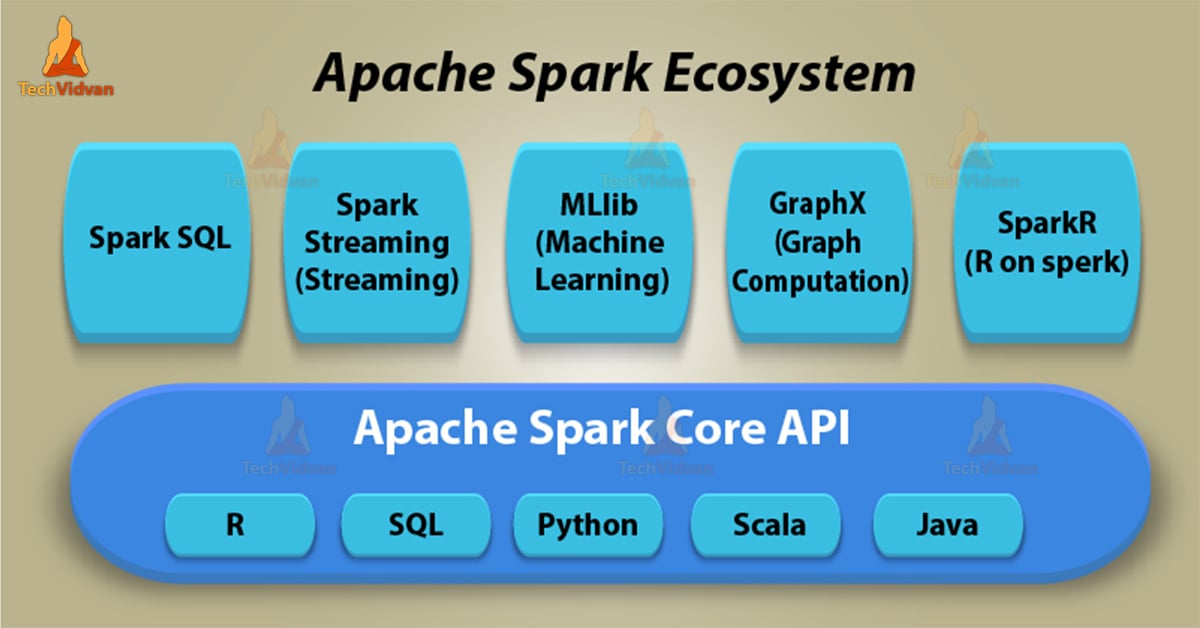
Apache Spark Ecosystem Components
In this Spark Ecosystem tutorial, we will discuss about core ecosystem components of Apache Spark like Spark SQL, Spark Streaming, Spark Machine learning (MLlib), Spark GraphX, and Spark R.
Apache Spark Ecosystem has extensible APIs in different languages like Scala, Python, Java, and R built on top of the core Spark execution engine.
Apache Spark is the most popular big data tool, also considered as next generation tool, which is being used by 100s of organization and having 1000s of contributors, it’s still emerging and gaining popularity as the standard big data execution engine.
Spark is a powerful open-source processing engine alternative to Hadoop. At first, It based on high speed, ease of use and increased developer productivity.
Also, supports machine learning, real-time stream processing, and graph computations as well.
Moreover, Spark provides in-memory computing capabilities. Also, supports a vast collection of applications. For ease of development, it also supports API’s like Java, Python, R, and Scala.
Let’s discuss uses of these languages in detail:
1. Scala
Though spark is built on Scala programming. Accordingly, it provides access to some of the great features in spark. Those features might not be available in other languages that support spark.
2. Python
This language provides excellent libraries for the purpose of data analysis. In comparison, we can say python is a bit slower than Scala language.
3. R Language
This language provides the rich platform for machine learning and statistical analysis. Also, enhances developer productivity. To handle processing in a single machine we can use R language along with Spark through Spark R.
4. Java
Java is definitely a good choice for developers coming from a Java + Hadoop background.
Spark Ecosystem – Spark Components
There are several components of Spark ecosystem, some of them are getting developed. Few respective contributions are being made every now and then. Initially, Spark ecosystem empowers following 6 components which are mentioned below:
1. Apache Spark core
Spark core is the kernel of Apache Spark and is the foundation of parallel and distributed processing. Spark core is accountable for all the fundamental I/O functionalities.
