Impala Tutorial for Beginners
Impala is an open-source and a native analytic database for Hadoop. Vendors such as Cloudera, Oracle, MapR, and Amazon shipped Impala. If you want to learn each and everything related to Impala then you have landed in the right place.
This Impala tutorial will explain the main points and concepts related to Impala. It is basically used to process huge amounts of data at fast speed by using traditional SQL knowledge.
For learning Impala, you should be little familiar with the basics of Apache Hadoop, and the HDFS commands. The basic knowledge of SQL is the plus point in learning Impala.
What is Impala?
Impala is an open-source and the native analytic database for Hadoop. It is a Massive Parallel Processing (MPP) SQL query engine that processes vast amounts of data stored in the Hadoop cluster.
When compared to the other SQL engines for Apache Hadoop, such as Hive, Impala provides high performance and low latency.
In simpler words, we can say that Impala is the best performing SQL engine that provides the fastest way for accessing the data stored in the HDFS (Hadoop Distributed File System). Impala is written in C++ and Java.
Apache Impala raises the bar for the SQL query performance on Hadoop while retaining the familiar user experience. With Apache Impala, we can query data stored either in HDFS or in Apache HBase. We can perform operations like SELECT, JOIN, and aggregate functions in real-time with Impala.
Apache Impala uses the same SQL syntax (Hive Query Language), metadata, user interface, and ODBC drivers as Apache Hive thus provides a familiar and unified platform for the batch-oriented or the real-time queries.
This allows Hive users to utilize Apache Impala with the little setup overhead. However, all the SQL-queries are not supported by Impala, there can be a few syntactic changes. The Impala Query Language is the subset of the Hive Query Language, with some functional limitations such as transforms.
Reasons for using Apache Impala
1. Apache Impala combines flexibility and scalability of Hadoop with the SQL support and multi-user performance of the traditional analytic database, by using components such as HDFS, Metastore, HBase, Sentry, and YARN.
2. With Apache Impala, users can easily communicate with the HDFS or HBase by using SQL like queries in a faster way as compared to the other SQL engines like Apache Hive.
3. Apache Impala can read almost every file format like Parquet, RCFile, Avro, used by Apache Hadoop.
4. Moreover, it uses the same SQL syntax (Hive SQL), metadata, user interface, and ODBC driver as Apache Hive, thus providing a familiar and unified platform for the batch-oriented or the real-time queries.
5. Also, Impala is not based on the MapReduce algorithms like Apache Hive does. It implements a distributed architecture based on the daemon processes that are responsible for all the aspects of the query execution. Thus this reduces the latency of using MapReduce and makes Apache Impala faster and better than Apache Hive.
Where to use Apache Impala
- When there is a need for the low latent results, we can use Impala.
- When we need to analyze the partial data, then we can use Apache Impala.
- For doing any quick analysis, we can opt for Impala.
- We can use Apache Impala when we need to obtain results in real-time.
- Apache Impala is best when we need to process the same kind of queries several times.
