Apache Pig Tutorial for Beginners
Pig is one of the components of the Hadoop ecosystem. If you are eager to learn Apache Pig, then this tutorial is the best guide. This Pig tutorial will cover each and everything related to Apache Pig.
The article first explains why Apache Pig came into the picture for analyzing big data in the era of MapReduce. Later on, you will explore Pig features and a lot more concepts related to Pig.
Why was Apache Pig developed?
Previously, for analyzing data in Apache Hadoop, we had to write MapReduce jobs in Java, which is not an easy task. To perform a simple task, we have to write 200 lines of codes. It is very complex.
In such a scenario, Apache Pig comes out as a boon for the programmers who are not good with programming languages like Java or Python. Also, even if someone has good hands on Java, then also they feel a headache while writing MapReduce jobs.
At an approx 10 lines of Apache Pig code is equal to the 200 lines of MapReduce code. So in order to provide flexibility to the programmers and reduce the burden of writing long MapReduce code, Apache Pig was developed. For the programmers, Apache Pig is a savior because:
- It uses a language called ‘Pig Latin’ which is a high-level data flow language. Without writing the complex Java implementations in MapReduce, the programmers can easily achieve the same implementations by using Pig Latin.
- Pig uses a multi-query approach, that means by using a single Pig Latin query, we can perform multiple MapReduce tasks. This reduces the length of the code by 20 times. Thus, it helps in quick development by reducing the development time by almost 16 times.
- Apache Pig supports many built-in operators that provide support for data operations like ordering, joins, filters, sorting, etc.
- In addition, Apache Pig also provides nested data types like bags, tuples, and maps that are missing from the MapReduce.
What is Apache Pig?
Apache Pig is a platform used for analyzing massive data sets representing them as data flows. Pig is basically an abstraction over MapReduce.
Its purpose is to reduce the complexities of writing a complex MapReduce program. With Apache Pig, we can perform all types of data manipulation operations in Apache Hadoop.
For writing the data analysis programs, Apache Pig provides a high-level language known as Pig Latin. This language supports several operators which programmers can use for developing their own functions for performing several tasks like reading, writing, and processing data.
For analyzing data using Pig, we have to write the scripts by using Pig Latin language. Internally all these scripts are converted into the Map and Reduce tasks.
Pig has a component called Pig Engine, which accepts Pig Latin scripts as input and converts them into MapReduce jobs.
History of Apache Pig
- 2006: In 2006, Pig was developed as a research project at Yahoo, especially for creating and executing MapReduce jobs on every dataset.
- 2007: In 2007, Pig was open-sourced via Apache incubator.
- 2008: In 2008, the first release of Apache Pig came out.
- 2010: In 2010, Apache Pig became the Apache top-level project.
Where to use Apache Pig?
Pig is basically useful for analyzing data involving ad-hoc processing. We can use it in situations where:
- There is a need to process large data sets such as streaming online data, Web logs, etc.
- We require Data processing for the search platforms, that is, when we need to process different types of data, like Yahoo, which uses Apache Pig for 40% of their jobs, including search engine and news feeds.
- We are in need to process the time-sensitive data loads. In this situation, the data needs to be extracted and analyzed quickly.
Features of Apache Pig
1. Apache Pig allows programmers to write complex data transformations without worrying about Java.
2. Pig has two main components, that are, Pig Latin language and Pig Run-time Environment. In the Pig Run-time environment, Pig Latin programs are executed.
3. Pig provides a simple data flow language called Pig Latin for Big Data Analytics. Pig Latin provides the same functionalities as SQL like filter, join, limit, etc.
4. Developers who are familiar with the scripting languages and SQL, leverages Pig Latin. This provides developers with ease of programming with Pig.
5. Pig Latin provides support for various built-in operators such as filter, join, sort, etc. for reading, writing, and processing huge amounts of data sets. Thus, Apache Pig has a rich set of operators.
6. For analyzing data using Pig, we have to write the scripts by using the Pig Latin language. Internally all these scripts are converted into the Map and Reduce tasks. Before the development of Apache Pig, writing MapReduce tasks was the only way of processing data in HDFS.
7. Apache Pig allows developers to write the User Defined Function in any language if the programmer wishes to write the custom functions which are unavailable. This UDF is then embedded in the Pig script. This gives extensibility to Apache Pig.
8. We can use Apache Pig for processing any kind of data, that is, structured/semi-structured/unstructured data coming from several sources.
