Apache Zookeeper Tutorial for Beginners
If you are eager to learn about Apache Zookeeper without referring to any book, then it is the right article for you. In this ZooKeeper tutorial article, you will explore what Apache ZooKeeper is and why we use Apache Zookeeper. The article will explain every concept related to Apache Zookeeper.
Let’s start our new journey towards ZooKeeper. This tutorial article will give you the reason for why you should learn ZooKeeper and also enlist the companies using ZooKeeper.
Introduction to Apache Zookeeper
Apache ZooKeeper is basically a distributed coordination service for managing a large set of hosts. Coordinating and managing the service in the distributed environment is really a very complicated process.
Apache ZooKeeper, with its simple architecture and API, solves this issue. ZooKeeper allows the developer to focus on the core application logic without being worried about the distributed nature of the application.
Originally, Yahoo built the ZooKeeper framework in order to access their applications in an easy and robust manner. Later on, Apache ZooKeeper became the standard for the organized service used by Apache Hadoop, HBase, and various other distributed frameworks.
For example, HBase uses Apache ZooKeeper for tracking the status of the distributed data.
In simple words, Zookeeper is one of the top-notch cluster coordination services that use the most robust synchronization techniques for keeping the nodes perfectly connected in the cluster.
Apache Zookeeper, with its simple architecture and API, solves the management of the distributed environment.
Distributed Application
A distributed application is the application that can run on the multiple systems in a network simultaneously by coordinating among themselves in order to complete the specific task in an efficient manner.
The distributed application can complete the complex and the time-consuming tasks in minutes as compared to the non-distributed application that will take hours to complete the task.
The distributed application uses the computing capabilities of all the machines involved. We can further reduce the time to complete the task by configuring the distributed application to run on more nodes in the cluster.
A distributed application consists of two parts, that is, Server and Client application. The server applications are actually distributed and they have a common interface so that the clients can connect to any server in a cluster and get the same result.
The client applications were the tools for interacting with the distributed application.
Benefits of Distributed Applications
The distributed applications offer various benefits such as:
1. Reliability − If the single node or the few systems fails, then it doesn’t make the whole system fail.
2. Scalability − We can easily increase the performance when needed by adding more machines with the minor changes in the application configuration without any downtime.
3. Transparency − It hides the complexity of the entire system and depicts itself as a single entity or application.
Challenges of Distributed Applications
1. Partial failure
It is one of the major challenges in distributed applications.
For example, Suppose that there are two nodes, that is, Node 1 and Node 2, in the distributed system. Node 1 sends a message to Node 2 over the network. However, if the network fails before Node 1 receives an acknowledgment from the Node 2, then Node 1 doesn’t know whether the Node 2 has got the message or not.
Node 1 will know the actual status only when the network gets connected again. This situation is known as a partial failure in distributed applications.
Apache Zookeeper provides a mechanism to handle partial failure efficiently.
2. Race Conditions
A race condition will take place in the distributed applications when the multiple machines are waiting for the same resource to get free.
For example, suppose that there are four different nodes in the distributed system and only Node1 is using the resource.
So, in such a case, Node 1 has an exclusive lock on the resource. Also, let assume that at the same time, all the other three nodes are waiting for the resource to become free.
So, when Node 1 releases the resource, then the remaining nodes will race to acquire the resource. Out of these 3 only one of them will succeed while the others will go back to the waiting state.
The above process will continue until all the nodes in the system get the resource. This condition is called a race condition.
3. Deadlocks in Apache Zookeeper
Deadlocks occur in the situation when there is a cyclic dependency on the resources.
For example, there are two machines, named Machine 1 and Machine 2, and two resources, named resource A and resource B. If the machine 1 has locked resource A and is eagerly waiting to lock the resource B.
And at the same time, the machine 2 has locked the resource B and is waiting to lock the resource A. In this situation, none of the locks can be acquired or released. This leads to the deadlock condition.
In order to resolve this deadlock, either of the processes has to be killed and we have to redo the processing.
Deadlock detection is CPU-intensive and is an expensive operation.
4. Inconsistencies
Inconsistencies will take place in the situation when the changes are not propagated to all the nodes/machines in the distributed system.
Why we use Zookeeper?
ZooKeeper framework provides the complete mechanism for overcoming all the challenges faced by the distributed applications. Apache Zookeeper handles the race condition and the deadlock by using the fail-safe synchronization approach. It also handles the inconsistency of data by atomicity.