Architecture of Apache Impala
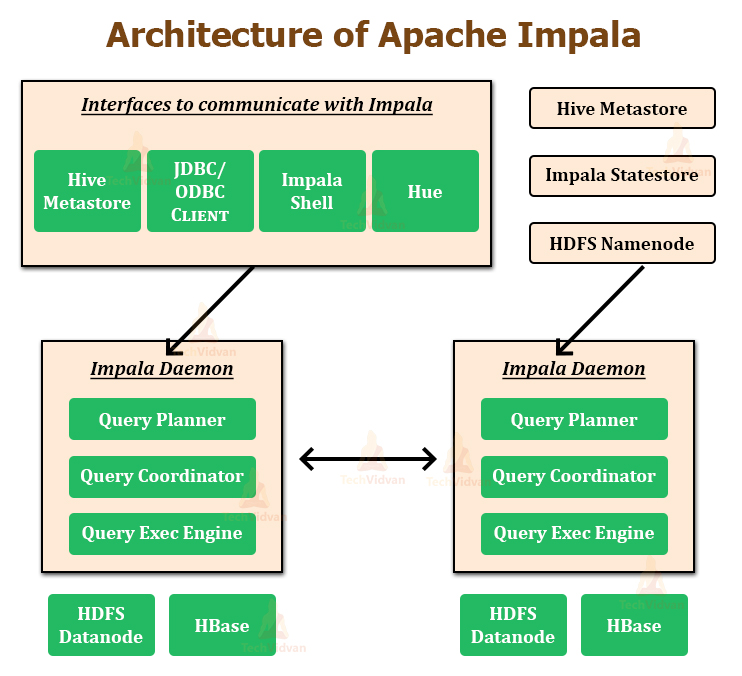
The above image depicts Impala Architecture. Apache Impala runs on the number of systems in the Apache Hadoop cluster. Unlike the traditional storage systems, Apache impala is not coupled with its storage engine.
It is decoupled with its storage engine. Impala has three core components, that are, Impala daemon (Impalad), Impala Statestore, and the Impala Catalog services.
Let us see each one in detail.
1. Impala Daemon
Impala daemon is the core component of Apache Impala. It is physically represented by an impalad process. Impala daemon runs on each machine where Impala is installed. The main functions of Impala daemon are:
- It performs reads and writes to the data files.
- It accepts the queries transferred from the impala-shell command, JDBC, Hue, or ODBC.
- Impala Daemon parallelizes the queries and distributes the work across the Hadoop cluster.
- It transmits the intermediate query results back to the central coordinator.
- The Impala daemons constantly communicate with the StateStore in order to confirm which daemons are healthy and are ready to accept new work.
- Also, Impala daemons receive the broadcast messages from the catalogd daemon (discussed below) whenever
- Any of the Impala daemon either creates, drops, or alters, any type of object.
- When Impala processes the INSERT or the LOAD DATA statement.
We can deploy Impala daemons in one of the following ways:
- Co-locate HDFS and Impala, and each Impala daemon should run on the same host as the DataNode.
- Deploy Impala separately in a compute cluster, and it can read data remotely from the HDFS, S3, ADLS, etc.
2. Impala Statestore
Impala Statestore is the one who checks on the health of all the Impala daemons in the cluster, and continuously passes on its findings to each of the Impala daemons. The Impala Statestore is physically represented by the daemon process named statestored.
We only need a statestore process on one host in the cluster. So, if any of the Impala daemon goes offline because of a network error, hardware failure, software issue, or any other reason, then the Impala StateStore informs all the other Impala daemons.
This is done to ensure that the future queries do not make requests to the failed Impala daemon.
Impala Statestore is not always critical for the normal operation of the Impala cluster. If in case the StateStore is not running, then also the Impala daemons will run and distribute the work among themselves as usual.
In this case, the cluster becomes less robust when the other Impala daemons fail, and the metadata will become less consistent. When the Impala StateStore comes back, then it re-establishes the communication with all the Impala daemons and continues its monitoring and broadcasting functions.
3. Impala Catalog Service
The Catalog Service is another Impala component that passes the metadata changes from the Impala SQL statements to all the Impala daemons in the cluster. The Impala Catalog Service is physically represented by the daemon process named catalogd.
We only need a catalogd process on the one host in the cluster. Since the requests are passed via the StateStore daemon, it is best to run the statestored and catalogd process on the same host.
The Impala catalog service prevents the need for issuing REFRESH and the INVALIDATE METADATA statements when the metadata changes were performed by the statements issued through Apache Impala.
When we create a table or load data through Apache Hive, then we have to issue the REFRESH or the INVALIDATE METADATA on the Impala node before executing any query there.
Note:
The features like load balancing and high availability are applied to an impalad daemon. The process such as statestored and catalogd do not have any special requirements for the high availability, because failure in any of them does not result in the data loss.
