored on the different nodes in the Hadoop cluster.
When the MapReduce job is submitted by the client then it calculates the number of the InputSplits and runs as many mappers as the number of InputSplit. These mappers (map tasks) run in parallel on the DataNodes, where the split data resides.
Now, What if the few DataNodes in the Hadoop cluster are not executing the tasks as fast as the other DataNodes either because of hardware failure or network problems.
So the map tasks running on those DataNodes will be slower as compared to the map tasks which are running on the other DataNodes. The Reducer can start its execution only when the intermediate outputs of all the mappers are available.
Thus the fewer slow running map tasks will delay the execution of the Reducer.
If the Reducer is running on the slower node, then that will also delay the overall job final output.
So in order to guard against such slow-running tasks, the Hadoop framework starts the same task on the other node. This optimization by the Hadoop framework is called the speculative execution of the task.
How Speculative Execution works in Hadoop?
The speculative execution does not launch the two duplicate tasks of every independent task of a job at about the same time so they can race each other. If the framework does so, then it would lead to the waste of the cluster resources.
Instead of it, the scheduler tracks the progress of all the tasks of the same type (such as map and reduce) in a job, and launches only the speculative duplicates for small proportions that were running slower than the average.
When the task gets successfully completed, then any duplicate tasks that are running were killed since they were no longer required.
So, in case if the original task completes before the speculative task, then the speculative task is killed. If the speculative task finishes before the original task, then the original is killed.
Note that the speculative execution is an optimization. It is not a feature to make the MapReduce jobs run more reliably.
How to configure speculative execution in Hadoop?
By default, the Speculative execution is enabled for the Map task as well as for the reduce tasks. Its properties are set in the mapred-site.xml configuration file.
- mapreduce.map.speculative : If this property is set to true, then the speculative execution of the map task is enabled. By default, it is true.
- mapreduce.reduce.speculative: If this property is set to true, then the speculative execution of the reduce task is enabled. By default, it is true.
Why would you ever want to turn speculative execution off?
The main goal of the speculative execution is to reduce job execution time. But this will come at the cost of the Hadoop cluster efficiency.
On a busy Hadoop cluster, this may reduce the overall throughput because the redundant tasks are being executed in order to reduce the execution time for the single job.
Because of this reason, some cluster administrators turn off the speculative execution on the Hadoop cluster and have users explicitly turn it on for the individual jobs.
We can turn it off for the reduce tasks because any duplicate reduce tasks require to fetch the same mapper outputs as the original task, which will significantly increase the network traffic on the cluster.
Is Speculative Execution Beneficial?
Speculative execution in Hadoop is beneficial in some cases because in the Hadoop cluster having hundreds or thousands of nodes, the problems like network congestion or hardware failure are common.
So running parallel or duplicate tasks will be better. But in case, if the two duplicate tasks of every independent task of a job is launched at about the same time, then it will be a wastage of cluster resources.
Summary
I hope after reading this article, you clearly understood what speculative execution in Hadoop is and why it is needed. You have also seen how we can disable it for map tasks and reduce tasks individually.