Spark RDD – Features, Limitations and Operations
Apache Spark RDD makes developer’s work more efficient, as it divides cluster into nodes to compute parallel operations on each node. Before anything else, we will go through the brief introduction of Spark RDD.
After that, we will start looking for sparkling features of Spark RDD. looking forward we will study about operations on RDD as well as limitations to Spark RDD usage.
Introduction to Apache Spark RDD
Apache Spark RDDs (Resilient Distributed Datasets) are a basic abstraction of spark which is immutable. These are logically partitioned that we can also apply parallel operations on them.
Spark RDDs give power to users to control them. Above all, users may also persist an RDD in memory. Also, can reuse RDD efficiently across the parallel operation. Apache Spark RDD is the read-only partitioned collection of records.
There are two ways to create RDDs –
1. Parallelize the present collection in our dataset
2. Referencing a dataset in the external storage system.
Prominent Features
There are following traits of Resilient distributed datasets. Those are list-up below:

1. In-Memory
It is possible to store data in spark RDD. Storing of data in spark RDD is size as well as quantity independent. We can store as much data we want in any size. In-memory computation means operate information in the main random access memory.
It requires operating across jobs, not in complicated databases. Since operating jobs in databases slow the drive.
2. Lazy Evaluations
By its name, it says that on calling some operation, execution process doesn’t start instantly. To trigger the execution, an action is a must. Since that action takes place, data inside RDD cannot get transform or available.
Through DAG, Spark maintains the record of every operation performed. DAG refers to Directed Acyclic Graph.
3. Immutable and Read-only
Since, RDDs are immutable, which means unchangeable over time. That property helps to maintain consistency when we perform further computations.
As we can not make any change in RDD once created, it can only get transformed into new RDDs. This is possible through its transformations processes.
4. Cacheable or Persistence
We can store all the data in persistent storage, memory, and disk. Memory (most preferred) and disk (less Preferred because of its slow access speed). We can also extract it directly from memory.
Hence this property of RDDs makes them useful for fast computations. Therefore, we can perform multiple operations on the same data. Also, leads reusability which also helps to compute faster.
5. Partitioned
Each dataset is logically partitioned and distributed across nodes over the cluster. They are just partitioned to enhance the processing, Not divided internally. This arrangement of partitions provides parallelism.
6. Parallel
As we discussed earlier, RDDs are logically partitioned over the cluster. While we perform any operations, it executes parallelly on entire data.
7. Fault Tolerance
While working on any node, if we lost any RDD itself recovers itself. When we apply different transformations on RDDs, it creates a logical execution plan. The logical execution plan is generally known as lineage graph.
As a consequence, we may lose RDD as if any fault arises in the machine. So by applying the same computation on that node of the lineage graph, we can recover our same dataset again. As a matter of fact, this process enhances its property of Fault Tolerance.
8. Location Stickiness
RDDs supports placement preferences. That refers information of the location of RDD. That DAG(Directed Acyclic Graph) scheduler use to place computing partitions on.
DAG helps to manage the tasks as much close to the data to operate efficiently. This placing of data also enhances the speed of computations.
9. Typed
We have several types of RDDs which are: RDD [long], RDD [int], RDD [String] .
10. Coarse-grained Operations
RDDs support coarse-grained operations. That means we can perform an operation on entire cluster once at a time.
11. No-Limitations
There is no specific number that limits the usage of RDD. We can use as much RDDs we require. It totally depends on the size of its memory or disk.
Spark RDD – Operations
As we discussed earlier the immutable nature of RDDs. We know that RDDs are unable to change with time, this immutable nature creates confusion to us that if we can not change it so how are we gonna use it?
Yes, we can not change it but we can modify RDDs as per our requirements. We can perform different operations on RDD as well as on data storage to form another RDDs from it. There are two different operations:

Spark RDD – Transformation and Action
- TRANSFORMATION
- ACTION
To modify the available datasets, we need to provide step by step instructions to the spark. Those steps must clearly explain what changes we want. That set of instructions is generally known as “Transformations”.
Transformations are operations on RDDs which results in new RDD such as Map, Filter.
Actions are operations, triggers the process by returning the result back to program. Transformation and actions work differently.
We can judge that which operations take place by its results. Transformation returns RDDs and actions return some other data types.
1. Transformation
Transformation is a process of forming new RDDs from the existing ones. Transformation is a user specific function. It is a process of changing the current dataset in the dataset we want to have.
Also, can create any number of RDDs we want. We do not change the current RDD as we know they are immutable. So we can produce more RDDs out of it by applying several computations. Some common transformations supported by Spark are:
For example, Map(func), Filter(func), Mappartitions (func), Flatmap (func) etc.
All transformed RDDs are lazy in nature. As we are already familiar with the term “Lazy Evaluations”. That means it does not produce their results instantly. However, we always require an action to complete the computation.
To trigger the execution, an action is a must. Up to that action data inside RDD is not transformed or available.
After transformation, you incrementally build the lineage. That lineage is which formed by all the parent RDDs of final RDDs. As soon as the execution process ends, resultant RDDs will be completely different from their parent RDDs.
They can be smaller (e.g. filter, count, distinct, sample), bigger (e.g. flatMap, union, Cartesian) or the same size (e.g. map).
Transformation can categorize further as: Narrow Transformations, Wide Transformations.
a. Narrow Transformations
Narrow transformations are the result of a map, filter. As such that is from the data from a single partition only. That signifies it is self-sustained.
