Spark Architecture & Internal Working
The spark architecture has a well-defined and layered architecture. In this architecture of spark, all the components and layers are loosely coupled and its components were integrated.
In this tutorial, we will discuss, abstractions on which architecture is based, terminologies used in it, components of the spark architecture, and how spark uses all these components while working.
Internal working of spark is considered as a complement to big data software. One of the reasons, why spark has become so popular is because it is a fast, in-memory data processing engine. As it is much faster with ease of use so, it is catching everyone’s attention across the wide range of industries.
This write-up gives an overview of the internal working of spark.
Spark Architecture & Internal Working – Few Insights on Internal Working of Spark
Spark is an open source distributed computing engine. We use it for processing and analyzing a large amount of data. Likewise, hadoop mapreduce, it also works to distribute data across the cluster. It helps to process data in parallel.
Spark uses master/slave architecture, one master node, and many slave worker nodes. Here, Driver is the central coordinator.
In spark, driver program runs in its own Java process. These drivers handle a large number of distributed workers. These distributed workers are actually executors. Each executor works as a separate java process. Spark application is a collaboration of driver and its executors.
We can launch a spark application on the set of machines by using a cluster manager. Spark has its own built-in a cluster manager i.e. standalone cluster manager. Although,in spark, we can work with some open source cluster manager.
Apart from its built-in cluster manager, such as hadoop yarn, apache mesos etc. In this blog, we will also learn complete Internal Working of Spark.
Spark Architecture & Internal Working – Important Terminologies of Apache Spark
We will study following key terms one come across while working with Apache Spark. They are:
1. Spark Context
SparkContext is the main entry point to spark core. It allows us to access further functionalities of spark. This helps to establish a connection to spark execution environment. It provides access to spark cluster even with a resource manager. Sparkcontext act as master of spark application.
It offers various functions. Such as:
- Getting the current status of spark application
- Canceling the job
- Canceling the Stage
- Running job synchronously
- Running job asynchronously
- Accessing persistent RDD
- Un-persisting RDD
- Programmable dynamic allocation
2. Spark Shell
Apache spark provides interactive spark shell which allows us to run applications on. It helps in processing a large amount of data because it can read many types of data. Run/test of our application code interactively is possible by using spark shell.
3. Spark Application
Even when there is no job running, spark application can have processes running on its behalf. It is a self-contained computation that runs user-supplied code to compute a result.
4. Task
It is a unit of work, which we sent to the executor. Every stage has some task, one task per partition.
5. Job
It parallels computation consisting of multiple tasks.
6. Stages
Each job is divided into small sets of tasks which are known as stages.
Spark Architecture & Internal Working – Components of Spark Architecture
1. Role of Apache Spark Driver
It is a master node of a spark application. Spark driver is the central point and entry point of spark shell. This program runs the main function of an application. we can create SparkContext in Spark Driver.
It contains following components such as DAG Scheduler, task scheduler, backend scheduler and block manager. The driver translates user code into a specified job. Afterwards, which we execute over the cluster.
– It schedules the job execution and negotiates with the cluster manager.
– This driver program translates the RDDs into execution graph. It also splits the graph into multiple stages.
– It stores the metadata about all RDDs as well as their partitions.
– This driver program creates tasks by converting applications into small execution units. After that executor executes the task, the worker processes which run individual tasks.
2. Role of Apache Spark Executor
To execute several tasks, executors play a very important role. They are distributed agents those are responsible for the execution of tasks. Each application has its own executor process.
Executors actually run for the whole life of a spark application. That is “Static Allocation of Executors” process.
Users can also select for dynamic allocations of executors. We can also add or remove spark executors dynamically according to overall workload.
– It performs all the data processing.
– Executors Write data to external sources. They also read data from external sources.
– We can store computation results in-memory. It is also possible to store data in cache as well as on hard disks.
– Executors do interact with the storage systems.
