Introduction to HDFS Federation & Architecture
In this Hadoop tutorial, we are going to provide you a complete introduction of HDFS Federation. In this tutorial we will discuss HDFS Architecture, Limitations of the current architecture of HDFS.
Then after we will cover the HDFS Federation architecture in detail along with their advantages in Hadoop framework.
What is HDFS Federation?
Federation enhances an existing Hadoop HDFS architecture. Prior HDFS architecture allows single namespace for the entire cluster. In that architecture, single NameNode manages namespace.
If NameNode fails, then whole cluster will be out of service. And the cluster will be unavailable until the NameNode restarts or brought on a separate machine.
HDFS Federation was introduced to overcome this limitation. It overcomes this by adding support for many NameNode/Namespaces to HDFS.
Current HDFS Architecture
HDFS has two main layers given below:
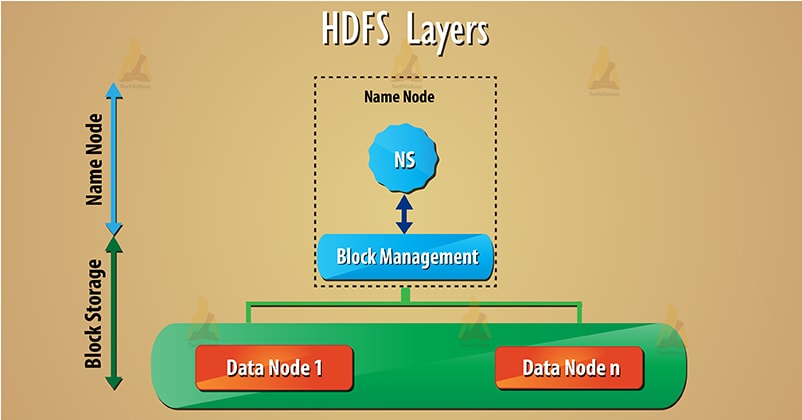
a) Namespace– This layer manages files, directories, and blocks. This layer supports basic file system operation such as creation, deletion of files.
b) Block Storage– It has two parts-
- Block management – It supports block related operation such as creation, deletion of the blocks. It manages data nodes in the cluster and takes care of replication management.
- Physical storage – This stores the blocks on the local file system and provides access to read or write operation. Follow this link to learn HDFS data read and write operation.
This current HDFS works fine for smaller setups. But, for large organizations where we need to take care of the huge amount of data has some limitation. Hadoop federation handles those limitations.
Limitation of current HDFS Architecture
Limitation of current HDFS Architecture is given below:
1. Tightly coupled block storage and Namespace
Namespace layer and storage layer are tightly coupled. It makes alternate implementation of namenode difficult. And it restricts other services to use block storage.
2. Namespace Scalability
The namespace is not scalable like datanode. Scaling in HDFS cluster is horizontally by adding datanodes. But we can’t add more namespace to an existing cluster. We can vertically scale namespace on a single namenode.
3. Performance
Hadoop entire performance depends on the throughput of the namenode. An operation of current file system depends on the throughput of a single namenode. NameNode at present supports 60,000 concurrent tasks.
Upcoming MapReduce will have support for more than 1,00,000 concurrent tasks. And this will need more namenode.
4. Isolation
There is no separation of the namespace. So there is no isolation among tenant organization that is using the cluster.
HDFS Federation Architecture
Federation uses many independent Namenode/namespaces to scale the name service horizontally. In HDFS Federation Architecture, at the bottom, datanodes are present. And datanodes are used as a common storage for blocks by all the namenodes.
Each datanodes registers with all the namenodes in the cluster. These datanodes send periodic heartbeats, block, report and handle command from the namenodes.

Many namenodes (NN1, NN2…, NNn) manages many namespaces (NS1, NS2…, NSn) respectively. Each namespace has its own block pool (NS1 Has pool 1and so on). Block from pool 1 is stored on datanode 1 and so on.
1. Block pool
Set of blocks is Block pool that belongs to a single namespace. There is a collection of pools in HDFS federation architecture. And each block is managed from the other.
This allows a namespace to create a Block ID for new blocks without coordination with another namespace. All Datanodes store data blocks present in all block pools.
2. Namespace volume
Namespace along with its block pool is Namespace volume. Many namespace volumes are there in HDFS federation. Hence, each namespace volume works independently. When we delete namenode or namespace, then corresponding block pool present on the datanodes will also be deleted.
Benefits of HDFS Federation
HDFS Federation overcomes the limitations of prior HDFS architecture. Hence it provides:
- Isolation – There is no isolation in single namenode in a multi-user environment. In HDFS federation different categories of application and users can be isolated to different namespaces by using many namenodes.
- Namespace Scalability – In federation many namenodes horizontally scales up in the filesystem namespace.
- Performance – We can improve Read/write operation throughput by adding more namenodes.
Conclusion
In conclusion to HDFS Federation, we can say that it overcomes the limitation of single node HDFS architecture. In prior HDFS architecture for an entire cluster allows only single namespace. While Federation uses many independent Namenode/namespaces to scale the name service horizontally.
It also separates the namespace layer and the storage layer. Hence provides Isolation, Scalability and simple design.
If you have any query or suggestion related to the Federation in Hadoop HDFS, so let us know by leaving a comment.