If any of these two daemons become unavailable because of an outage on the particular host, then we can stop the Impala service by:
- Deleting the Impala StateStore and the Impala Catalog Server roles,
- And then adding the roles on the different host,
- And finally restarting the Impala service.
Impala Query Processing Interfaces
For processing the queries, Apache Impala provides the three interfaces, which are:
1. Impala-shell − After setting up Apache Impala by using the Cloudera VM, we can start this shell by using the command impala-shell in an editor.
2. Hue interface − We can also process the Impala queries by using the Hue browser. We have an Impala query editor In the Hue browser where we can type and execute Impala queries. For accessing the Impala editor in the Hue browser, we have to log in into the Hue browser.
3. ODBC/JDBC drivers − Apache Impala also provides the ODBC/JDBC drivers, just like the other databases. By using these drivers, we can easily connect to the Impala through the programming languages which support these drivers and build applications that process the queries in impala.
How is a query executed in Impala?
Whenever we pass any query to Impala by using any Impala query processing interfaces, an Impala Daemon (Impalad) in the cluster accepts the query. This Impalad, that is, Impala Daemon is then treated as the coordinator node for that specific query.
After receiving the query, a query coordinator will verify whether the query submitted by the user is appropriate. It does so by using Table Schema from the Hive meta store.
After verifying the query, it collects the information about the data location, which is required for executing the query. It collects the information from the HDFS NameNode and sends this information to the other Impala Daemons for executing the query.
All the other Impalad in the cluster reads the specified data block and executes the query. When all the Impala daemons complete their tasks, then the query coordinator will collect the result back and then deliver it to the user.
Features of Apache Impala
The key-features of Impala are−
- Apache Impala is a freely available service under the Apache license.
- It provides support for in-memory data processing; that is, it can access or analyze the data stored on the Hadoop DataNodes without any data movement.
- By using Impala we can access the data using SQL-like queries.
- Apache Impala provides faster access to the data stored in Hadoop Distributed File System as compared to the other SQL engines like Hive.
- With Impala we can store data in storage systems like Hadoop HDFS, HBase, and Amazon s3.
- We can integrate Impala easily with business intelligence tools such as Tableau, Micro strategy, Pentaho, and Zoom data.
- It provides support for various file formats like LZO, Avro, RCFile, Sequence File, and Parquet.
- Apache Impala uses the same metadata, ODBC driver, user interface, and SQL syntax as Apache Hive.
Impala Shell Commands
The Impala Shell Commands were classified into three categories:
- General Commands
- Query specific options
- Table and Database-specific options
Let us now explore each in detail.
1. General Commands
a. help : The Impala shell command help gives us the complete list of all the commands available in Apache Impala.
b. version : The Impala shell command version gives us the current version of the Impala.
c. history : The Impala shell command history displays the last 10 commands that are executed in the Impala shell
d. connect : The Impala shell command connect is used for connecting to the given instance of Impala. If we do not specify any instance, then by default, it will connect to the default port 21000.
e. exit | quit : We use the exit or quit command for coming out of the Impala shell.
2. Query specific options
a. profile: The Impala shell command profile displays the low-level information related to the recent query. We used this command for diagnosis and the performance tuning of the query.
b. explain: The Impala shell command explain returns the execution plan for a given query.
3. Table and Database specific options
a. alter: The Impala shell command alter modifies the structure and the name of the table in Impala.
b. describe: The Impala shell command describe gives the metadata information of a table. It contains information such as columns and their data types.
c. drop: The Impala shell command drop removes the construct from Impala. The construct can be a table, a database function, or a view.
d. insert: The Impala shell command insert appends the data (columns) into the table or for overriding the data of the existing table.
e. select: The Impala shell command select is used for performing the desired operation on the particular dataset. This command selects the dataset on which we have to perform some action.
f. show: The Impala shell command show displays the metastore of the constructs like tables, databases, etc.
g. use: The Impala shell command use changes the current context to the desired database.