3. Role of Apache Spark Cluster Managers
Cluster managers are responsible for acquiring resources on the spark cluster. Then it provides all to a spark job. It works as an external service for spark. We have 3 types of cluster managers. Which may responsible for allocation and deallocation of various physical resources.
Likewise memory for client spark jobs, CPU memory. For a spark application to run we can launch any of the cluster managers. Such as Hadoop YARN, Apache Mesos or the simple standalone spark cluster manager.
We can select any cluster manager on the basis of goals of the application. Due to, the different set of scheduling capabilities provided by all cluster managers.
Standalone cluster manager is the easiest one to get started with apache spark. When we develop a new spark application we can use standalone cluster manager.
How to launch a program in Spark
There is the facility in spark comes from using a single script to submit a program. That facility is called as spark submit. It helps to launch an application over the cluster.
Spark submit can establish a connection to different cluster manager in several ways. It can also handle that how many resources our application gets.
There are some cluster managers in which spark-submit run the driver within the cluster(e.g. YARN ). While in others, it only runs on your local machine.
Spark Architecture & Internal Working – Architecture of Spark
It has a well-defined and layered architecture. In this architecture, all the components and layers are loosely coupled. These components are integrated with several extensions as well as libraries.
There are mainly two abstractions on which spark architecture is based. They are:
- Resilient Distributed Datasets (RDD)
- Directed Acyclic Graph (DAG)
1. Resilient Distributed Datasets (RDD)
These are the collection of object which is logically partitioned. It supports in-memory computation over spark cluster. Spark RDDs are immutable in nature. While we talk about datasets, it supports Hadoop datasets and parallelized collections.
Hadoop Datasets are created from the files stored on HDFS. Parallelized collections are based on existing scala collections. As RDDs are immutable, it offers two operations transformations and actions.
2. Directed Acyclic Graph (DAG)
On decomposing its name:
- Directed- Graph which is directly connected from one node to another. This creates a sequence.
- Acyclic – It defines that there is no cycle or loop available.