9. At an approx 10 lines of Apache Pig code is equal to the 200 lines of MapReduce code.
10. Apache Pig can handle inconsistent schema.
11. Apache Pig can extract the data, perform operations on them, and dump back the data in the required format in the HDFS. That means we can use it for ETL (Extract Transform Load) operations.
12. Pig automatically optimizes a task before task execution. Thus provide automatic optimization.
Architecture of Apache Pig
We need Pig Latin language for writing a Pig script and a runtime environment for executing them. The below image depicts the Apache Pig architecture.
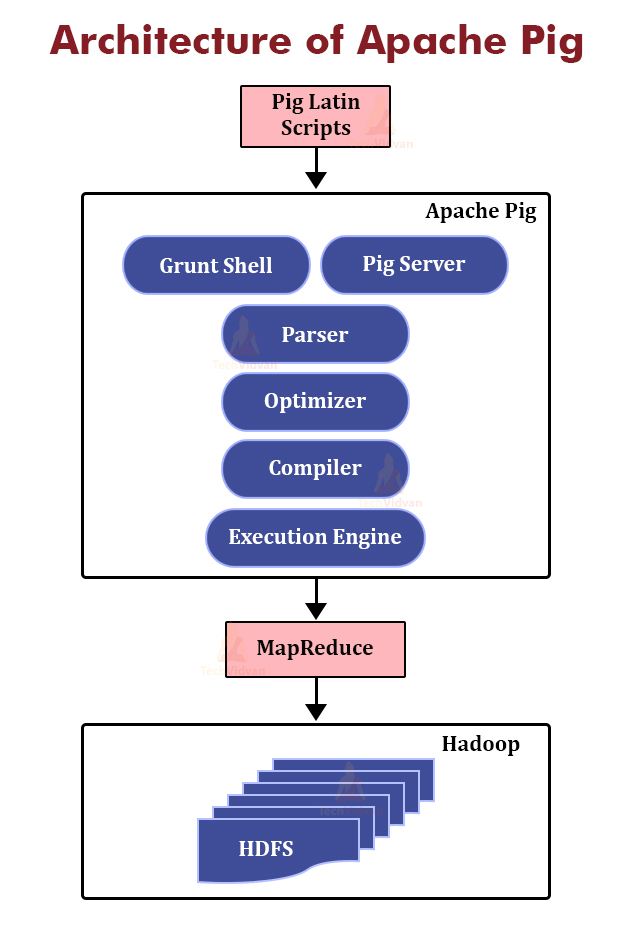
1. Pig Latin Scripts
Initially, we submit the Pig scripts written in Pig Latin to the Apache Pig execution environment.
There are three ways of executing the Pig script:
- Grunt Shell: It is the Apache Pig’s interactive shell for executing all the Pig Scripts.
- Pig Server: We can write all the Pig commands in the script file and then execute the Pig script file. Pig Server executes this script file.
- Embedded Script: We can create UDF by using languages like Java, Ruby, Python, etc. if some functions are unavailable. This UDF is embedded in the Pig Latin Script file, and then the script file is executed.
2. Parser
After passing through the Grunt or the Pig Server, the Pig Scripts are passed to the Parser. The Parser performs type checking, and it checks the syntax of the Pig script.
The parser output is a DAG (directed acyclic graph). DAG represents Pig Latin statements and logical operators. The nodes represent the logical operators, and the edges represent the data flows.
3. Optimizer
Then the output of the parser, that is, DAG is submitted to the optimizer. The Optimizer does the optimization activities such as split, transform, merge, reorder operators etc. Optimizer is responsible for providing the automatic optimization feature to Pig.
4. Compiler
After optimization, the compiler compiles the optimized code into the series of MapReduce jobs. Compiler in Pig is responsible for converting the Pig jobs automatically into the MapReduce jobs.
5. Execution engine
The MapReduce jobs from the compiler are then passed to the execution engine. Here, the MapReduce jobs are executed and produce the required result. The result is displayed on the screen by using the “DUMP” statement and is stored in the HDFS by using the “STORE” statement.
Let us now explore the Pig Data model.
Pig Latin Data Model
The data model of Pig Latin allows Apache Pig to handle all types of data. The Pig Latin can handle atomic data types such as int, float, double, long, etc. as well as complex data types such as bag, tuple, and map.
