Apache Spark Stage- Physical Unit Of Execution
In Apache Spark, a stage is a physical unit of execution. We can say, it is a step in a physical execution plan. In this document, we will learn the whole concept of spark stage, types of spark stage. Basically, there are two types of stages in spark- ShuffleMapstage and ResultStage.
Furthermore, We will also learn to create spark stage in detail.
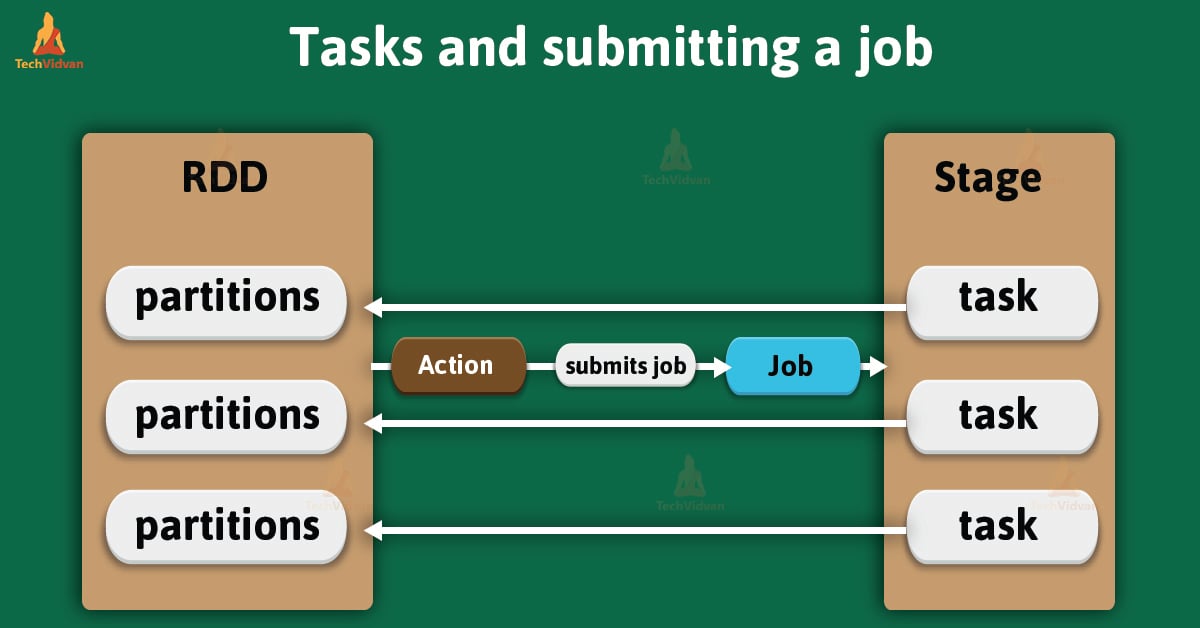
Spark Stage- Tasks and Submitting A Job
Stage in Spark
In Apache Spark, a stage is a physical unit of execution. We can say, it is a step in a physical execution plan. It is a set of parallel tasks — one task per partition. In other words, each job gets divided into smaller sets of tasks, is what you call stages.
Generally, it depends on each other and it is very similar to the map and reduce stages in MapReduce. Basically, a spark job is a computation with that computation sliced into stages.
We can uniquely identify a stage with the help of its id. Whenever it creates a stage, DAGScheduler increments internal counter nextstageId. It helps to track the number of stage submissions.
We can associate stage with many other dependent parent stages. Since stage can only work on the partitions of a single RDD. Even with the boundary of a stage marked by shuffle dependencies.
Afterwards, stage submission triggers execution of a series of dependent parent stages. Ultimately, there is a first JobId present of every stage that is the id of the job which submits stage.
