Apache Hadoop Architecture – HDFS, YARN & MapReduce
Explore the architecture of Hadoop, which is the most adopted framework for storing and processing massive data.
In this article, we will study Hadoop Architecture. The article explains the Hadoop architecture and the components of Hadoop architecture that are HDFS, MapReduce, and YARN. In the article, we will explore the Hadoop architecture in detail, along with the Hadoop Architecture diagram.
Let us now start with Hadoop Architecture.
Hadoop Architecture
The goal of designing Hadoop is to develop an inexpensive, reliable, and scalable framework that stores and analyzes the rising big data.
Apache Hadoop is a software framework designed by Apache Software Foundation for storing and processing large datasets of varying sizes and formats.
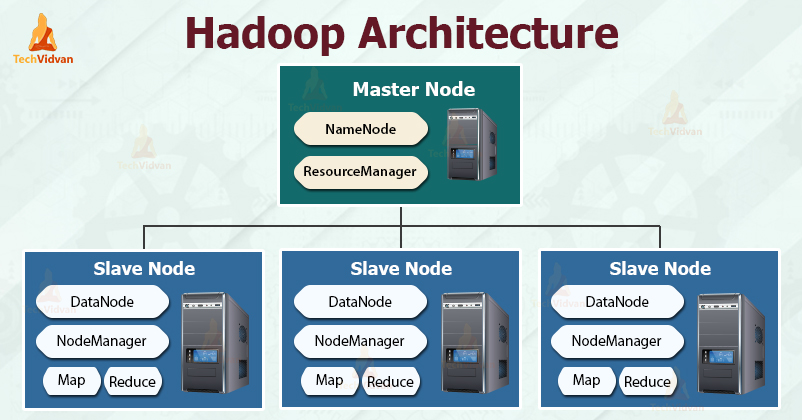
Hadoop follows the master-slave architecture for effectively storing and processing vast amounts of data. The master nodes assign tasks to the slave nodes.
The slave nodes are responsible for storing the actual data and performing the actual computation/processing. The master nodes are responsible for storing the metadata and managing the resources across the cluster.
Slave nodes store the actual business data, whereas the master stores the metadata.
The Hadoop architecture comprises three layers. They are:
- Storage layer (HDFS)
- Resource Management layer (YARN)
- Processing layer (MapReduce)
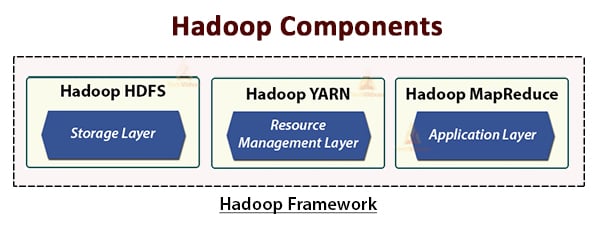
The HDFS, YARN, and MapReduce are the core components of the Hadoop Framework.
Let us now study these three core components in detail.
1. HDFS
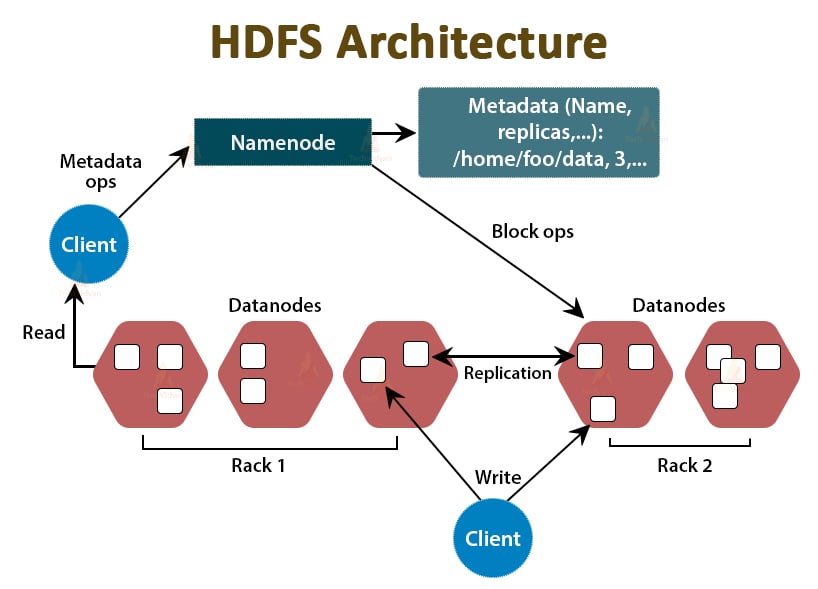
HDFS is the Hadoop Distributed File System, which runs on inexpensive commodity hardware. It is the storage layer for Hadoop. The files in HDFS are broken into block-size chunks called data blocks.