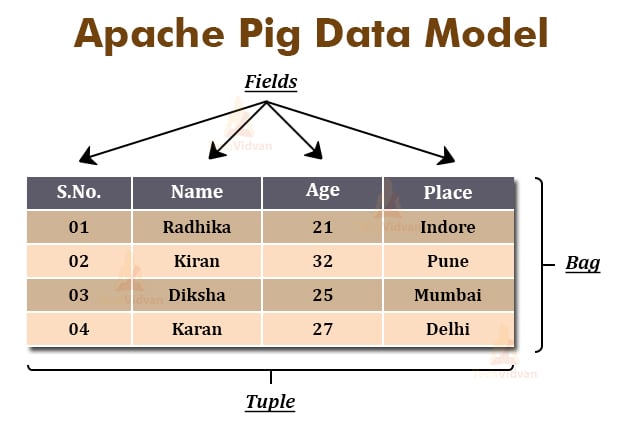
Atom
Atomic, also known as scalar data types, are the basic data types in Pig Latin, which are used in all the types like string, float, int, double, long, char[], byte[]. The atomic data types are also known as primitive data types. Each cell value in a field (column) is an atomic data type.
For Example − ‘Joe’, 1, etc.
Tuple
The Tuple is an ordered set of fields that may contain different data types for different fields. It is similar to the records stored in a row in the RDBMS. The tuple is represented by the ‘()’ symbol. We can access fields in each tuple by using the indexes of the fields.
For Example: (1, Linkin Park, 7, California), and we can access ‘Linkin Park’ by $1.
Bag
A bag in Pig Latin is an unordered set of tuples. In simpler words, it is a collection of tuples (non-unique). Each tuple in a bag can have any number of fields. A bag is represented by the symbol ‘{}’.
Bag is similar to the table in RDBMS. But unlike the table in RDBMS, in Bag it is not necessary that every tuple must contain the same number of fields or all the fields must be in the same position or have the same type.
For Example − {(Linkin Park, 7, California), (Metallica, 8), (Mega Death, Los Angeles)}
Map
A map in Pig Latin is a set of key-value pairs. The key must be unique and needs to be of type chararray. The value in the map can be of any type. The Map is represented by the symbol ‘[]’
For Example −[band#Linkin Park, members#7 ], [band#Metallica, members#8 ]
Difference between Apache Pig and MapReduce
| Apache Pig | MapReduce |
| It is a data flow language. | It is a data processing framework. |
| Pig is a high-level language. | MapReduce is low-level and rigid. |
| In Apache Pig, we can easily perform a Join operation. | Performing join operations between datasets in MapReduce is quite difficult. |
| Any novice programmer who is having a basic knowledge of SQL can easily work with Apache Pig. | For working with MapReduce, one has to be familiar with Java. |
| Apache Pig uses the multi-query approach. Thus the length of the code is reduced to a great extent. | MapReduce requires almost 20 times more number of lines as compared to Pig code to perform the same task. |
| In Apache Pig, there is no need for compilation. Every Pig operator on execution is converted internally into the MapReduce job. | MapReduce jobs go through a long compilation process. |
Difference between Apache Pig and SQL
| Pig | SQL |
| Pig Latin is the procedural language. | SQL is the declarative language. |
| Schema is optional in Apache Pig. In Pig, we can store data without designing any schema. | In SQL, schema is mandatory. |
| Nested relational data model. | The data model in SQL is flat relational. |
| Pig provides limited opportunity for Query optimization. | SQL provides more opportunities for query optimization. |
Difference between Apache Pig and Hive
| Apache Pig | Hive |
| Created at Yahoo. It uses a language called Pig Latin. | Created by Facebook. It uses a language called HiveQL. |
| It is a data flow language. | HiveQL is a query processing language. |
| Pig Latin is a procedural language. | HiveQL is a declarative language. |
| Apache Pig can handle structured/unstructured/semi-structured data. | Hive is mostly for structured data. |
Applications of Apache Pig
We can use Apache Pig for −
- Performing tasks involving the ad-hoc processing and quick prototyping.
- Processing large data sources such as web logs.
- Performing data processing for the search platforms.
- Processing time-sensitive data loads.
Summary
I hope after reading this article you clearly understood Apache Pig. The article had explained what Apache Pig is, where we can use Apache Pig. We can use Apache Pig for analyzing large data sets with the Pig scripts written using Pig Latin.
The Pig architecture consists of Compiler, Parser, Optimizer, and Execution engine. The article had also explained the Pig Latin Data Model. If you are having any issue regarding this topic, then do share it in the comment box.