Apache Spark Terminologies and Key Concepts
This article cover core Apache Spark concepts, including Apache Spark Terminologies.
Ultimately, it is an introduction to all the terms used in Apache Spark with focus and clarity in mind like Action, Stage, task, RDD, Dataframe, Datasets, Spark session etc.
Apache Spark is so popular tool in big data, it provides a powerful and unified engine to data researchers. This blog is helpful to the beginner’s abstract of important Apache Spark terminologies.

List of essential key terms: Apache Spark Terminologies
1. Apache Spark
Apache Spark is an open-source processing engine alternative to Hadoop. In terms of memory, it runs 100 times faster than Hadoop MapReduce. However, On disk, it runs 10 times faster than Hadoop.
It handles large-scale data analytics with ease of use. Also, Spark supports in-memory computation.
We can run spark on following APIs like Java, Scala, Python, R, and SQL. As well, Spark runs on a Hadoop YARN, Apache Mesos, and standalone cluster managers.
2. Working with Apache Engine
Spark engine is the fast and general engine of Big Data Processing. This engine is responsible for scheduling of jobs on the cluster. It also handles distributing and monitoring data applications over the cluster.
3. RDD (Resilient Distributed Datasets)
RDD is Spark’s core abstraction as a distributed collection of objects. It is an Immutable dataset which cannot change with time. This data can be stored in memory or disk across the cluster.
The data is logically partitioned over the cluster. It offers in-parallel operation across the cluster. As RDDs cannot be changed it can be transformed using several operations. Those are Transformation and Action operations.
Furthermore, RDDs are fault Tolerant in nature. If any failure occurs it can rebuild lost data automatically through lineage graph.
4. Partitions
To speed up the data processing, term partitioning of data comes in. Basically, Partition means logical and smaller unit of data. Partitioning of data defines as to derive logical units of data.
5. Cluster Manager
Cluster manager runs as an external service which provides resources to each application. This is possible to run Spark on the distributed node on Cluster. Spark supports following cluster managers.
First is Apache Spark Standalone cluster manager, the Second one is Apache Mesos while third is Hadoop Yarn.
Hence, all cluster managers are different on comparing by scheduling, security, and monitoring. As a matter of fact, each has its own benefits. No doubt, We can select any cluster manager as per our need and goal.
6. Worker Node
A worker node refers to a slave node. Actually, any node which can run the application across the cluster is a worker node. In other words, any node runs the program in the cluster is defined as worker node.
7. Application
It is a User program built on Apache Spark. Moreover, it consists of a driver program as well as executors over the cluster.
8. Executor
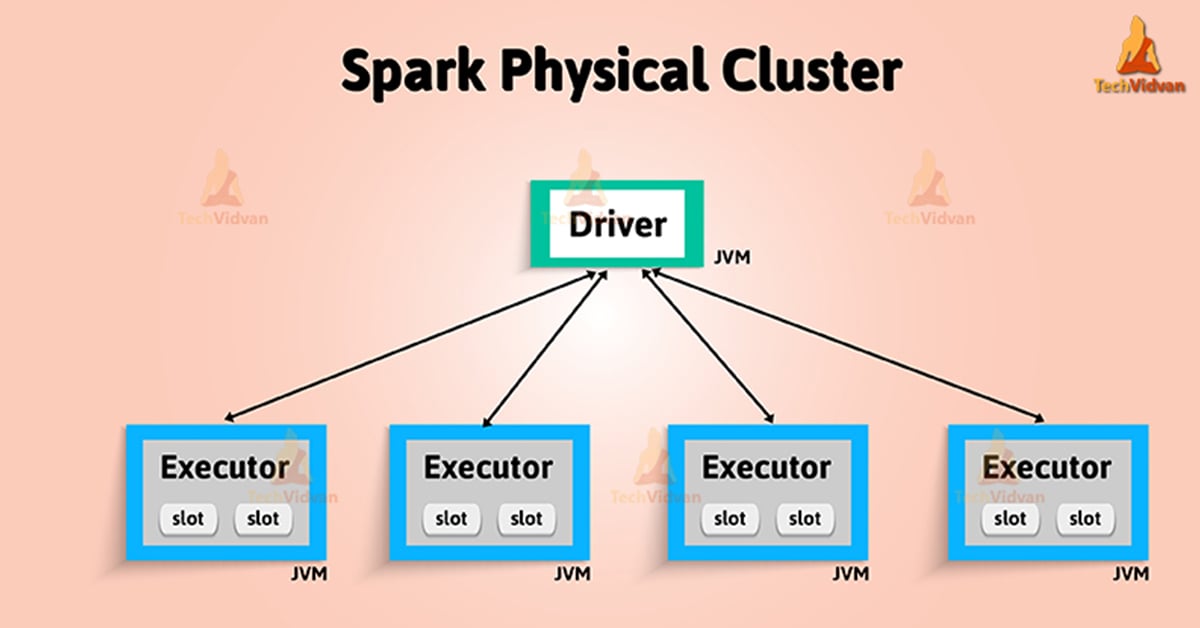
Any application can have its own executors. These are generally present at worker nodes which implements the task.
In other words, as any process activates for an application on a worker node. That executes tasks and keeps data in-memory or disk storage over them.
9. Task
A Task is a unit of work that is sent to any executor.
10. Stage
Each job is divided into small sets of tasks which are known as stages.
11. Driver Program
The driver program is the process running the main() function of the application. It also creates the SparkContext. This program runs on a master node of the machine. In the meantime, it also declares transformations and actions on data RDDs.
12. Action
Actions refer to an operation. It includes reducing, counts, first and many more. However, it also applies to RDD that perform computations. Also, send the result back to driver program.
13. Lazy Evaluation
It optimizes the overall data processing workflow. Lazy evaluation means execution is not possible until we trigger an action. ultimately, all the transformations take place are lazy in spark.
14. Data Frame
It is an immutable distributed data collection, like RDD. We can organize data into names, columns, tables etc. in the database. This design makes large datasets processing even easier.
It allows developers to impose distributed collection into a structure and high-level abstraction.
15. Datasets
To express transformation on domain objects, Datasets provides an API to users. It also enhances the performance and advantages of robust Spark SQL execution engine.
16. MLlib
In Apache Spark a general machine learning library — MLlib — is available. Moreover, It provides simplicity, scalability, as well as easy integration with other tools.
It is designed to work with scalability, language compatibility, and speed of Spark.
17. Spark SQL
It is a spark module which works with structured data. Also, supports workloads, even combine SQL queries with the complicated algorithm based analytics.
18. Spark Context
Spark context holds a connection with Spark cluster manager. While Co-ordinated by it, applications run as an independent set of processes in a program.
19. ML pipelines
We can say when machine learning algorithms are running, it involves a sequence of tasks. Above all, It includes pre-processing, feature extraction, model fitting, and validation stages.
20. GraphX
It is the component in Apache Spark for graphs and graph-parallel computation. Moreover, GraphX extends the Spark RDD by Graph abstraction.
Abstraction is a directed multigraph with properties attached to each vertex and edge. In addition, to brace graph computation, it introduces a set of fundamental operators.
21. Spark Streaming
It is an extension of core spark which allows real-time data processing. Key abstraction of spark streaming is Discretized Stream, also DStream. Moreover, it indicates a stream of data separated into small batches.
Conclusion
Therefore, This tutorial sums up some of the important Apache Spark Terminologies. It shows how these terms play a vital role in Apache Spark computations. Also, helps us to understand Spark in more depth.
Hence, this blog includes all the Terminologies of Apache Spark to learn concept efficiently.