Apache ZooKeeper is basically a service that is used by the cluster to coordinate between themselves and maintain the shared data with the robust synchronization techniques.
Apache ZooKeeper is itself a distributed application providing services for writing the distributed application.
The various services provided by Apache ZooKeeper are as follows −
- Naming service − This service is for identifying the nodes in the cluster by the name. This service is similar to DNS, but for nodes.
- Configuration management − This service provides the latest and up-to-date configuration information of a system for the joining node.
- Cluster management − This service keeps the status of the Joining or leaving of a node in the cluster and the node status in real-time.
- Leader election − This service elects a node as a leader for the coordination purpose.
- Locking and synchronization service − This service locks the data while modifying it. It helps in automatic fail recovery while connecting the other distributed applications such as Apache HBase.
- Highly reliable data registry − It offers data availability even when one or a few nodes goes down.
Architecture of Zookeeper
Apache Zookeeper follows the Client-Server Architecture. The Zookeeper architecture has five different components that are:
- Ensemble
- Server
- Server Leader
- Follower
- Client
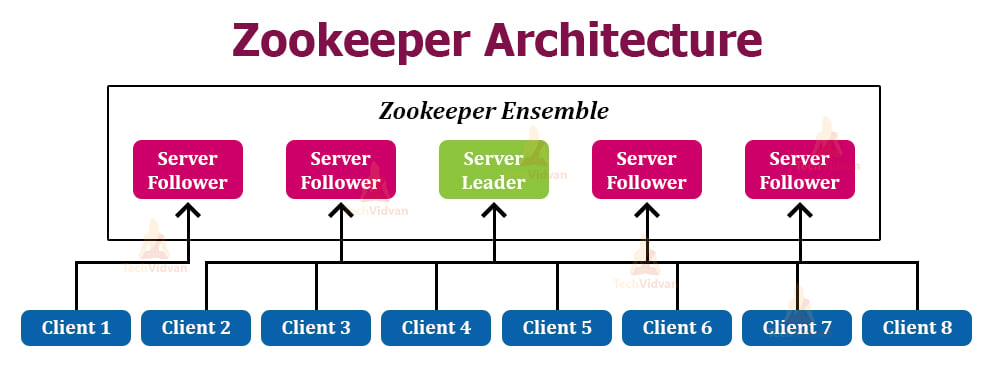
1. Ensemble
Ensemble is the collection of all the Server nodes in the Zookeeper ecosystem. Minimum three nodes are must for forming an ensemble.
2. Server
Server is one of the nodes present in the Zookeeper Ensemble. The main objective of the Server is to provide all the services to its clients. The Server sends its alive status to the client in order to acknowledge the client about its availability.
3. Server Leader
Server/Ensemble Leader is the server node that has access to recover the data from the failed nodes. It is responsible for performing automatic data recovery for the clients. It is elected at the service startup.
4. Follower
A follower is one of the server nodes in the Ensemble. It follows the orders given by the Leader.
5. Client
Clients are the nodes in the distributed system that request service from the server. The clients send the signals to the servers to inform them about their availability. If the server fails to respond, then the clients will automatically redirect themselves to the next available server.
How Zookeeper Works?
Writes in Zookeeper
In Zookeeper, all the writes go through the Master node. Due to this all the writes are sequential. While performing the write operation in Zookeeper, each of the servers which are attached to that client persists data along with the master.
This updates all the servers about the data. This also means that we cannot make concurrent writes. The guarantee for linear writes can be problematic if we use Zookeeper for writing dominant workload.
In Hadoop, we use Zookeeper for coordinating the message exchanges between the clients, that involves more reads and less writes. Zookeeper in Hadoop is helpful until the data is shared.
But in case if the application has the concurrent data writing, then Zookeeper may come in the way of the application and can impose strict ordering of the operations.
Reads in Zookeeper
Zookeeper is best at reads. Reads can be concurrent. In Zookeeper, concurrent reads are performed as each client is attached to a different server and all the clients can read data from the servers simultaneously.
It may sometimes happen that the client may have an outdated view. This gets updated within a little time.
Let us explore the Zookeeper Data model.
Zookeeper Data Model

A Zookeeper Data Model follows the hierarchical namespace. In hierarchical namespace, each node is called a Znode. Znode is the part of the system where the cluster functions.
