HDFS NameNode High Availability in Hadoop
In our previous blog, we have studied Hadoop Introduction and Features of Hadoop, Now in this blog, we are going to cover the HDFS NameNode High Availability feature in detail.
First of all, we will discuss the HDFS NemNode High Availability Architecture, next with the implementation of Hadoop High Availability Architecture using Quorum Journal Nodes and Shared Storage.
HDFS NameNode High Availability
In HDFS, data is highly available and accessible despite hardware failure. HDFS is the most reliable storage system designed for storing very large files.
HDFS follows master/slave topology. In which master is NameNode and slaves is DataNode. NameNode stores meta-data. Metadata include the number of blocks, their location, replicas, and other details. For the faster retrieval of data, metadata is available in the master. NameNode maintains and assigns tasks to the slave node.
NameNode was the Single Point of Failure (SPOF) before Hadoop 2.0. HDFS cluster had a single NameNode. If the NameNode fails, the whole cluster goes down.
Single point of failure limits high availability in following ways:
- If any unplanned event triggers, like node crashes, then cluster would be unavailable unless an operator restarted the new namenode.
- Also planned maintenance activities like hardware upgrades on the NameNode will result in downtime of the Hadoop cluster.
HDFS NameNode High Availability Architecture
Introduction of Hadoop 2.0 overcome this SPOF by providing support to multiple NameNode. HDFS NameNode High Availability architecture provides the option of running two redundant NameNodes in the same cluster in an active/passive configuration with a hot standby.
- Active NameNode – It handles all HDFS client operations in the HDFS cluster.
- Passive NameNode – It is a standby namenode. It has similar data as active NameNode.
So, whenever Active NameNode fails, passive NameNode will take all the responsibility of active node. Thus, HDFS cluster continues to work.
Issues in maintaining consistency in the HDFS High Availability cluster are as follows:
- Active and Standby NameNode should always be in sync with each other, i.e. they should have the same metadata. This permit to reinstate the Hadoop cluster to the same namespace state where it got crashed. And this will provide us to have fast failover.
- There should be only one NameNode active at a time. Otherwise, two NameNode will lead to corruption of the data. We call this scenario as a “Split-Brain Scenario”, where a cluster gets divided into the smaller cluster. Each one believes that it is the only active cluster. “Fencing” avoids such Fencing is a process of ensuring that only one NameNode remains active at a particular time.
Implementation of Hadoop High Availability Architecture
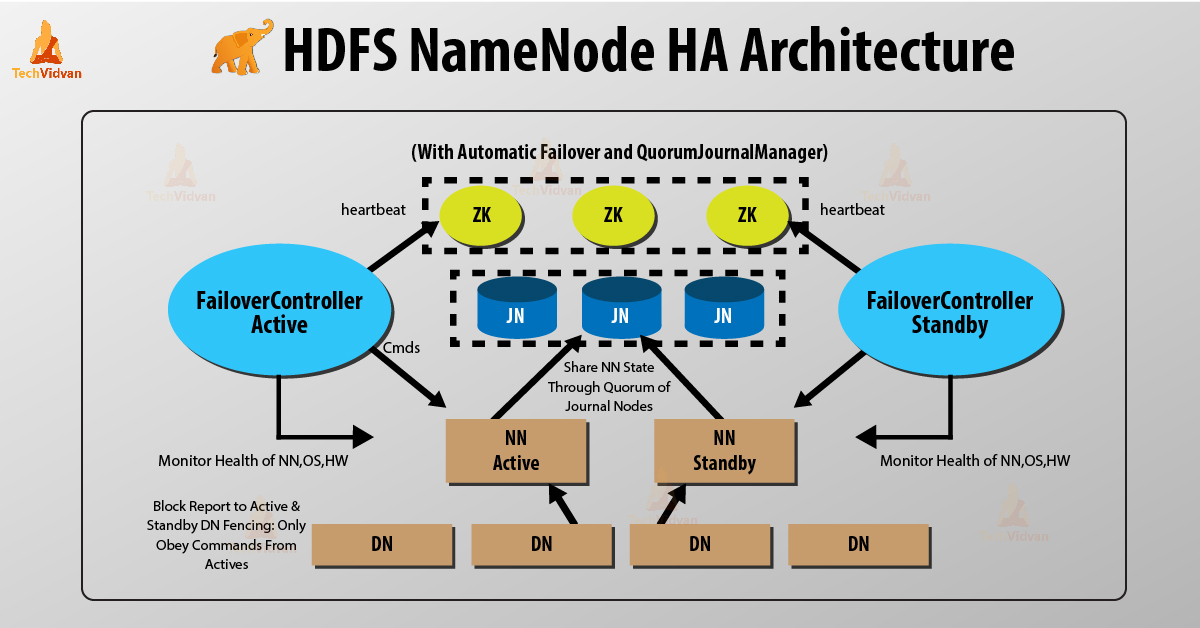
Two NameNodes run at the same time in HDFS NameNode High Availability Architecture. HDFS client can implement the Active and Standby NameNode configuration in following two ways:
- Using Quorum Journal Nodes
- Using Shared Storage
1. Using Quorum Journal Nodes
Quorum Journal Nodes is an HDFS implementation. QJN provides edit logs. It permits to share these edit logs between the active and standby NameNode.