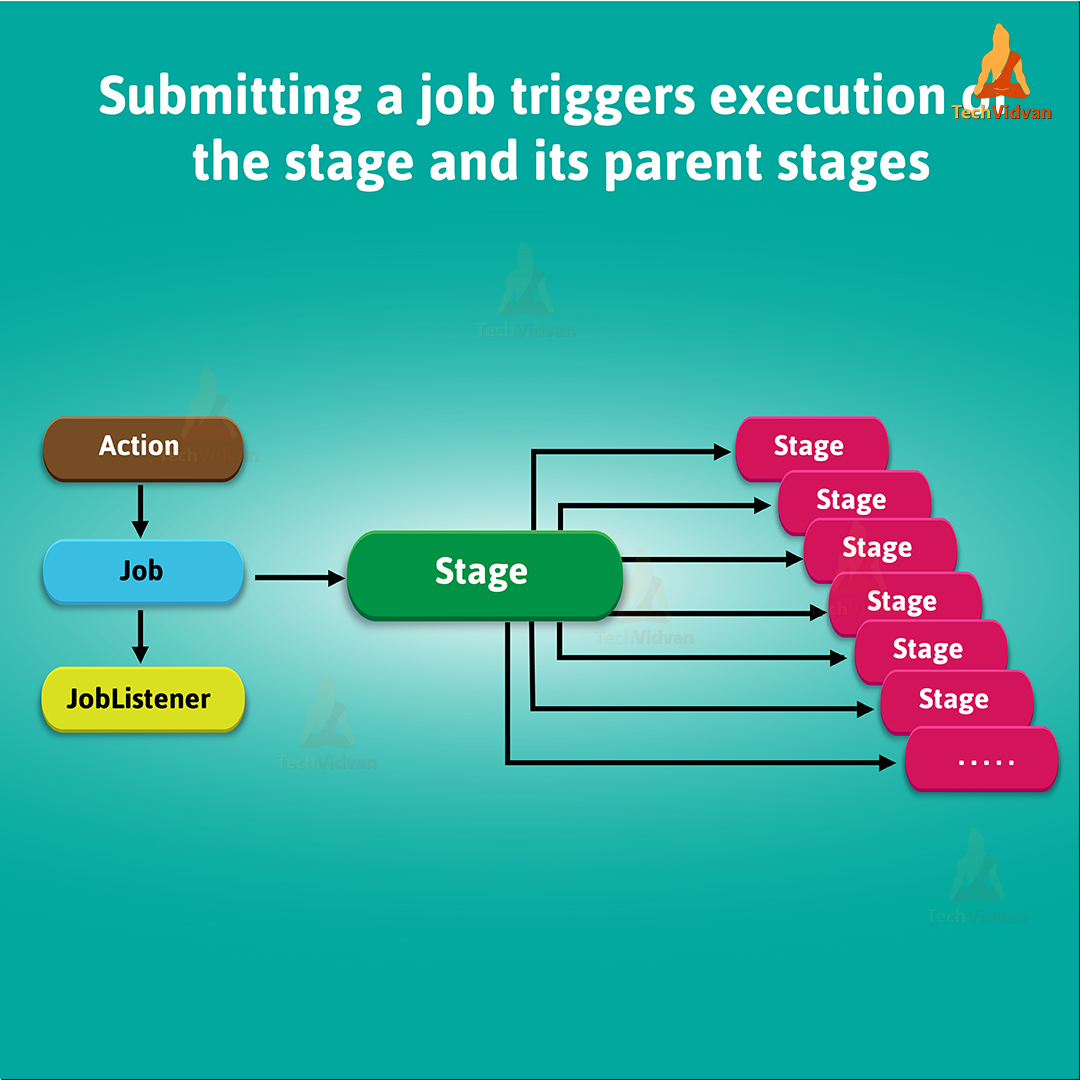
Spark Stage – Submitting a Job Trigger Execution of the stage
Types of Spark Stage
In spark, stages are of two types:
3.1. ShuffleMapStage
3.2. ResultStage
Let’s discuss each type of stages in detail:
1. ShuffleMapStage
In the physical execution of DAG, we consider ShuffleMapStage as an intermediate stage. It produces data for another stage(s). Also, writes map output files for a shuffle.
We can also consider it as the final stage in a job in adaptive query planning / adaptive scheduling. As a spark job for adaptive query planning, we can also submit it independently.
A ShuffleMapStage saves map output files when executed. Those files can later be fetched by reduce tasks. The ShuffleMapStage is considered ready when all map outputs are available. Sometimes, output locations can be missing, it means partitions might not be calculated or are lost.
