What is Hadoop Cluster? Best Practices to Build Hadoop Clusters
Eager to learn each and everything about the Hadoop Cluster?
Hadoop is a software framework for analyzing and storing vast amounts of data across clusters of commodity hardware. In this article, we will study a Hadoop Cluster.
Let us first start with an introduction to Cluster.
What is a Cluster?
A Cluster is a collection of nodes. Nodes are nothing but a point of connection/intersection within a network.
A computer cluster is a collection of computers connected with a network, able to communicate with each other, and works as a single system.
What is Hadoop Cluster?
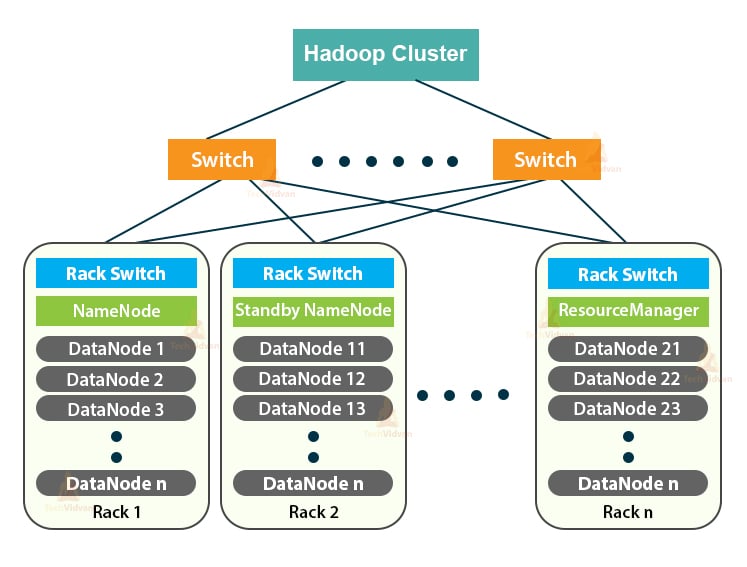
Hadoop Cluster is just a computer cluster used for handling a vast amount of data in a distributed manner.
It is a computational cluster designed for storing as well as analyzing huge amounts of unstructured or structured data in a distributed computing environment.
Hadoop Clusters are also known as Shared-nothing systems because nothing is shared between the nodes in the cluster except the network bandwidth. This decreases the processing latency.
Thus, when there is a need to process queries on the huge amount of data, the cluster-wide latency is minimized.
Let us now study the Architecture of Hadoop Cluster.
Architecture of Hadoop Cluster
The Hadoop Cluster follows a master-slave architecture. It consists of the master node, slave nodes, and the client node.
1. Master in Hadoop Cluster
Master in the Hadoop Cluster is a high power machine with a high configuration of memory and CPU. The two daemons that are NameNode and the ResourceManager run on the master node.
a. Functions of NameNode

NameNode is a master node in the Hadoop HDFS. NameNode manages the filesystem namespace. It stores filesystem meta-data in the memory for fast retrieval. Hence, it should be configured on high-end machines.
The functions of NameNode are:
- Manages filesystem namespace
- Stores meta-data about blocks of a file, blocks location, permissions, etc.
- It executes the filesystem namespace operations like opening, closing, renaming files and directories, etc.
- It maintains and manages the DataNode.
b. Functions of Resource Manager
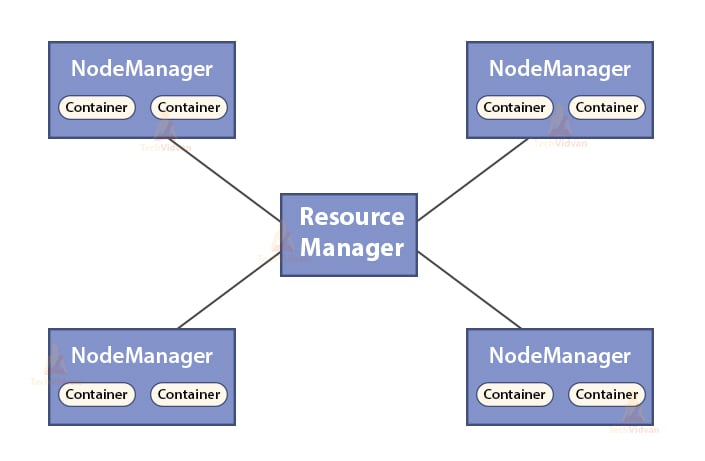
- ResourceManager is the master daemon of YARN.
- The ResourceManager arbitrates the resources among all the applications in the system.
- It keeps track of live and dead nodes in the cluster.
2. Slaves in the Hadoop Cluster
Slaves in the Hadoop Cluster are inexpensive commodity hardware. The two daemons that are DataNodes and the YARN NodeManagers run on the slave nodes.
a. Functions of DataNodes
- DataNodes stores the actual business data. It stores the blocks of a file.