Similarities between Apache Impala, Hive, and Hbase
The similarities between Apache Impala, Hive, and Hbase are:
- All are open-source, thus available free of cost.
- They all support server-side scripting.
- It follows the ACID properties like Durability and Concurrency.
- They all use sharding for partitioning.
Let us now explore the difference between Apache Impala, Hive, and Hbase.
Difference between Apache Impala, Hive, and Hbase
Though Apache Impala uses the same metastore, query language, user interface as Hive, but it differs from Hive and HBase in certain aspects. The below table enlists the differences among the Impala, Hive, and HBase.
| Impala | Hive | HBase |
| Apache Impala is a tool designed for managing and analyzing the data stored in Hadoop. | Apache Hive is a data warehouse tool that can be used for accessing and managing the large distributed datasets in Hadoop. | HBase is the wide-column store database that is based on Apache Hadoop. HBase uses the concepts of Google BigTable. |
| It follows the Relational model. | It also follows the Relational model. | HBase follows the wide column store model. |
| It’s Written in C++. | Written in Java. | Written in Java. |
| Impala has a Schema-based data model. | Hive also has a Schema-based data model. | HBase has a schema-free data model. |
| Apache Impala provides the JDBC and the ODBC API’s. | Apache Hive provides the JDBC, ODBC, and Thrift API’s. | HBase provides the Java, RESTful, and the Thrift API’s. |
| Apache Impala supports all the languages supporting JDBC and ODBC. | Apache Hive supports programming languages such as Java, C++, PHP, and Python. | HBase support the programming languages such as C, C++, C#, PHP, Python, Groovy, Java, and Scala. |
| Impala doesn’t support triggers. | Hive also doesn’t support triggers. | HBase provides support for triggers. |
| Released in 2013. | It released in 2012. | Released in 2008. |
| Current release was 3.3.0 | Its Current release was 3.1.2 | Current release was 2.2.0 |
Advantages of Apache Impala
The main advantages of Apache Impala are:
- With Impala we can access the data stored in HDFS, Amazon s3, and HBase without writing the long MapReduce jobs. We can access them just with the basic knowledge of SQL queries.
- By Using Apache Impala we can process huge amounts of data stored in HDFS at a lightning-fast speed by using the traditional SQL knowledge.
- Also, for writing queries in the business tools, the data goes through the complicated ETL (extract-transform-load ) cycle. However, with Apache Impala, we can shorten this procedure.
- When working with Impala the data transformation and data movement is not needed for the data stored in Hadoop because it carries out the data processing on the machines where the data resides.
- Impala is developing the use of Parquet file format which is a columnar storage layout that is optimized for the large-scale queries in the data warehouse scenarios.
- Impala provides support for multiple compression codecs such as Snappy, Gzip, Deflate.
Disadvantages of Impala
The significant limitations of Apache Impala are:
- It does not provide any support for the Serialization and Deserialization.
- Apache Impala can read the text files only. It cannot read custom binary files.
- In Impala whenever we add any new records or files to the data directory in Hadoop DFS then the table needs to be refreshed.
- Impala does not provide support for triggers.
- In Apache Impala, the LOAD DATA statement doesn’t work if the source directory and the destination table are in the different encryption zones.
Summary
In short, we can say that Impala is an open-source and the native analytic database for Hadoop. Impala is the best performing SQL engine that provides the fastest way for accessing the data stored in the HDFS (Hadoop Distributed File System).
Impala uses the same SQL syntax (Hive Query Language), metadata, user interface, and ODBC drivers as Apache Hive. Unlike the traditional storage systems, Apache impala is not coupled with its storage engine.
Apache Impala consists of three core components Impala daemon, Impala Statestore, and Impala Catalog services. Impala Shell, Hue browser, and JDBC/ODBC driver are the three query processing interfaces that we can use for interacting with Apache Impala.
The article had also described Impala’s various shell commands.