In the above figure, we can see the Znode separated by a ‘/’.
Considering ‘/’ as a root, we have two more namespaces config and worker underlying the root.
These two nodes are the namespaces. The config namespace is for centralized configuration. The worker’s namespace is for the naming processes.
The main purpose of the Zookeeper data model is:
- To maintain the synchronization in a zookeeper cluster
- To explain the metadata of each Znode.
Node Types in Zookeeper
Basically, there are 3 types of Znodes. They are:
1. Persistence Znode
Persistence Znode are the nodes that stay alive even when the client who created the node is disconnected. All the server nodes in the ensemble assume themselves to be the Persistence Znodes.
2. Ephemeral Znode
The Ephemeral Znode are the nodes that stay alive until the client is alive or connected to them. They die when the client gets disconnected. Ephemeral Znode are not allowed to have children. They play an important role in the leader elections.
3. Sequential Znode
Sequential Znode can be either the Persistence Znode or the Ephemeral Znode. While creating a new Sequential Znode, the ZooKeeper sets the path of the Znode by attaching the 10 digit sequence number to the original name. This znode plays an important role in the Locking and Synchronization.
Zookeeper Command Line Interface
ZooKeeper Command Line Interface (CLI) is for interacting with the ZooKeeper ensemble for the development procedures. For performing any ZooKeeper CLI operations, we have to turn on our ZooKeeper server and afterwards the ZooKeeper client.
Once the Zookeeper client starts, we can perform the following operation.
1. Create znodes
It will create a new Znode in the cluster.
Syntax: create /path /data
Example: create /FirstZnode “Myzookeeper-app”
We can add -s flag for creating a Sequential znode and -e for Ephemeral znode.
2. Get Data
It will return the associated data of the znode and the metadata of the specified znode.
Syntax: get /path
Sample: get /FirstZnode
3. Watch
It shows the notification when the znode or the znode’s children data changes. We can set the watch only in the get command.
Syntax: get /path [watch] 1
Sample: get /FirstZnode 1
4. Set Data
It will set the data of the specified znode.
Syntax: set /path /data
Sample: set /SecondZnode updatedData
5. Create Children / Sub-znode
It will create the subordinate child nodes
Syntax: create /parent/path/subnode/path /data
Sample: create /FirstZnode/Child1 firstchildren
6. List children of a znode
We can list and display the children of a znode
Syntax: ls /path
Sample: ls /MyFirstZnode
7. Check Status
It will describe the metadata of the specified znode. It displays details such as Version number, ACL, Timestamp, Data length, and Children znode.
Syntax: stat /path
Sample: stat /FirstZnode
8. Remove a znode
It will remove the specified znode and recursively all its children.
Syntax: rmr /path
Sample: rmr /FirstZnode
Companies using Zookeeper
There are various companies that use Apache Zookeeper. Some of the companies that use Apache Zookeeper are:
- ebay
- Zynga
- Nutanix
- Yahoo
- Netflix
Refer to the Zookeeper application article to learn about how different companies are using Zookeeper.
Disadvantages of Zookeeper
- In Zookeeper, data may get lost when we are trying to add new Zookeeper Servers.
- It does not provide any support for Rack placement and awareness.
- We can not switch service to the host networking without performing a full reinstallation when a service is deployed on the virtual network.
- Zookeeper does not allow us to decrease the number of pods in order to prevent accidental data loss.
- In the communication network, messages can be lost. We require a special software for recovering it again.
- For users, no migration is allowed.
- Once the initial deployment is completed, the service does not support any changing volume requirements.
- There can be more points of failure because the large numbers of nodes are involved.
Summary
In short, we can say that Apache ZooKeeper is basically a distributed coordination service for managing a large set of hosts. Apache Zookeeper, with its simple architecture and API, solves the management of the distributed environment.
ZooKeeper framework provides the complete mechanism for overcoming all the challenges faced by the distributed applications. It offers various services like naming service, configuration management, etc.
I hope after reading this article, you have understood what Zookeeper is and why we use Zookeeper. The article had explained the reasons for using Zookeeper, Zookeeper architecture, Zookeeper Data model, and many more.
In this article, you have also explored the various operations that can be performed using the Zookeeper command-line interface. You can follow this tutorial guide to master Apache Zookeeper.