- It performs block creation, deletion, replication based on the instructions from NameNode.
- DataNode is responsible for serving client read/write operations.
b. Functions of NodeManager
- NodeManager is the slave daemon of YARN.
- It is responsible for containers, monitoring their resource usage (such as CPU, disk, memory, network) and reporting the same to the ResourceManager.
- The NodeManager also checks the health of the node on which it is running.
3. Client Node in Hadoop Cluster
Client Nodes in Hadoop are neither master node nor slave nodes. They have Hadoop installed on them with all the cluster settings.
Functions of Client nodes
- Client nodes load data into the Hadoop Cluster.
- It submits MapReduce jobs, describing how that data should be processed.
- Retrieve the results of the job after processing completion.
We can scale out the Hadoop Cluster by adding more nodes. This makes Hadoop linearly scalable. With every node addition, we get a corresponding boost in throughput. If we have ‘n’ nodes, then adding 1 node gives (1/n) additional computing power.
Single Node Hadoop Cluster VS Multi-Node Hadoop Cluster
1. Single Node Hadoop Cluster
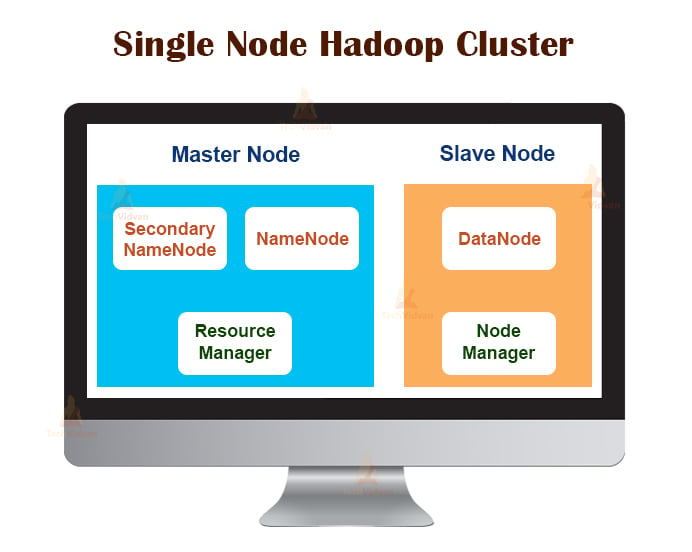
Single Node Hadoop Cluster is deployed on a single machine. All the daemons like NameNode, DataNode, ResourceManager, NodeManager run on the same machine/host.
In a single-node cluster setup, everything runs on a single JVM instance. The Hadoop user didn’t have to make any configuration settings except for setting the JAVA_HOME variable.
The default replication factor for a single node Hadoop cluster is always 1.
2. Multi-Node Hadoop Cluster
Multi-Node Hadoop Cluster is deployed on multiple machines. All the daemons in the multi-node Hadoop cluster are up and run on different machines/hosts.
A multi-node Hadoop cluster follows master-slave architecture. The daemons Namenode and ResourceManager run on the master nodes, which are high-end computer machines.
The daemons DataNodes and NodeManagers run on the slave nodes(worker nodes), which are inexpensive commodity hardware.
In the multi-node Hadoop cluster, slave machines can be present in any location irrespective of the location of the physical location of the master server.
Communication Protocols used in Hadoop Cluster
The HDFS communication protocols are layered on the top of the TCP/IP protocol. A client establishes a connection with the NameNode through the configurable TCP port on the NameNode machine.
The Hadoop Cluster establishes a connection to the client through the ClientProtocol. Moreover, the DataNode talks to the NameNode using the DataNode Protocol.
The Remote Procedure Call (RPC) abstraction wraps Client Protocol and DataNode protocol. By design, NameNode does not initiate any RPCs. It only responds to the RPC requests issued by clients or DataNodes.
Best Practices for building Hadoop Cluster
The performance of a Hadoop Cluster depends on various factors based on the well-dimensioned hardware resources that use CPU, memory, network bandwidth, hard drive, and other well-configured software layers.
Building a Hadoop Cluster is a non-trivial job. It requires consideration of various factors like choosing the right hardware, sizing the Hadoop Clusters, and configuring the Hadoop Cluster.
Let us now see each one in detail.
1. Choosing Right Hardware for Hadoop Cluster
Many organizations, when setting up Hadoop infrastructure, are in a predicament as they are not aware of the kind of machines they need to purchase for setting up an optimized Hadoop environment, and the ideal configuration they must use.
For choosing the right hardware for the Hadoop Cluster, one must consider the following points:
- The volume of Data that cluster will be going to handle.
- The type of workloads the cluster will be dealing with ( CPU bound, I/O bound).
- Data storage methodology like data containers, data compression techniques used, if any.
- A data retention policy, that is, how long we want to keep the data before flushing it out.