- Graph – It is a combination of vertices and edges, with all the connections in a sequence
We can call it a sequence of computations, performed on data. In this graph, edge refers to transformation on top of data. while vertices refer to an RDD partition.
This helps to eliminate the Hadoop mapreduce multistage execution model. It also provides efficient performance over Hadoop.
Spark Architecture & Internal Working – Run-Time Architecture of a Spark Application
What Happens When a client submits a Spark Job??
The diagram below shows the internal working spark:
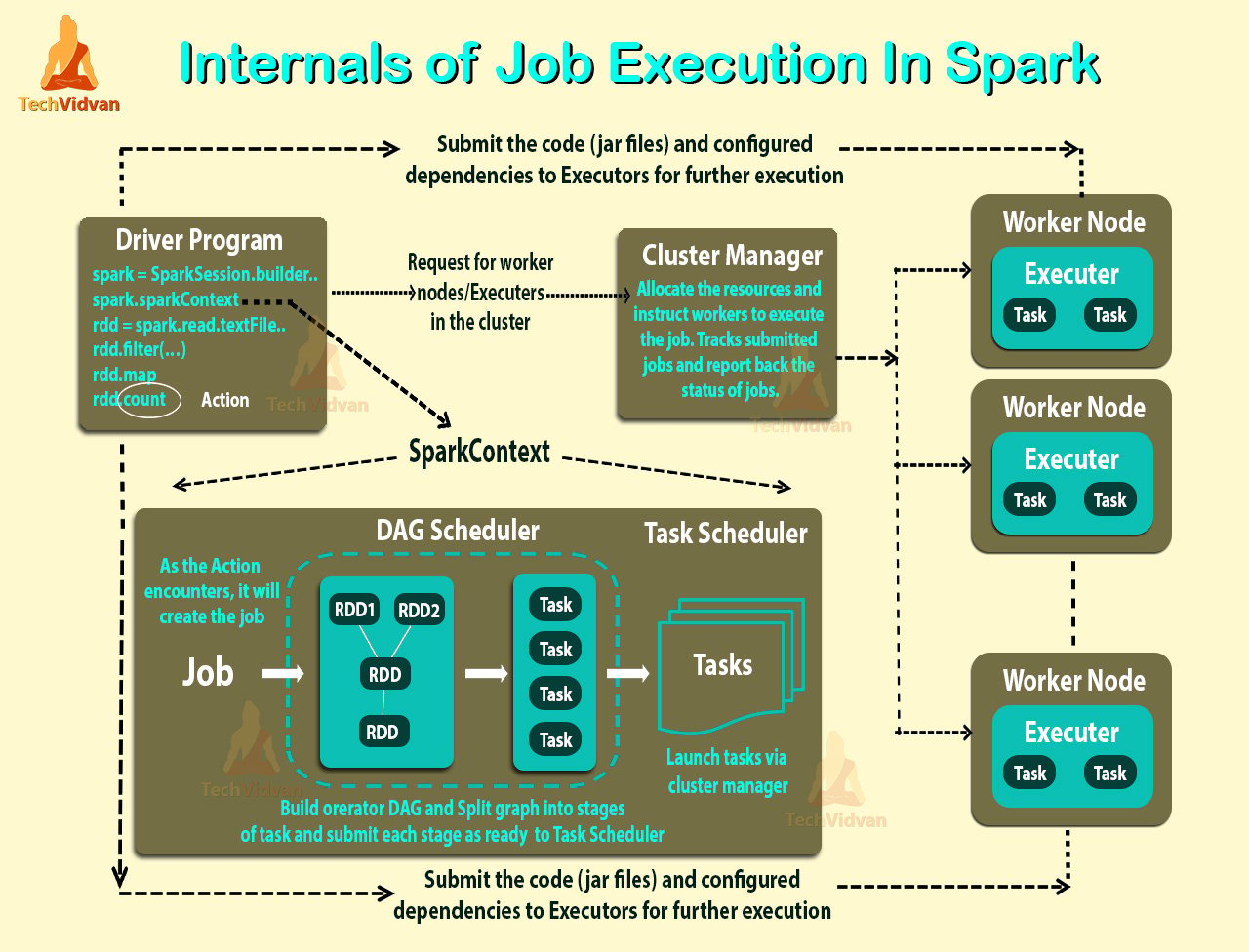
When the job enters the driver converts the code into a logical directed acyclic graph (DAG). Afterwards, the driver performs certain optimizations like pipelining transformations.
Furthermore, it converts the DAG into physical execution plan with the set of stages. Meanwhile, it creates small execution units under each stage referred to as tasks. Then it collects all tasks and sends it to the cluster.
It is the driver program that talks to the cluster manager and negotiates for resources. After this cluster manager launches executors on behalf of the driver. At this point based on data, placement driver sends tasks to the cluster manager.
Executors register themselves with the driver program before executors begin execution. So that the driver has the holistic view of all the executors.
Now, Executors executes all the tasks assigned by the driver. Meanwhile, the application is running, the driver program monitors the executors that run. In the spark architecture driver program schedules future tasks.
All the tasks by tracking the location of cached data based on data placement. When it calls the stop method of sparkcontext, it terminates all executors. After that, it releases the resources from the cluster manager.
Conclusion
Hence, By understanding both architectures of spark and internal working of spark, it signifies how easy it is to use. This turns to be very beneficial for big data technology. Ultimately, we have seen how the internal working of spark is beneficial for us.
It turns out to be more accessible, powerful and capable tool for handling big data challenges. Also, takes mapreduce to whole other level with fewer shuffles in data processing.
With the several times faster performance than other big data technologies. Also, holds capabilities like in-memory data storage and near real-time processing. Thus, it enhances efficiency 100 X of the system.