Apache Spark DAG: Directed Acyclic Graph
In this post, we will understand the concepts of apache spark DAG, refers to “Directed Acyclic Graph”. DAG is nothing but a graph which holds the track of operations applied on RDD.
Moving ahead we will learn about how spark builds a DAG, how apache spark DAG is needful. Also cover, how fault tolerance is possible through apache spark DAG. In closing, we will appreciate the advantages of DAG.
These advantages helped in overcome the drawbacks of Hadoop mapreduce.
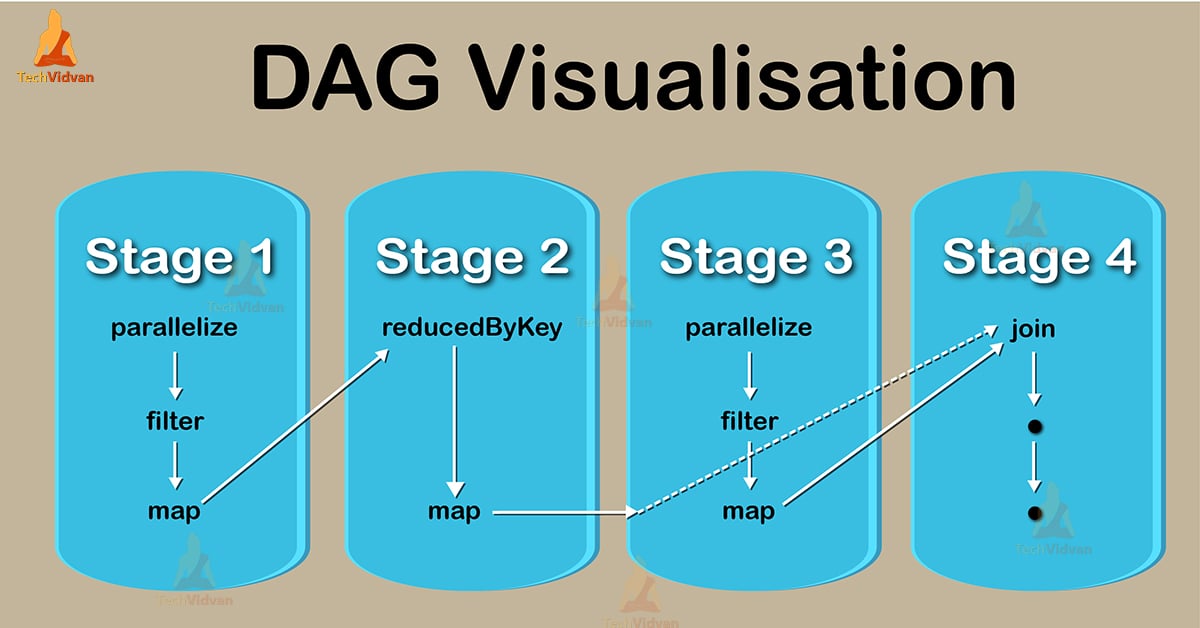
Concepts of Apache Spark DAG
In the beginning, let’s understand what is DAG in apache spark. On decomposing its name:
- Directed – Means which is directly connected from one node to another. This creates a sequence i.e. each node is in linkage from earlier to later in the appropriate sequence.
- Acyclic – Defines that there is no cycle or loop available. Once a transformation takes place it cannot returns to its earlier position.
- Graph – From graph theory, it is a combination of vertices and edges. Those pattern of connections together in a sequence is the graph.
Apache Spark DAG
Earlier in Hadoop, we use to break down the entire job into smaller ones and sequence them together. To go along with mapreduce, Spark recognizes all the jobs. Those are the jobs which may perform in parallel with partitions over the cluster. With all these jobs spark creates a logical flow of operations, which is known as DAG.
Directed Acyclic Graph is an arrangement of edges and vertices. In this graph, vertices indicate RDDs and edges refer to the operations applied on the RDD.
According to its name, it flows in one direction from earlier to later in the sequence. When we call an action, the created DAG is submitted to DAG Scheduler. That further divides the graph into the stages of the jobs.
Working of DAG Scheduler
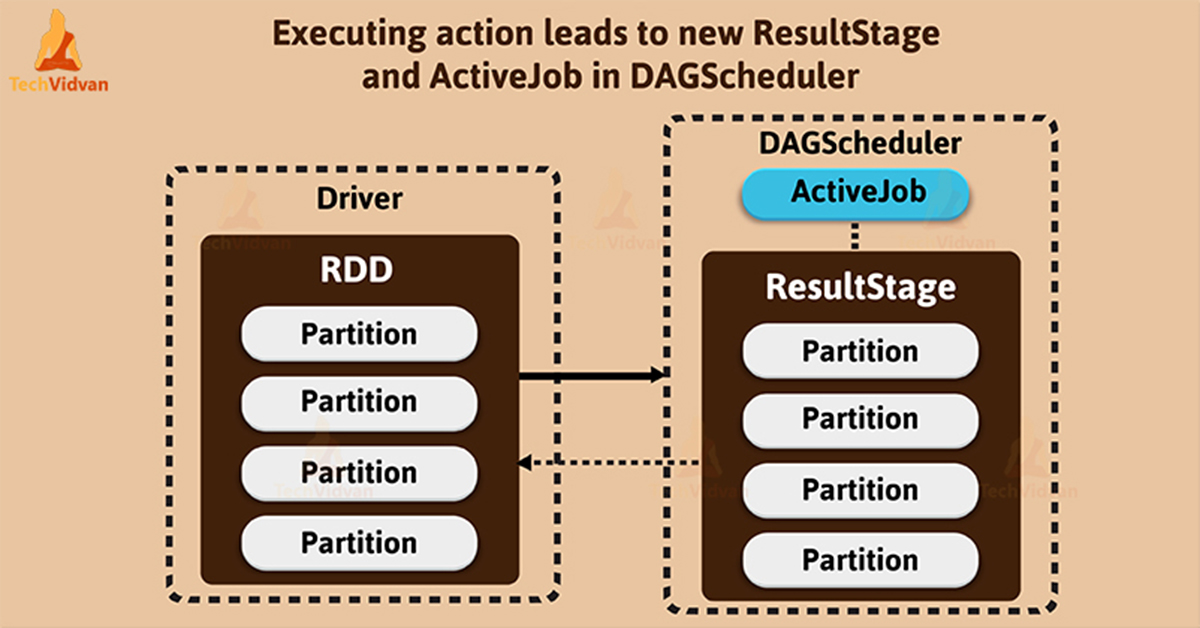
It is a scheduling layer in a spark which implements stage oriented scheduling. It converts logical execution plan to a physical execution plan. When an action is called, spark directly strikes to DAG scheduler. It executes the tasks those are submitted to the scheduler.
