How Hadoop Works – Understand the Working of Hadoop
Seeking to know how Hadoop actually stores and processes vast amounts of data?
In this article, we will study how Hadoop works Internally. We will see how Hadoop stores and processes large datasets. The article explains in detail about Hadoop working. The article first gives a short introduction to Hadoop.
Then we will see the Hadoop core components and the Daemons running in the Hadoop cluster. The article then explains the working of Hadoop covering all its core components such as HDFS, MapReduce, and YARN.
So let us now first see the short introduction to Hadoop.
Introduction to Hadoop
With the rising Big data, Apache Software Foundation in 2008 developed an open-source framework known as Apache Hadoop, which is a solution to all the big data problems.
Apache Hadoop is a framework that can store and process huge amounts of unstructured data ranging in size from terabytes to petabytes. It is a highly fault-tolerant and highly available system.
Hadoop stores a massive amount of data in a distributed manner in HDFS. The Hadoop MapReduce is the processing unit in Hadoop, which processes the data in parallel.
Hadoop YARN is another core component in the Hadoop framework, which is responsible for managing resources amongst applications running in the cluster and scheduling the task.
Before studying how Hadoop works internally, let us first see the main components and daemons of Hadoop.
Components and Daemons of Hadoop
The Hadoop consists of three major components that are HDFS, MapReduce, and YARN.
1. Hadoop HDFS
It is the storage layer for Hadoop. Hadoop Distributed File System stores data across various nodes in a cluster. It divides the data into blocks and stores them on different nodes. The block size is 128 MB by default. We can configure the block size as per our requirements.
2. Hadoop MapReduce
It is the processing layer in Hadoop. Hadoop MapReduce processes the data stored in Hadoop HDFS in parallel across various nodes in the cluster. It divides the task submitted by the user into the independent task and processes them as subtasks across the commodity hardware.
3. Hadoop YARN
It is the resource and process management layer of Hadoop. YARN is responsible for sharing resources amongst the applications running in the cluster and scheduling the task in the cluster.
These are the three core components in Hadoop.
Daemons running in the Hadoop Cluster
There are some Daemons that run on the Hadoop Cluster. Daemons are the light-weight process that runs in the background.
Some Daemons run on the Master node and some on the Slave node. Let us now study the Hadoop Daemons.
The major Hadoop Daemon are:
1. Master Daemons
- NameNode: It is the master Daemon in Hadoop HDFS. It maintains the filesystem namespace. It stores metadata about each block of the files.
- ResourceManager: It is the master daemon of YARN. It arbitrates resources amongst all the applications running in the cluster.
2. Slave Daemons
- DataNode: DataNode is the slave daemon of Hadoop HDFS. It runs on slave machines. It stores actual data or blocks.
- NodeManager: It is the slave daemon of YARN. It takes care of all the individual computing nodes in the cluster.
How Hadoop works?
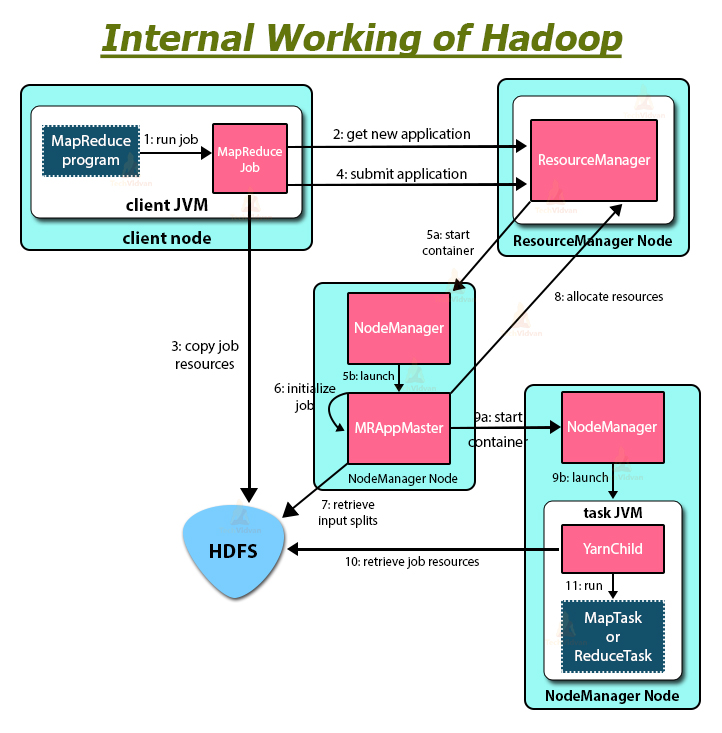
Hadoop stores and processes the data in a distributed manner across the cluster of commodity hardware. To store and process any data, the client submits the data and program to the Hadoop cluster.
Hadoop HDFS stores the data, MapReduce processes the data stored in HDFS, and YARN divides the tasks and assigns resources.
Let us now look at these components in detail.