We can track how many shuffle map outputs are available, for that these stages use outputLocs &_numAvailableOutputs internal registries. In the DAG of stages, ShuffleMapStage is an input for the other following stages. Those are what we call a shuffle dependency’s map side.
There can be multiple pipeline operations, in ShuffleMapStage, for example, map and filter, before shuffle operation. It is also possible to share single ShuffleMapStage across different jobs.

Spark Stage- DAGScheduler and Job Stages
2. ResultStage
A stage that executes a spark action in a user program by running a function on an RDD is a ResultStage. Generally, we consider it as a final stage. In other words, it is a final stage in a job which applies a function on one or many partitions of the target RDD. It also helps for computation of the result of an action.
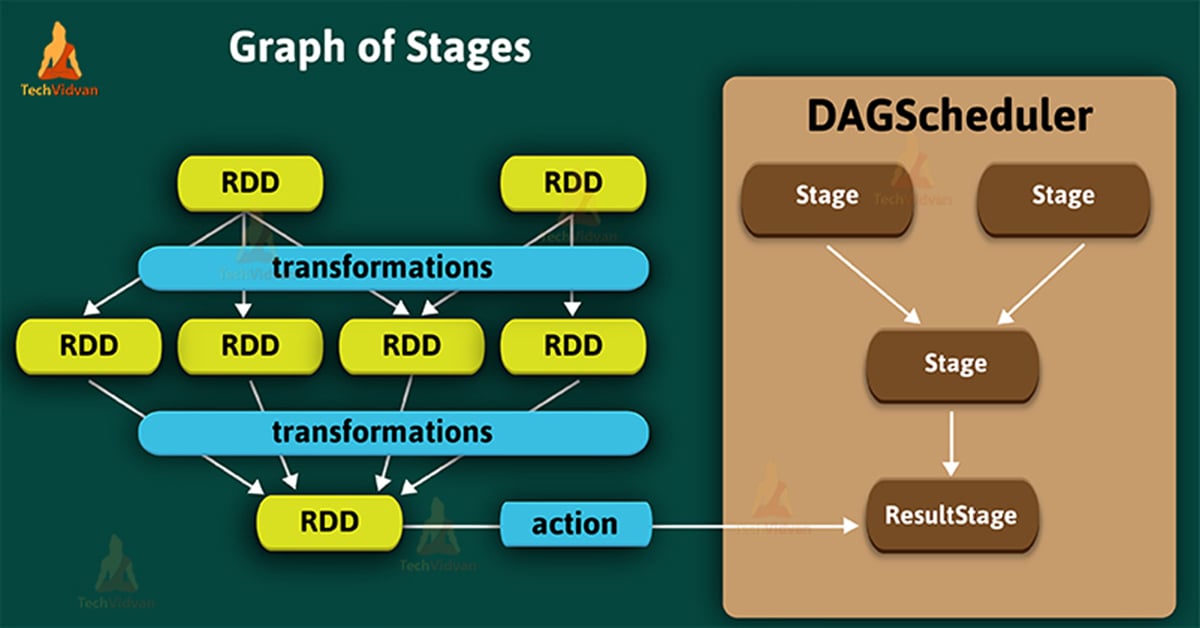
Spark Stage – Graph of Stages
Getting StageInfo For Most Recent Attempt
We can also get to know the most recent StageInfo by using the latestInfo method.
latestInfo: StageInfo
Stage Contract
Basically, stage is a private[scheduler] abstract contract.
abstract class Stage {
def findMissingPartitions(): Seq[Int]
}
Method to Create New Spark Stage
We can create the new stage with the help of the following method:
makeNewStageAttempt( numPartitionsToCompute: Int, taskLocalityPreferences: Seq[Seq[TaskLocation]] = Seq.empty): Unit
It creates a new TaskMetrics. Also, registers the internal accumulators by using the RDD’s SparkContext. It uses the same RDD that was defined when stage was created.
With nextAttemptId, numPartitionsToCompute, & taskLocalityPreferences, it sets latestInfo to be a StageInfo, from stage. It also increments nextAttemptId counter.
Note: We use this method only when DAGScheduler submits missing tasks for a stage.
Conclusion
In this blog, we have studied the whole concept of stages in spark. Hope, this document helped to calm the curiosity about stage in Apache Spark.