An output RDD also has partitions with records. In the parent RDD, that output originates from a single partition. Additionally, to calculate the result Only a limited subset of partitions is used.
In Apache spark narrow transformations groups as a stage. That process is mainly known as pipelining. Pipelining is an implementation mechanism.
In this mechanism, multiple instructions get overlapped in the execution process. The computer pipeline automatically gets divided into stages.
b. Wide Transformations
Wide transformations are the result of groupByKey (func) and reduceByKey (func). As data may reside in many partitions of the parent RDD. These are used to compute the records by data in the single partition.
Wide transformations may also know as shuffle transformations. Even they may or may not depend on a shuffle. Shuffling means redistributing data across partitions. In other words, shuffling is the process of data transfer between stages.
2. Actions
An action is an operation, triggers execution of computations and RDD transformations. Also, returns the result back to the storage or its program. Transformation returns new RDDs and actions returns some other data types. Actions give non-RDD values to the RDD operations.
It forces the evaluation of the transformation process need for the RDD they may call on. Since they actually need to produce output. An action instructs Spark to compute a result from a series of transformations.
Simply put, an action evaluates the RDD lineage graph. RDD lineage (RDD operator graph or RDD dependency graph) is a graph of all the parent RDDs of an RDD. This graph is mainly made as a result of applying transformations to the RDD.
That creates a logical execution plan. Logical execution plan starts with the earliest RDDs and also ends with the RDD. Ultimately, that plan produces the result of the action which is only called to execute.
Actions are one of two ways to send data from executors to the driver. Executors are agents that are responsible for executing different tasks. While a driver coordinates execution of tasks.
Accordingly, action eliminates the laziness of RDDs and convert that laziness into motion.
Limitations
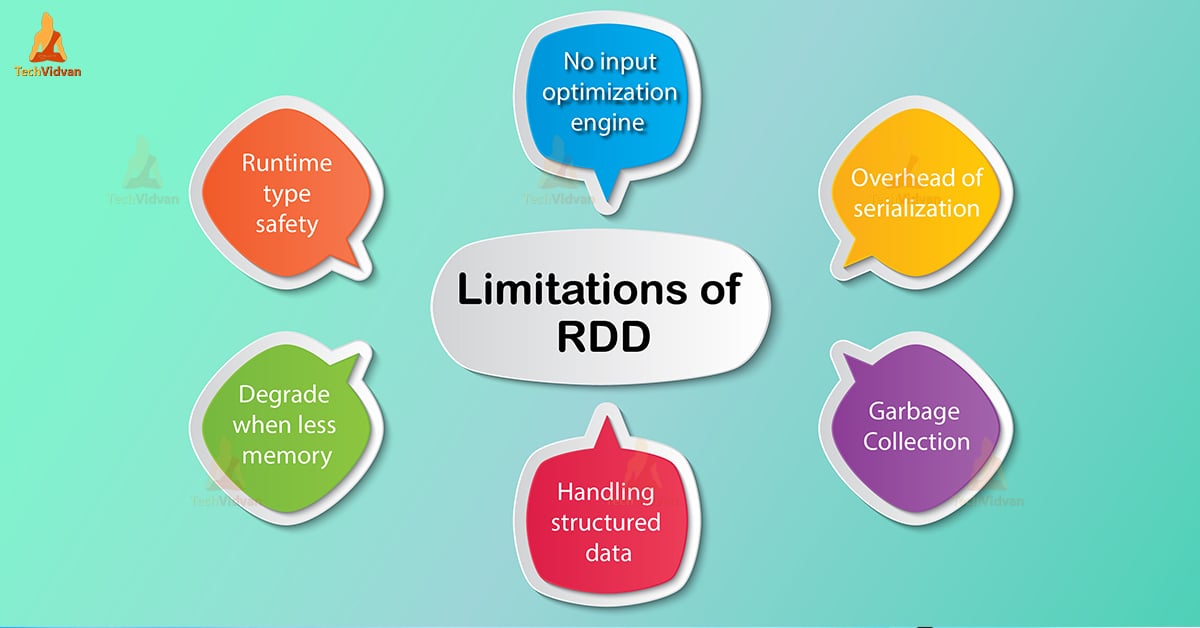
1. No Input Optimization Engine
There are several spark advance optimizers like catalyst optimizer and tungsten execution engine. RDDs are not able to use these optimizers. There is no way in RDD for automatic optimization. To optimize, we can optimize each RDD manually.
2. Not Enough Memory
This is a sort of storage issue when we are unable to store RDD due to its lack of memory. The RDD degrades itself when there is not enough space to store spark RDD in-memory or on disk.
All the partitions that are already overflowing from RAM can be later on stored in the disk. Even so, that will provide the same level of performance. To overcome this issue, we need to increase the size of RAM or Disk.
3. Runtime type safety
There is no run-time type safety in spark RDD spark RDD. Runtime type safety means it does not allow us to check error at the same time you are compiling the Program.
4. Handling Structured Data
Spark RDD are user specific, they don’t infer any schema of the ingested data like other APIs. Such as data frames as well as datasets. Moreover, when we need data immediately, a method to get and import data is data ingestion process.
Conclusion
As a result, by analysis of above operations as well as features, RDD in Apache Spark increases the efficiency of our work. Also, make itself more useful for faster computations. Hence, these features enhance the performance of the system.
But there were some limitations of RDD. For example, no inbuilt optimization, storage and performance limitation etc.
Because of above-stated limitations, to make spark more versatile dataframes and datasets evolved.