Also, includes monitoring of jobs over cluster, scheduling jobs on the cluster. Self-recovery of fault, task dispatching, networking and efficient memory management also included.
Due to In-memory computation capability, it provides high speed. In Spark core, we use a special data structure RDD. RDD refers to Resilient Distributed Datasets. While we need to share or reuse data in computing systems like Hadoop MapReduce.
That requires data to be stored in intermediate stores. Thus, that slowdowns the speed of computation. Hence, RDD overcomes this limitation by introducing fault tolerant “In-Memory” computation.
These RDDs are immutable, a partitioned collection that can be operated on in parallel. As RDDs are immutable we can not make any changes in them but we can transform one RDD into another.
This can be possible by Transformation operation. Transformation operation means we can produce new RDD from existing ones.
Key features of Apache Spark Core
- As we discussed earlier it is accountable for all basic I/O Functionalities.
- It monitors the role of the cluster. This also observes the jobs of the cluster.
- Significant in programming with Spark
- It supports fault recovery
- As we are using In-memory computation it enhances productivity. It also overcomes the drawbacks of MapReduce.
2. Apache Spark SQL
Spark SQL is one of the Spark Ecosystem components. If the data is too voluminous, we use Spark SQL to perform structured data analysis. Using this component we get more information on data structure and computations.
This information helps in performing extra optimization. We can also compute an output on the engine. There is no need for languages to express the computation. Also, allows running Hive queries on existing Hadoop deployment.
Spark SQL makes the process of extracting and merging various datasets easier. So that we can use the datasets for machine learning. We can access structured as well as semi-structured data in it. Also, acts as a distributed SQL query engine.
Key features of Apache Spark SQL
a. In Spark SQL, we have extensible optimizer for the core functioning in SQL. This is cost-oriented optimizer. It helps developers to improve their productivity of the system. It also increases the performance of the queries that they write.
b. Spark SQL is fully compatible with HIVE data. Hive defines as an open source data warehouse system. It is built on top of Hadoop. This helps in querying and analyzing large datasets stored in Hadoop files.
c. Along with dataFrame, SQL provides a common way to access several data sources.
d. Spark SQL gives provision to perform structured as well as semi-structured data analysis.
3. Apache Spark Streaming
This is one of the lightweight components of Spark Ecosystem. It allows developers to perform batch processing and data streaming with ease. To process data in real time, it uses a continuous stream of input data.
The great advantage is fast scheduling capacity. Also, helps to perform streaming analytics by ingesting data in mini-batches. On this mini batches of data, we allow transformation process.
a. Features of Spark Streaming
i. It allows Easy, reliable and fast processing of live data streams.
ii. In Spark streaming, integration of the streaming data with historical data is possible. We can also reuse the same code for stream and batch processing.
iii. Spark Streaming allows exactly-once message guarantees. It helps to recover lost data without having to write adding extra configurations.
iv. It supports the inclusion of Spark MLlib for machine learning pipelines into data pathways.
b. Applications of Spark Streaming
i. In applications which need real-time statistics and rapid response, we use Spark Streaming. likewise alarms, IoT sensors, diagnostics, cyber security, etc.
ii. It is very useful for Online Advertisements. Also for Campaigns, Finance, Supply Chain management, etc.
c. How does Spark Streaming Works?