Standby Namenode communicates and synchronizes with the active NameNode for high availability. It will happen by a group of daemons called “Journal nodes”. The Quorum Journal Nodes runs as a group of journal nodes. At least three journal nodes should be there.
For N journal nodes, the system can tolerate at most (N-1)/2 failures. The system thus continues to work. So, for three journal nodes, the system can tolerate the failure of one {(3-1)/2} of them.
Whenever an active node performs any modification, it logs modification to all journal nodes.
The standby node reads the edits from the journal nodes and applies to its own Namespace in a constant manner. In the case of failover, the standby will ensure that it has read all the edits from the journal nodes before promoting itself to the Active state. This ensures that the namespace state is completely synchronized before a failure occurs.
To provide a fast failover, the standby node must have up-to-date information about the location of data blocks in the cluster. For this to happen, IP address of both the NameNode is available to all the datanodes and they send block location information and heartbeats to both NameNode.
Fencing of NameNode
For the correct operation of an HA cluster, only one of the NameNodes should active at a time. Otherwise, the namespace state would deviate between the two NameNodes. So, fencing is a process to ensure this property in a cluster.
- The journal nodes perform this fencing by allowing only one NameNode to be the writer at a time.
- The standby NameNode takes the responsibility of writing to the journal nodes and prohibit any other NameNode to remain active.
- Finally, the new active NameNode can perform its activities.
2. Using Shared Storage
Standby and active NameNode synchronize with each other by using “shared storage device”. For this implementation, both active NameNode and standby Namenode must have access to the particular directory on the shared storage device (.i.e. Network file system).
When active NameNode perform any namespace modification, it logs a record of the modification to an edit log file stored in the shared directory. The standby NameNode watches this directory for edits, and when edits occur, the standby NameNode applies them to its own namespace. In the case of failure, the standby NameNode will ensure that it has read all the edits from the shared storage before promoting itself to the Active state. This ensures that the namespace state is completely synchronized before failover occurs.
To prevent the “split-brain scenario” in which the namespace state deviates between the two NameNode, an administrator must configure at least one fencing method for the shared storage.
Conclusion
Hence, Hadoop 2.0 HDFS HA provide for single active NameNode and single standby NameNode. But some deployments need a high degree of fault tolerance. Hadoop new version 3.0, allows the user to run many standby NameNodes.
For example, configuring five journalnodes and three NameNode. As a result hadoop cluster is able to tolerate the failure of two nodes rather than one.
Please share your experience and suggestions in related to HDFS NameNode High Availability in the comment section below.