A Quick Guide On Apache Spark Streaming Checkpoint
This document aims at a Spark Streaming Checkpoint, we will start with what is a streaming checkpoint, how streaming checkpoint helps to achieve fault tolerance. There are two types of spark checkpoint i.e. reliable checkpointing, local checkpointing.
In this spark streaming tutorial, we will learn both the types in detail. Also, to understand more about a comparison of checkpointing & persist() in Spark.
Spark Streaming Checkpoint in Apache Spark
What is Spark Streaming Checkpoint
A process of writing received records at checkpoint intervals to HDFS is checkpointing. It is a requirement that streaming application must operate 24/7. Hence, must be resilient to failures unrelated to the application logic such as system failures, JVM crashes, etc.
Checkpointing creates fault-tolerant stream processing pipelines. So, input dstreams can restore before-failure streaming state and continue stream processing.
In Streaming, DStreams can checkpoint input data at specified time intervals. For its possibility, needs to checkpoint enough information to fault-tolerant storage system such that, it can recover from failures. Data checkpoint are of two types.
1. Metadata checkpointing
We use it to recover from the failure of the node running the driver of the streaming application. Metadata includes:
-
- Configuration – We use to create the streaming application.
- DStream operations – Defines the streaming application.
- Incomplete batches -Jobs are in the queue but have not completed yet.
2. Data checkpointing
All the generated RDDs are saving to reliable storage. For some stateful transformations, it is necessary to combine the data across multiple batches. Since generated RDDs in some transformations depend on RDDs of previous batches.
It causes the length of the dependency chain to keep increasing with time, to reduce increases in recovery time. Checkpoint intermediate RDDs of stateful transformation, it happens at reliable storage to cut off the dependency chains.
In other words, for recovery from driver failures, metadata checkpointing is primarily needed, data or RDD checkpointing is also necessary. Even for basic functioning, if we use stateful transformations.
When to enable Checkpointing in Spark Streaming
With any of the following requirements, checkpointing in Spark streaming is a must for applications:
1. While we use stateful transformations
The checkpoint directory must be provided to allow for periodic RDD checkpointing. Only while we use following stateful transformations, such as updateStateByKey or reduceByKeyAndWindow (with inverse function) in the application.
2. Recovering from failures of the driver running the application
To recover with progress information, we use metadata checkpoints.
Note: Apart from above mentioned, simple streaming applications can run, without enabling checkpointing. In that case, the recovery from driver failures will also be partial.
Also, remember some received but unprocessed data may get lost. It is often acceptable and many run Spark Streaming applications in this way.
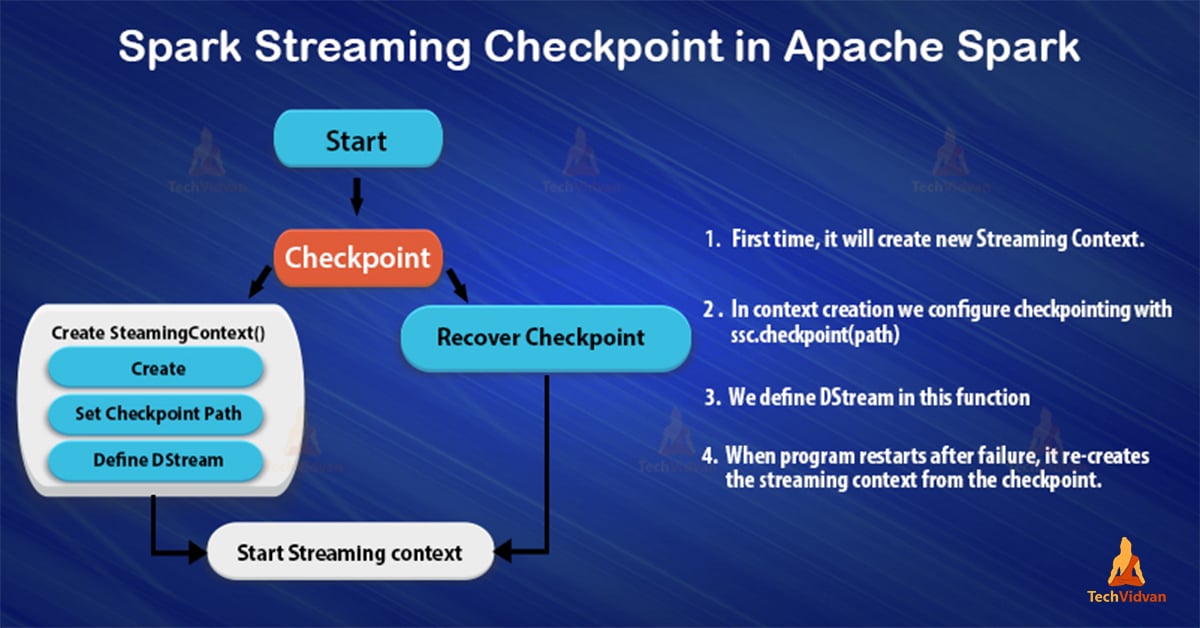
Marking StreamingContext as Checkpointed
While we persist checkpoint data we use “StreamingContext.checkpoint” method. We use this method to set up an HDFS-compatible checkpoint directory.
For Example
ssc.checkpoint("_checkpoint")
Types of Checkpointing in Spark Streaming
Apache Spark checkpointing are two categories:
1. Reliable Checkpointing
The checkpointing in which the actual RDD exist in the reliable distributed file system, e.g. HDFS. We need to call following method to set the checkpoint directory
SparkContext.setCheckpointDir(directory: String)
While running over cluster, the directory must be an HDFS path. Since the driver tries to recover the checkpointed RDD from a local file. Even so, checkpoint files are actually on the executor’s machines.
2. Local Checkpointing
We truncate the RDD lineage graph in spark, in Streaming or GraphX. In local checkpointing, we persist RDD to local storage in the executor
Difference between Spark Checkpointing and Persist
Spark checkpoint vs persist is different in many ways. Let’s discuss them one by one-
Persist
- While we persist RDD with DISK_ONLY storage, RDD gets stored in whereafter use of RDD will not reach, that points to recomputing the lineage.
- Spark remembers the lineage of the RDD, even though it doesn’t call it, just after Persist() called.
- As soon as the job run is complete, it clears the cache and also destroys all the files.
Checkpointing
- Through checkpointing, RDDs get stored in HDFS. Also, deletes the lineage which created it.
- Unlike the cache, the checkpoint file is not deleted upon completing the job run.
- At the time of checkpointing an RDD, it results in double computation.
Spark Streaming Checkpoint – Conclusion
Spark Streaming Checkpoint tutorial, said that by using a checkpointing method in spark streaming one can achieve fault tolerance. Whenever it needs, it provides fault tolerance to the streaming data.
Moreover, when the read operation is complete the files are not removed, as in persist method. Hence, the RDD in Apache Spark needs to be checkpointed if the computation takes a long time or the computing chain is too long.
Also, if it depends on too many RDDs. It also helps to avoid unbounded increases in recovery time. Ultimately, checkpointing improves the performance of the system.