2. Sizing the Hadoop Cluster
For determining the size of the Hadoop Cluster, the data volume that the Hadoop users will process on the Hadoop Cluster should be a key consideration.
By knowing the volume of data to be processed, helps in deciding how many nodes will be required in processing the data efficiently and memory capacity required for each node. There should be a balance between the performance and the cost of the hardware approved.
3. Configuring Hadoop Cluster
Finding the ideal configuration for the Hadoop Cluster is not an easy job. Hadoop framework must be adapted to the cluster it is running and also to the job.
The best way of deciding the ideal configuration for the Hadoop Cluster is to run the Hadoop jobs with the default configuration available in order to get a baseline. After that, we can analyze the job history log files to see if there is any resource weakness or the time taken to run the jobs is higher than expected.
If it is so, then change the configuration. Repeating the same process can tune the Hadoop Cluster configuration that best fits the business requirements.
The performance of the Hadoop Cluster greatly depends on the resources allocated to the daemons. For small to medium data context, Hadoop reserves one CPU core on each DataNode, whereas, for the long datasets, it allocates 2 CPU cores on each DataNode for HDFS and MapReduce daemons.
Hadoop Cluster Management
On deploying the Hadoop Cluster in production, it is apparent that it should scale along all dimensions that are volume, variety, and velocity.
Various features that it should be posses to become production-ready are – round the clock availability, robust, manageability, and performance. Hadoop Cluster management is the main facet of the big data initiative.
The best tool for Hadoop Cluster management should have the following features:-
- It must ensure 24×7 high availability, resource provisioning, diverse security, work-load management, health monitoring, performance optimization. Also, it needs to provide job scheduling, policy management, back up, and recovery across one or more nodes.
- Implement redundant HDFS NameNode high availability with load balancing, hot standbys, resynchronization, and auto-failover.
- Enforcing policy-based controls that prevent any application from grabbing a disproportionate share of resources on an already maxed-out Hadoop Cluster.
- Performing regression testing for managing the deployment of any software layers over Hadoop clusters. This is to make sure that any jobs or data would not get crash or encounter any bottlenecks in daily operations.
Benefits of Hadoop Cluster
The various benefits provided by the Hadoop Cluster are:
1. Scalable
Hadoop Clusters are scalable. We can add any number of nodes to the Hadoop Cluster without any downtime and without any extra efforts. With every node addition, we get a corresponding boost in throughput.
2. Robustness
The Hadoop Cluster is best known for its reliable storage. It can store data reliably, even in cases like DataNode failure, NameNode failure, and network partition. The DataNode periodically sends a heartbeat signal to the NameNode.
In network partition, a set of DataNodes gets detached from the NameNode due to which NameNode does not receive any heartbeat from these DataNodes. NameNode then considers these DataNodes as dead and does not forward any I/O request to them.
Also, the replication factor of the blocks stored in these DataNodes falls below their specified value. As a result, NameNode then initiates the replication of these blocks and recovers from the failure.
3. Cluster Rebalancing
The Hadoop HDFS architecture automatically performs cluster rebalancing. If the free space in the DataNode falls below the threshold level, then HDFS architecture automatically moves some data to other DataNode where enough space is available.
4. Cost-effective
Setting up the Hadoop Cluster is cost-effective because it comprises inexpensive commodity hardware. Any organization can easily set up a powerful Hadoop Cluster without spending much on expensive server hardware.
Also, Hadoop Clusters with its distributed storage topology overcome the limitations of the traditional system. The limited storage can be extended just by adding additional inexpensive storage units to the system.
5. Flexible
Hadoop Clusters are highly flexible as they can process data of any type, either structured, semi-structured, or unstructured and of any sizes ranging from Gigabytes to Petabytes.
6. Fast Processing
In Hadoop Cluster, data can be processed parallelly in a distributed environment. This provides fast data processing capabilities to Hadoop. Hadoop Clusters can process Terabytes or Petabytes of data within a fraction of seconds.
7. Data Integrity
To check for any corruption in data blocks due to buggy software, faults in a storage device, etc. the Hadoop Cluster implements checksum on each block of the file. If it finds any block corrupted, it seeks it form another DataNode that contains the replica of the same block. Thus, the Hadoop Cluster maintains data integrity.
Summary
After reading this article, we can say that the Hadoop Cluster is a special computational cluster designed for analyzing and storing big data. Hadoop Cluster follows master-slave architecture.
The master node is the high-end computer machine, and the slave nodes are machines with normal CPU and memory configuration. We have also seen that the Hadoop Cluster can be set up on a single machine called single-node Hadoop Cluster or on multiple machines called multi-node Hadoop Cluster.
In this article, we had also covered the best practices to be followed while building a Hadoop Cluster. We had also seen many advantages of the Hadoop Cluster, including scalability, flexibility, cost-effectiveness, etc.