These blocks are then stored on the slave nodes in the cluster. The block size is 128 MB by default, which we can configure as per our requirements.
Like Hadoop, HDFS also follows the master-slave architecture. It comprises two daemons- NameNode and DataNode. The NameNode is the master daemon that runs on the master node. The DataNodes are the slave daemon that runs on the slave nodes.
NameNode
NameNode stores the filesystem metadata, that is, files names, information about blocks of a file, blocks locations, permissions, etc. It manages the Datanodes.
DataNode
DataNodes are the slave nodes that store the actual business data. It serves the client read/write requests based on the NameNode instructions.
DataNodes stores the blocks of the files, and NameNode stores the metadata like block locations, permission, etc.
2. MapReduce
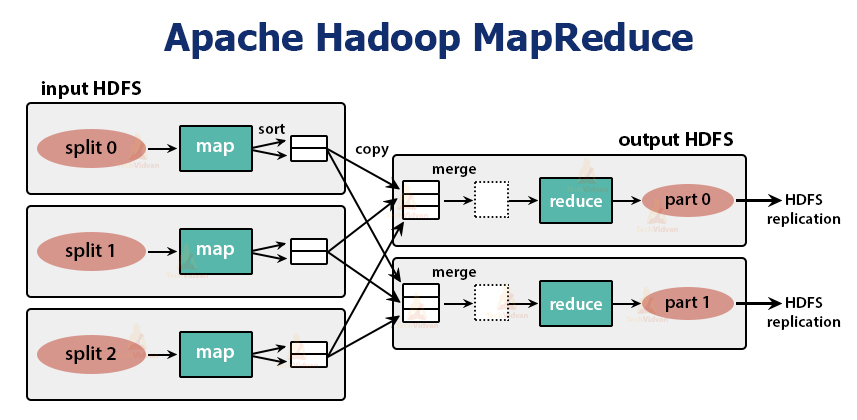
It is the data processing layer of Hadoop. It is a software framework for writing applications that process vast amounts of data (terabytes to petabytes in range) in parallel on the cluster of commodity hardware.
The MapReduce framework works on the <key, value> pairs.
The MapReduce job is the unit of work the client wants to perform. MapReduce job mainly consists of the input data, the MapReduce program, and the configuration information. Hadoop runs the MapReduce jobs by dividing them into two types of tasks that are map tasks and reduce tasks. The Hadoop YARN scheduled these tasks and are run on the nodes in the cluster.
Due to some unfavorable conditions, if the tasks fail, they will automatically get rescheduled on a different node.
The user defines the map function and the reduce function for performing the MapReduce job.
The input to the map function and output from the reduce function is the key, value pair.
The function of the map tasks is to load, parse, filter, and transform the data. The output of the map task is the input to the reduce task. Reduce task then performs grouping and aggregation on the output of the map task.
The MapReduce task is done in two phases-
1. Map phase
a. RecordReader
Hadoop divides the inputs to the MapReduce job into the fixed-size splits called input splits or splits. The RecordReader transforms these splits into records and parses the data into records but it does not parse the records itself. RecordReader provides the data to the mapper function in key-value pairs.
b. Map
In the map phase, Hadoop creates one map task which runs a user-defined function called map function for each record in the input split. It generates zero or multiple intermediate key-value pairs as map task output.
The map task writes its output to the local disk. This intermediate output is then processed by the reduce tasks which run a user-defined reduce function to produce the final output. Once the job gets completed, the map output is flushed out.
c. Combiner
Input to the single reduce task is the output from all the Mappers that is output from all map tasks. Hadoop allows the user to define a combiner function that runs on the map output.
Combiner groups the data in the map phase before passing it to Reducer. It combines the output of the map function which is then passed as an input to the reduce function.
d. Partitioner
When there are multiple reducers then the map tasks partition their output, each creating one partition for each reduce task. In each partition, there can be many keys and their associated values but the records for any given key are all in a single partition.
Hadoop allows users to control the partitioning by specifying a user-defined partitioning function. Generally, there is a default Partitioner that buckets the keys using the hash function.
