Spark DStream: Abstraction of Spark Streaming
Spark DStream (Discretized Stream) is the basic abstraction of Spark Streaming. In this blog, we will learn the concept of DStream in Spark, we will learn what is DStream, operations of DStream such as stateless and stateful transformations and output operation.
Introduction of Apache Spark DStream
What is Discretized Stream (DStream)
Introduction of Spark Streaming
The core Spark API’s extension is what we call a “Spark Streaming”. It enables high-throughput, scalability, fault-tolerant stream processing of live data streams. Ingestion of data is possible from many sources like Kafka, Flume, Kinesis, or TCP sockets.
We can also process it by using complex algorithms expressed with high-level functions, such as map, reduce, join and window. Afterwards, data which is already processed can be pushed out to filesystems. In addition, we can apply spark’s machine learning and graph processing on data streams.
DStream
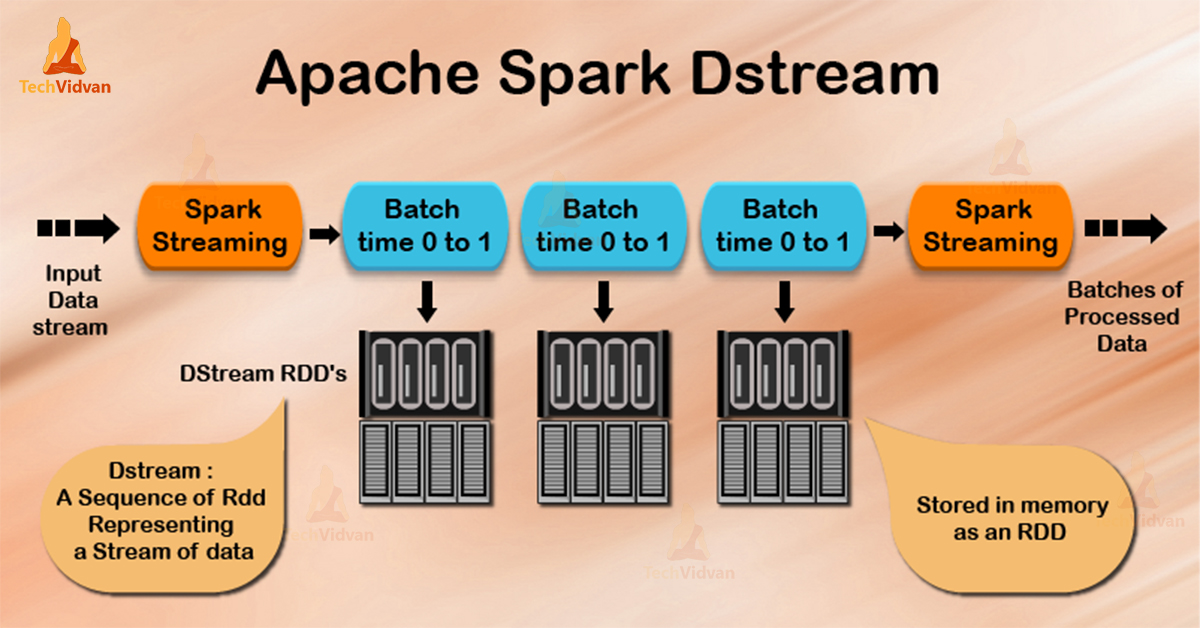
The basic abstraction of Spark Streaming is Spark DStream (Discretized Stream). It is a continuous sequence of spark RDDs, that represents a continuous stream of data, that is Spark’s abstraction of an immutable, distributed dataset.
Creation of DStreams can be possible from live data, such as data from HDFS, Kafka or Flume. Also, generation of Dstream is possible by transformation existing DStreams using operations, such as map, window, and reduceByKey and window.
Each DStream periodically generates a Spark RDD, while a spark streaming program is running, that RDD is either generated by live data or by transforming the RDD generated by a parent DStream.
There are few basic properties of DStreams:
- Record of other DStreams that the DStream depends on.
- Time duration at which DStream generates an RDD.
- The function which we use to generate an RDD after each time interval.
Operation applied on Spark DStream translates to operations on underlying RDDs. Spark engine computes these underlying RDD transformations, that offers developer a high-level API for convenience. Hence, DStream simplifies working with streaming data.