Spark uses pipelining (lineage) operations to optimize its work, that process combines the transformations into a single stage. The basic concept of DAG scheduler is to maintain jobs and stages. It tracks through internal registries and counters.
There are following steps through DAG scheduler works:
- It completes the computation and execution of stages for a job. It also keeps track of RDDs and run jobs in minimum time and assigns jobs to the task scheduler. Task scheduler means submitting tasks for execution.
- It determines the preferred locations on which, we can run each task respectively. It is possible with the task scheduler. That gets the information of current cache status.
- It handles the track of RDDs, which are cached to devoid re-computing. In this way it also handles failure. As it remembers at what stages it already produced output files it heals the loss. Due to shuffle output files may lose so it helps to recover failure.
Why is Spark DAG needful?
In hadoop mapreduce, computations take place in three steps:
1. Initially, we use HDFS (Hadoop Distributed File System) to read data every time we need.
2. After that, two transformation operations map and reduce are applied.
3. And in the third step computed result is written back to HDFS. Due to each operation is independent of each other there is no linkage in between. Sometimes it became an issue to handle two map-reduce jobs at same time. Due to this most memory gets wasted. That results in long computation with less data volume.
Therefore in spark, it automatically forms DAG logical flow of operations. That helps in minimize the data shuffling all around. This reduces the duration of computations with less data volume. It also increases the efficiency of the process with time.
How Spark Builds a DAG?
There are following steps of the process defining how spark creates a DAG:
1. Very first, the user submits an apache spark application to spark.
2. Than driver module takes the application from spark side.
3. The driver performs several tasks on the application. That helps to identify whether transformations and actions are present in the application.
4. All the operations are arranged further in a logical flow of operations, that arrangement is DAG.
5. Than DAG graph converted into the physical execution plan which contains stages.
6. As we discussed earlier driver identifies transformations. It also sets stage boundaries according to the nature of transformation. There are two types of transformation process applied on RDD: 1. Narrow transformations 2. Wide transformations. Let’s discuss each in brief :
- Narrow Transformations – Transformation process like map() and filter() comes under narrow transformation. In this process, it does not require to shuffle the data across partitions.
- Wide Transformations – Transformation process like ReduceByKey comes under wide transformation. In this process, it is required shuffling the data across partitions.
As wide Transformation requires data shuffling that shows it results in stage boundaries.
- After all, DAG scheduler makes a physical execution plan, which contains tasks. Later on, those tasks are joint to make bundles to send them over the cluster.
How is Fault Tolerance achieved through Spark DAG?
As we know DAG keeps the record of operations applied on RDD. It holds every detail of tasks executed on different partitions of spark RDD. So at the time of failure or if losing any RDD, we can fetch it easily with the help of DAG graph.
For example, If any operation is going on and all of sudden any RDD crashes. With the help of cluster manager, we will identify the partition in which loss occurs. After that through DAG, we will assign the RDD at the same time to recover the data loss.
That new node will operate on the particular partition of spark RDD. It will also execute in the series of operation, where it needed to be executed.
Working with DAG optimizer in Spark
Optimizing a DAG is possible by rearranging and combining operators wherever possible. The DAG optimizer rearranges the order of operators to maintain the number of records of further operations.
For example, if we take two operations like map () and filter () in a spark job. The optimizer will rearrange the order of both the operators. Since filtering may reduce the number of records to experience map operations.
Advantages of DAG in Spark
DAG has turned as very beneficial in several terms to us. Some of them are list-up below:
- It is possible to execute many at same time queries through DAG. Due to only two queries (Map and Reduce) are available in mapreduce. We are not able to entertain SQL query, which is also possible on DAG. It turns out more flexible than mapreduce.
- As it is possible to achieve fault tolerance through DAG. We can recover lost RDDs using this graph.
- In comparison to hadoop mapreduce, DAG provides better global optimization.
Conclusion
Coming to the end, we found that DAG in spark overcomes the limitations of hadoop mapreduce. It enhances sparks functioning in any way. DAG is a beneficial programming style used in distributed systems.
Through DAG there are several level functions are available to work on. As in MapReduce, there are only two functions (map and reduce) available.
Comparatively, DAG is faster than mapreduce. That improves the efficiency of the system.