2. Reduce phase:
The various phases in reduce task are as follows:
a. Sort and Shuffle:
The Reducer task starts with a shuffle and sort step. The main purpose of this phase is to collect the equivalent keys together. Sort and Shuffle phase downloads the data which is written by the partitioner to the node where Reducer is running.
It sorts each data piece into a large data list. The MapReduce framework performs this sort and shuffles so that we can iterate over it easily in the reduce task.
The sort and shuffling are performed by the framework automatically. The developer through the comparator object can have control over how the keys get sorted and grouped.
b. Reduce:
The Reducer which is the user-defined reduce function performs once per key grouping. The reducer filters, aggregates, and combines data in several different ways. Once the reduce task is completed, it gives zero or more key-value pairs to the OutputFormat. The reduce task output is stored in Hadoop HDFS.
c. OutputFormat
It takes the reducer output and writes it to the HDFS file by RecordWriter. By default, it separates key, value by a tab and each record by a newline character.

3. YARN
YARN stands for Yet Another Resource Negotiator. It is the resource management layer of Hadoop. It was introduced in Hadoop 2.
YARN is designed with the idea of splitting up the functionalities of job scheduling and resource management into separate daemons. The basic idea is to have a global ResourceManager and application Master per application where the application can be a single job or DAG of jobs.
YARN consists of ResourceManager, NodeManager, and per-application ApplicationMaster.
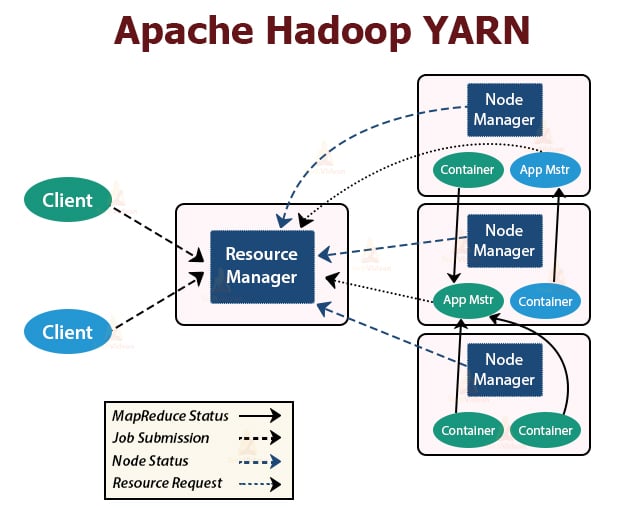
1. ResourceManager
It arbitrates resources amongst all the applications in the cluster.
It has two main components that are Scheduler and the ApplicationManager.
a. Scheduler
- The Scheduler allocates resources to the various applications running in the cluster, considering the capacities, queues, etc.
- It is a pure Scheduler. It does not monitor or track the status of the application.
- Scheduler does not guarantee the restart of the failed tasks that are failed either due to application failure or hardware failure.
- It performs scheduling based on the resource requirements of the applications.
b. ApplicationManager
- They are responsible for accepting the job submissions.
- ApplicationManager negotiates the first container for executing application-specific ApplicationMaster.
- They provide service for restarting the ApplicationMaster container on failure.
- The per-application ApplicationMaster is responsible for negotiating containers from the Scheduler. It tracks and monitors their status and progress.
2. NodeManager:
NodeManager runs on the slave nodes. It is responsible for containers, monitoring the machine resource usage that is CPU, memory, disk, network usage, and reporting the same to the ResourceManager or Scheduler.
3. ApplicationMaster:
The per-application ApplicationMaster is a framework-specific library. It is responsible for negotiating resources from the ResourceManager. It works with the NodeManager(s) for executing and monitoring the tasks.
Summary
In this article, we have studied Hadoop Architecture. The Hadoop follows master-slave topology. The master nodes assign tasks to the slave nodes. The architecture comprises three layers that are HDFS, YARN, and MapReduce.
HDFS is the distributed file system in Hadoop for storing big data. MapReduce is the processing framework for processing vast data in the Hadoop cluster in a distributed manner. YARN is responsible for managing the resources amongst applications in the cluster.
The HDFS daemon NameNode and YARN daemon ResourceManager run on the master node in the Hadoop cluster. The HDFS daemon DataNode and the YARN NodeManager run on the slave nodes.
HDFS and MapReduce framework run on the same set of nodes, which result in very high aggregate bandwidth across the cluster.
Keep Learning!!