Spark Streaming works in 3 phases. They are:
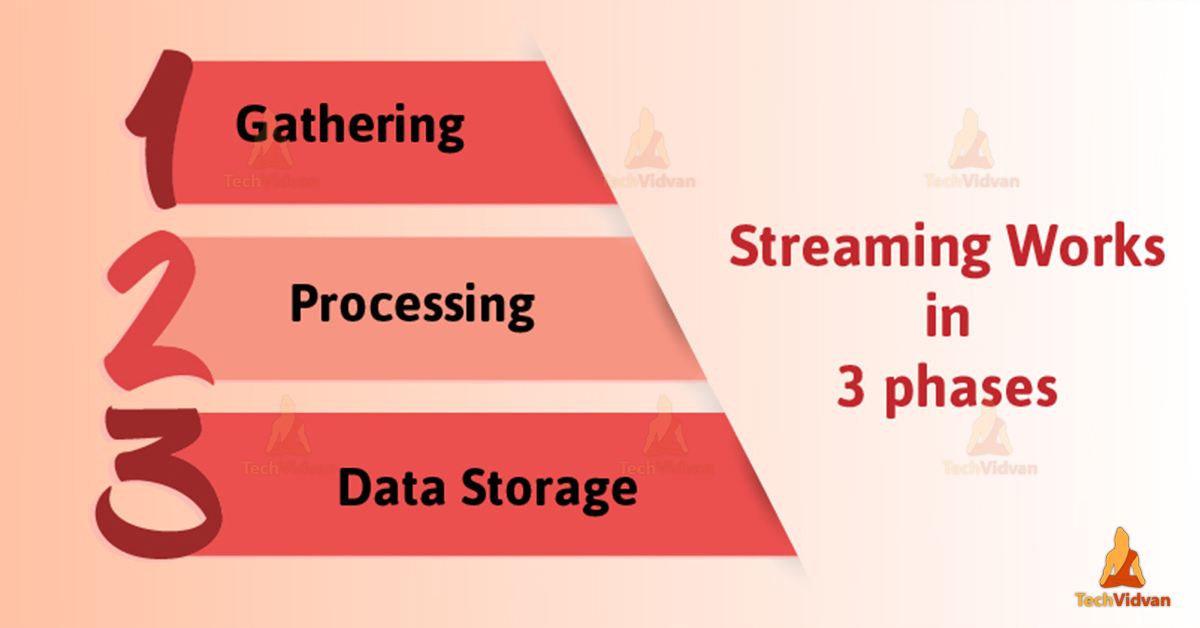
- GATHERING
The Spark Streaming categories built-in streaming sources in following categories:
1. Basic sources: It is defined as sources which are available in the Streaming Context API. For example, file socket connections and systems.
2. Advanced sources: Extra utility classes Sources like Kafka, Flume, Kinesis, etc.
- PROCESSING
By using complex algorithms with a high-level function, the gathered data is processed. For example, map, reduce and Join etc.
- DATA STORAGE
The Processed data then moved to file systems, databases, and live dashboards. Spark Streaming allows high-level abstraction. Also known as D-Stream also, discretized stream.
4. Apache Spark MLlib
MLlib is one of the most important components of Spark Ecosystem. It is a scalable machine learning library, which provides both High-quality algorithms as well as blazing Speed.
This library supports all APIs like Java, Scala, and Python as part of Spark applications. Due to this feature, we can include it in our complete workflows. It has quickly emerged as a critical piece in mining Big Data system.
MLlib is very simple to use and scalable. It is compatible with various programming languages. This can be easily integrated with other tools also. The deployment and development of scalable pipelines are becoming easier through MLlib.
MLlib library has implementations for several common machine learning algorithms. Such as–

- Clustering
- Classification
- Decomposition
- Regression
- Collaborative Filtering
5. Apache Spark GrahphX
It is a graph computation engine built on top of Spark. GraphX enables users to build, transform and reason about data at scale. It is available with a library of common algorithms already. For cross-world manipulations, GraphX is an API.
On top of Apache Spark, this easily solves this problem. Through Graphx Clustering, classification pathfinding is also possible.
Also, Graph and GraphX parallel execution are possible through it. Spark has its own Graph Computation Engine for graphs and graphical computations.
6. Apache Spark R
R is a language that enhances developer productivity for statistical analysis. To handle processing in the single machine, we can use R language along with Spark through SparkR.
Apache Spark R is a boon for users to enable R with the power of Spark. Basically, It is the key component of language R. For data processing, Data Frames are the basic data structure.
Benefits of Spark
- Data Sources API: API SparkR can read in data from a variety of sources. For example, Hive tables, JSON files etc.
- Data Frame Optimizations: It receives all the optimizations. Those are made to the engine as code generation, memory management etc.
7. Scalability to many cores and machines:
This can run on terabytes of data and clusters with thousands of machines at same time. Also, operations that execute on DataFrames, get distributed across the cluster.
Conclusion
As a result, we have noticed that this is Apache Spark Ecosystem components which are making it popular. Since Spark components are providing ease to use it. As a matter of fact, it becomes a common platform for all types of Data Processing.
Hence, Spark computing engine is being developed to handle Big Data easily as well as efficiently.