What is Hadoop Reducer Class in MapReduce?
Till now we have covered the Hadoop introduction and Hadoop HDFS in detail. In this tutorial, we will provide you a detailed description of Hadoop Reducer.
Here will discuss what is Reducer in MapReduce, how Reducer works in Hadoop MapReduce, different phases of Hadoop Reducer, how can we change the number of Reducer in Hadoop MapReduce.
What is Hadoop Reducer?
Reducer in Hadoop MapReduce reduces a set of intermediate values which share a key to a smaller set of values.
In MapReduce job execution flow, Reducer takes a set of an intermediate key-value pair produced by the mapper as the input. Then, Reducer aggregate, filter and combine key-value pairs and this requires a wide range of processing.
One-one mapping takes place between keys and reducers in MapReduce job execution. They run in parallel since they are independent of one another. The user decides the number of reducers in MapReduce.
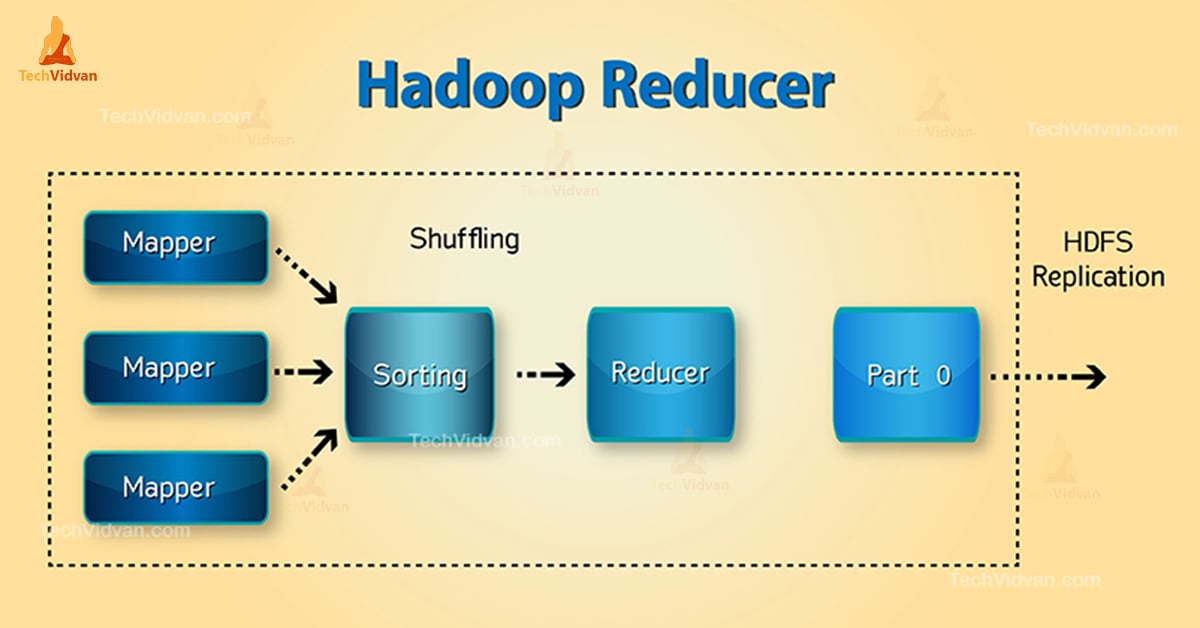
Phases of Hadoop Reducer
Three phases of Reducer are as follows:
1. Shuffle Phase
This is the phase in which sorted output from the mapper is the input to the reducer. The framework with the help of HTTP fetches the relevant partition of the output of all the mappers in this phase.Sort phase
2. Sort Phase
This is the phase in which the input from different mappers is again sorted based on the similar keys in different Mappers.
Both Shuffle and Sort occur concurrently.
3. Reduce Phase
This phase occurs after shuffle and sort. Reduce task aggregates the key-value pairs. With the OutputCollector.collect() property, the output of the reduce task is written to the FileSystem. Reducer output is not sorted.
Number of Reducers in Hadoop MapReduce
User set the number of reducers with the help of Job.setNumreduceTasks(int) property. Thus the right number of reducers by the formula:
0.95 or 1.75 multiplied by (<no. of nodes> * <no. of the maximum container per node>)
So, with 0.95, all reducers immediately launch. Then, start transferring map outputs as the maps finish.
Faster node finishes the first round of reducers with 1.75. Then it launches the second wave of reducer which does much better job of load balancing.
With the increase of the number of reducers:
- Framework overhead increases.
- Load balancing increases.
- Cost of failures decreases.
Conclusion
Hence, Reducer takes mappers output as input. Then, process the key-value pairs and produces the output. Reducer output is the final output. If you like this blog or you have any query related to Hadoop Reducer, so please share with us by leaving a comment.
Hope we will help you out.