1. HDFS
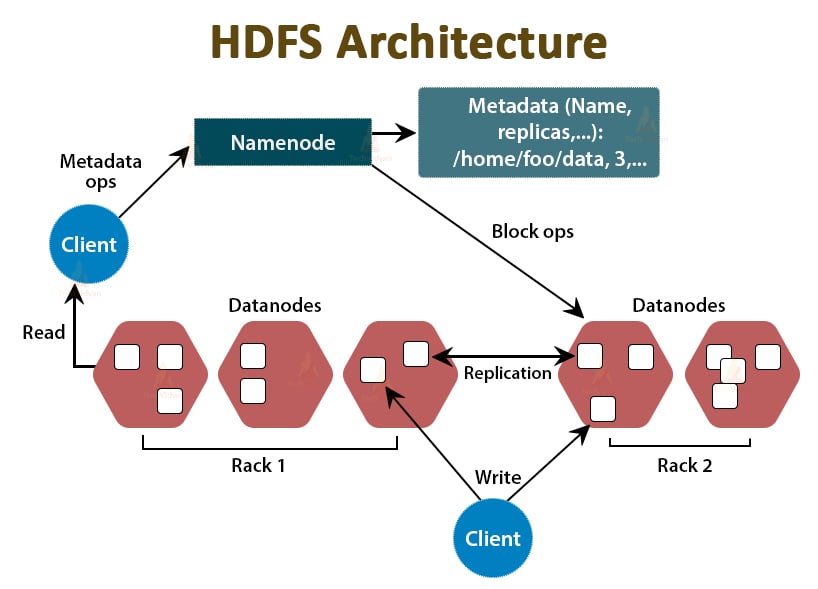
The data in Hadoop is stored in the Hadoop Distributed File System. There are two daemons running in Hadoop HDFS that are NameNode and DataNode.
a. NameNode
NameNode is the master daemon in HDFS. It runs on the master nodes. It maintains the filesystem namespace. NameNode does not store the actual data. It stores the metadata, such as information about blocks of files, files permission, blocks locations, etc.
NameNode manages the DataNode and provides instructions to them. NameNode receives a heart-beat from DataNodes every 3 seconds, which specifies that the DataNode is alive.
b. DataNode
DataNode is the slave daemon in HDFS. DataNodes are the slave nodes that store the actual business data. They are responsible for serving the client’s read/write requests based on the instructions from NameNode. DataNodes send heart-beat messages to the NameNode to ensure that they are alive.
c. Secondary NameNode
It is another daemon in the Hadoop HDFS. It is the helper node for the primary NameNode. Secondary NameNode downloads the edit logs and Fsimage file from the primary NameNode and periodically applies the edit logs to Fsimage.
Then it sends back the updated Fsimage file to the NameNode. So, if the primary NameNode fails, the last save Fsimage on the secondary NameNode is used to recover file system metadata.
Whenever the client wants to read or write data to Hadoop HDFS, it first interacts with the NameNode. NameNode first checks for the client privileges, and if the client has sufficient privileges, then the NameNode provides the address of the DataNodes from where the client can read or write data.
The client’s file in HDFS is divided into blocks. The block size is 128 MB by default. DataNode stores the blocks of files. To provide fault-tolerance, HDFS creates replicas of blocks depending on the replication factor.
By default replication factor is 3, which means 3 copies of a block are stored in HDFS. HDFS stores replicas of the block on different DataNodes by following the Rack Awareness algorithm.
During file read, if any DataNode goes down, the NameNode provides the address of another DataNode containing a replica of the block from where the client can read its data without any downtime.
2. MapReduce
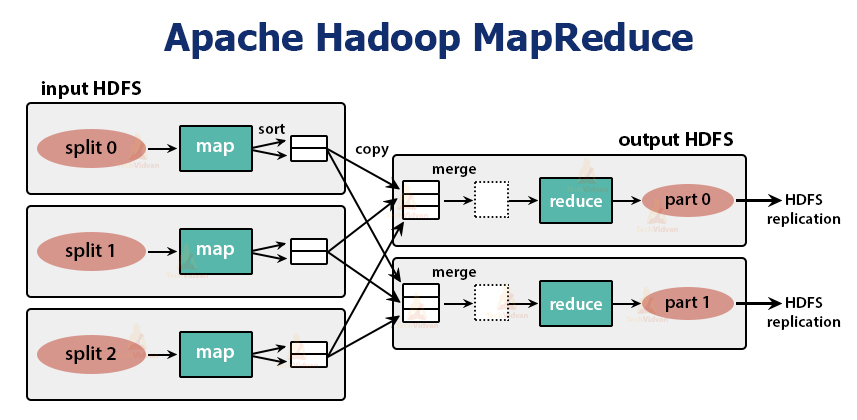
MapReduce is the processing layer in Hadoop. It processes the data in parallel across multiple machines in the cluster. It works by dividing the task into independent subtasks and executes them in parallel across various DataNodes.