Input DStreams and Receivers
The stream of input data received from streaming sources is represented as DStream, which are input DStream. With every input DStream object, a receiver (Scala doc, Java doc) object is associated, that receives the data from a source. Also, stores it in spark’s memory for processing.
Following are the two types of built-in streaming sources.
- Basic sources: Those are directly available in the StreamingContext API are basic sources, such as file systems, and socket connections.
- Advanced sources: Advanced sources, those are available through extra utility classes, for example, Kafka, Flume, Kinesis and much more. These sources require linking against extra dependencies.
We can receive many streams of data in parallel by creating multiple input DStream. This process will create many receivers, so we will receive many data streams at the same time. Although, a spark executor/worker is a long-running task.
Hence, it occupies one of the cores allocated to the spark streaming application. Importantly, we need to allocate enough cores to the streaming application, that helps to process the received data also to run the receiver.
1. Basic Sources
Some of these basic sources are as follows-
a. File Streams:
We can create DStreams in:
- Scala
- Java
- Python
For Scala:
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)
For Java:
streamingContext.fileStream<KeyClass, ValueClass, InputFormatClass>(dataDirectory);
For Python:
streamingContext.textFileStream(dataDirectory)
The directory datadirectory will be monitor by spark streaming. Streaming also process any files created in that directory.
There are few conditions:
- There should be same data format for all the files.
- A file must create automatically in datadirectory, either by moving or renaming them into data directory.
- If files moved once, the files must not be changed. Because if files are being continuously appended, the new data will not be read.
b. Streams based on Custom Receivers:
We can create DStreams with data streams received by custom receivers.
c. The queue of RDDs as a Stream:
One can also create a DStream based on a queue of RDDs to test a spark streaming application with test data. We can create it by using the following method:
streamingContext.queueStream(queueOfRDDs)
2. Advance Sources
There are so many advance sources, some of them are:
- Kafka: Kafka broker versions 0.8.2.1 is compatible with spark streaming 2.2.0.
- Flume: Flume 1.6.0 is compatible with spark streaming 2.2.0.
- Kinesis: Kinesis client library 1.2.1 is compatible with spark streaming 2.2.0.
Apache Spark DStream Operations
Spark DStream supports two types of operations:
1. Transformations
2. Output operations
1. Transformation
Transformation in spark DStream are two categories:
- Stateless Transformations
- Stateful Transformations
a. Stateless Transformations
In stateless transformations, we don’t need data of previous batches for processing. As a result, these are simple RDD transformations. We apply it to each batch means every RDD in a DStream. Some common RDD transformations for example map(), filter(), reduceByKey() etc.
Although, each transformation applies to each spark RDD. So, it seems like applying it to the whole stream as each DStream is a collection of many RDDs (batches) in spark. We can combine data from many DStreams within each time step in this transformation.
DStreams comes with an advanced operator called transform(). We use transform(), if in case stateless transformations are insufficient. The transform() allow operating on the RDDs inside them.
It also allows any arbitrary RDD-to-RDD function to act on the DStream. To produce a new stream, this function gets called on each batch of data in the stream to produce a new stream.
b. Stateful Transformations

Stateful Transformation In Spark DStream
For computation of current batch results, it uses intermediate results from previous batches. These operations on DStreams track data across time. Therefore, it makes use of some data from previous batches to generate the results for a new batch.
Importantly, two main operations such as windowed operation and updateStateByKey(). The windowed operation is which act over a sliding window of time periods. While updateStateByKey() is which used to track state across events for each key.
2. Output Operation
After transformation on data, output operation is performed on that data in streaming. Now, as debugging of our program is done. Afterwards, by using output operation we can save our output. Output operations like print(), save() and much more.
Therefore, by save operation, we take directory to save file into and an optional suffix. Also, by print() operation we take in the first 10 elements from each batch of DStream and prints result.
Conclusion
By study above information on Spark DStream, RDD is Spark’s core abstraction and DStream is streaming’s high-level abstraction. It is a continuous sequence of RDDs, that represents a continuous stream of data.
Hence, we can obtain DStream from input DStream like Kafka, Flume & much more. Also, we can apply the transformation on the existing DStream to get a new DStream.