Spark Streaming Execution Flow and Streaming Model
Spark Streaming enables fast, scalable and fault-tolerant processing of live data streams. In this article, we will learn the whole concept of spark streaming execution flow. For better understanding, we will start with basics of Apache Spark Streaming. Going forward, we will learn Streaming model in detail.
Moreover, we will learn the internal working of stream execution flow in spark. To know complete information, we will also know little about spark streaming sources.
What is Spark Streaming Execution Flow
To need of stream processing, spark streaming was launched as spark’s response. It enables fast, scalable and fault-tolerant processing of live data streams. Streaming as a part of the spark environment, it is one of its major advantages over its competitors.
Spark Streaming makes integration possible of stream processing and machine learning. Here, we can ingest data from many sources, such as Kafka, Flume, Twitter, HDFS or S3.
Also, can be processed using high-level algorithms. Ultimately, processed data can be pushed into the various filesystems or live dashboards.
For batch and streaming, it offers both execution and unified programming. Streaming leverages several advantages over other traditional streaming systems. Basically, there are 4 aspects of it:
1. While it comes to failures and stragglers, it recovers very fast.
2. It offers resource usage and better load balancing.
3. We can combine static datasets with streaming data as well as interactive queries.
4. It is possible to integrate it with advanced processing libraries, for example, SQL, machine learning, graph processing.
Spark Streaming Execution Flow – Streaming Model
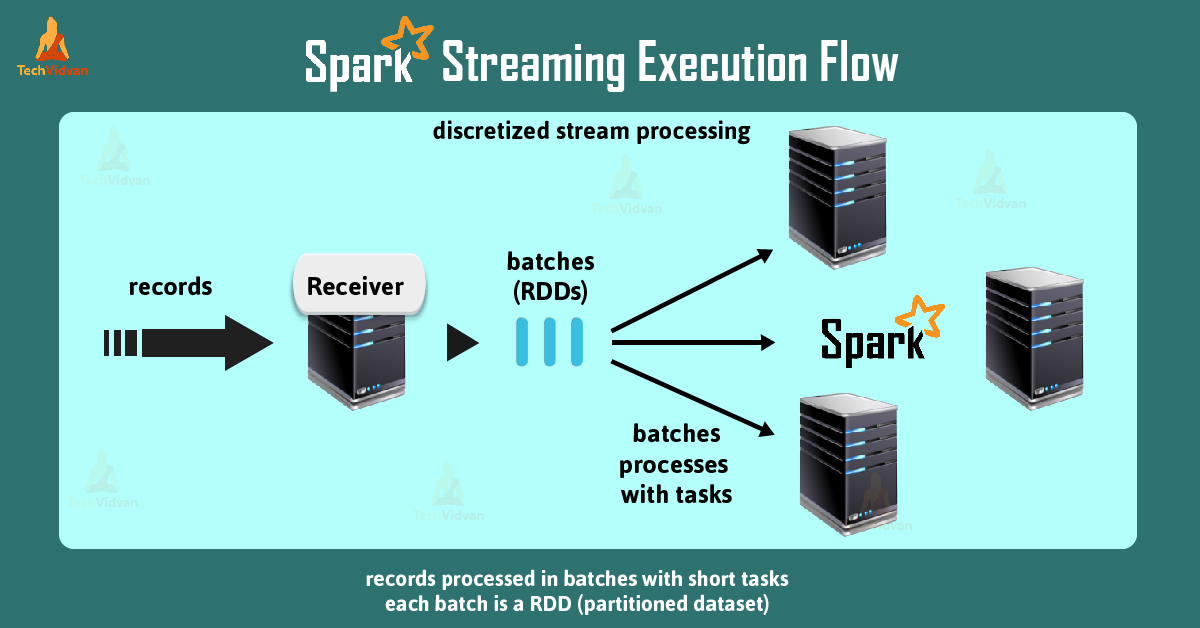
Basically, Streaming discretize the data into tiny, micro-batches, despite processing the data one record at a time. We can also say, in this model receivers accept data in parallel. Furthermore, it buffers it into the memory of spark’s worker’s nodes.
After that spark engine runs short tasks to process the batches. Also, output the results to other systems.
Note: The Streaming model is not similar to traditional continuous operator model. In traditional models, computation is statically allocated to a node. Moreover, it assigns tasks to the workers based on the locality of the data & resources. Hence, It enables both better load balancing and faster fault recovery.
Moreover, each batch of data is a Resilient Distributed Dataset (RDD). RDD is the basic abstraction of a fault-tolerant dataset in spark. It allows processing streaming data by using any spark code or library.
Working of Spark Streaming
At the starting of the process, it receives live input data streams. Afterwards, it divides the data into batches. Then those batches processed through the engine helps to generate final results in batches.
Well, there is a high-level abstraction of spark streaming, that is DStream or discretized stream. It represents a continuous stream of data, that series then processed using Spark APIs Afterwards, results are returned in batches.
We can create Dstream from input data streams and following sources, for example, Kafka, Flume, and Kinesis. There is one more method, by applying high-level operations on other DStreams, we can create it.
Basically, a DStream is just a sequence of RDDs. In addition, it is possible to write streaming programs in Scala, Java or Python. A state based on data coming in a stream called stateful computations. it offers window operations.
Spark Streaming Sources
Input DStream is basically corresponding to a receiver object, that receives the data from a source and stores it in spark’s memory for processing.
Basically, Built-in streaming sources are of two types:
- Basic sources
Basic sources are directly available sources in the StreamingContext API, for example, file systems, and socket connections.
- Advanced sources
Advanced sources are available through extra utility classes, for example, Kafka, Flume, Kinesis, & many more. Also, requires linking against extra dependencies.
While we come to reliability factor, there are two types of receivers, such as:
- Reliable Receiver
This receiver sends the acknowledgment to source exactly when they received the data. In other words, which stores data with replication is a reliable receiver.
- Unreliable Receiver
These receivers do not send the acknowledgment to a source. While we do not need any complexity of acknowledgment we can use these sources.
Conclusion
Hence, we have covered the complete information on spark streaming job flow. Hope this article, helps you to understand this topic better. Yet, if you feel any queries regarding, feel free to ask in the comment section.