MapReduce processes the data into two-phase, that is, the Map phase and the Reduce phase. The input and output of both the phases are the key, value pairs. The type of key, value pairs is specified by the programmer through the InputFormat class. By default, the text input format is used.
The programmer specifies the two functions, that is, map function and the reduce function. In map function, the programmer writes the business logic for processing the data.
In the Reduce function, the programmer writes the logic for summarizing and aggregating the intermediate output of the map function and generates the output.
Working of Hadoop MapReduce
Whenever the client wants to perform any processing on its data in the Hadoop cluster, then it first stores the data in Hadoop HDFS and then writes the MapReduce program for processing the Data. The Hadoop MapReduce works as follows:
1. Hadoop divides the job into tasks of two types, that is, map tasks and reduce tasks. YARN scheduled these tasks (which we will see later in this article). These tasks run on different DataNodes.
2. The input to the MapReduce job is divided into fixed-size pieces called input splits.
3. One map task which runs a user-defined map function for each record in the input split is created for each input split. These map tasks run on the DataNodes where the input data resides.
4. The output of the map task is intermediate output and is written to the local disk.
5. The intermediate outputs of the map tasks are shuffled and sorted and are then passed to the reducer.
6. For a single reduce task, the sorted intermediate output of mapper is passed to the node where the reducer task is running. These outputs are then merged and then passed to the user-defined reduce function.
7. The reduce function summarizes the output of the mapper and generates the output. The output of the reducer is stored on HDFS.
8. For multiple reduce functions, the user specifies the number of reducers. When there are multiple reduce tasks, the map tasks partition their output, creating one partition for each reduce task.
YARN
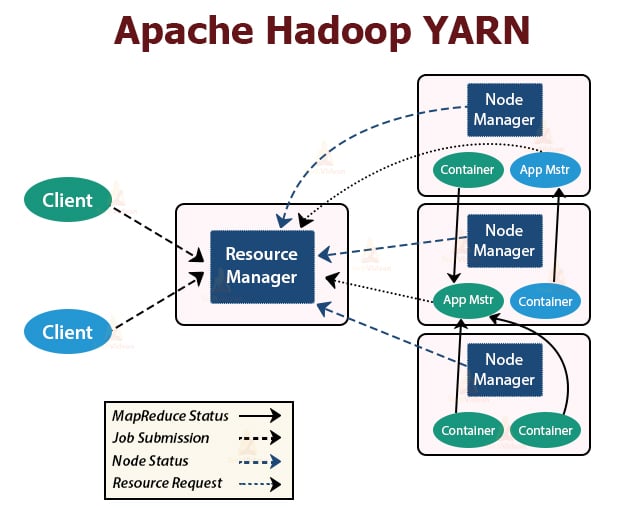
YARN is the resource management layer in Hadoop. It schedules the task in the Hadoop cluster and assigns resources to the applications running in the cluster. It is responsible for providing the computational resources needed for executing the applications.
There are two YARN daemons running in the Hadoop cluster for serving YARN core services. They are:
a. ResourceManager
It is the master daemon of YARN. It runs on the master node per cluster to manage the resources across the cluster. The ResourceManager has two major components that are Scheduler and ApplicationManager.
The scheduler allocates resources to various applications running in the cluster.
ApplicationManager takes up the job submitted by the client, and negotiates the container for executing the application-specific ApplicationMaster, and restarts the ApplicationMaster container on failure.
b. NodeManager
NodeManager is the slave daemons of YARN. It runs on all the slave nodes in the cluster. It is responsible for launching and managing the containers on nodes. Containers execute the application-specific processes with a constrained set of resources such as memory, CPU, and so on.
When NodeManager starts, it announces himself to the ResourceManager. It periodically sends a heartbeat to the ResourceManager. It offers resources to the cluster.
c. ApplicationMaster
The per-application ApplicationMaster negotiates containers form schedulers and tracks container status and monitors the container progress.
A client submits an application to the ResourceManager. The ResourceManager contacts the NodeManager that launches and monitors the compute containers on nodes in the cluster. The container executes the ApplicationMaster.
The MapReduce task and the ApplicationMaster run in containers which are scheduled by the ResourceManager and managed by the NodeManagers.
Let us now summarize how Hadoop works internally:
1. HDFS divides the client input data into blocks of size 128 MB. Depending on the replication factor, replicas of blocks are created. The blocks and their replicas are stored on different DataNodes.
2. Once all blocks are stored on HDFS DataNodes, the user can process the data.
3. To process the data, the client submits the MapReduce program to Hadoop.
4. ResourceManager then scheduled the program submitted by the user on individual nodes in the cluster.
5. Once all nodes complete processing, the output is written back to the HDFS.
Summary
In this article, we have studied the entire working of Hadoop. I hope after reading this article, you understand how Hadoop stores and processes massive amounts of data.
The article also explains how the resources are scheduled among the applications in the resources. The article describes the major daemons running in the Hadoop cluster and the core components of Hadoop.
I hope you understand how Hadoop works internally.
Keep Learning!!