Spark Streaming Fault Tolerance- How it is achieved
The recovery of failures of machines is already inbuilt in Apache spark streaming. This feature is what we call spark streaming fault tolerance property. In this blog, we will learn the whole concept of spark streaming fault tolerance property. At first, we will understand what is fault tolerance in brief.
Afterward, we will learn what is fault tolerance in spark with receiver-based sources. Moreover, we will learn preliminary support for write-ahead logs to streaming. Further, we will also focus on the entire working of write-ahead logs in spark streaming.
Fault Tolerance in Spark
Fault Tolerance means RDD have the capability of handling if, any loss occurs. It can recover the failure itself. Fault refers to failure. If any bug or loss found, spark RDD has the capability to recover the loss.
We need a redundant element to redeem the lost data. Redundant data plays important role in the self-recovery process. Ultimately, we can recover lost data by redundant data.
Spark Streaming Fault Tolerance with receiver based sources
Fault tolerance depends on two points. The failure scenario and the type of receiver, for input sources on the basis of receivers. Basically, receivers are of two types:
- Reliable receiver
As soon as the received data has been replicated, reliable sources acknowledge it. Although, as receiver fails, the source will not acknowledge it for the buffered data. Hence, as the receiver restarts next time, data will be automatically, send to the source again. Thus, there will be no data loss due to failure.
- Unreliable Receiver
Unreliable receivers do not send any acknowledgment. Hence, if any failure occurs in the worker or driver, we can easily lose the data.
In other words, as the receiver is reliable there will be no data loss, even if the worker node fails. While there is a definite data loss condition, in case of an unreliable receiver.
Spark Streaming Fault Tolerance – Write – ahead logs
To ensure the durability of any data operations in database and file systems we use write-ahead logs, this is what we call journaling in streaming. Further, there are following steps of the process at first, an operation is written down into a durable log.
Afterwards, it applies the operation to the data. Although, if in the middle of applying the operation, the system fails. We can easily recover by again applying the operations it had intended to do. Also, possible to recover it through reading the log.
To receive data, sources like Kafka and Flume use receivers. In the executors, they run as long-running tasks. Also, responsible for receiving the data from the source. It acknowledges the received data if source supports it.
It runs tasks on the executors to process the tasks. Also, store the received data in the memory of the executors and the driver.
As soon as write ahead logs are enabled, received data is saved to log files in a fault-tolerant file system. Hence, across any failure in spark streaming, it allows the received data to be durable.
There are two conditions, ensures zero data loss, such as either recover all the data logs or all data again sent by the sources.
Implementation of Fault Tolerance in Spark Streaming
Let’s understand the general spark streaming architecture.
As streaming application starts, the starting point of functionality uses the sparkcontext, sparkcontext launch receiver as long-running tasks. Furthermore, these receivers receive streaming data and save it into spark’s memory for processing.
Moreover, below diagram shows the lifecycle of this data received through users.

Implementation of Spark Streaming Fault Tolerance
– Receiving data (yellow arrows)
A receiver turns the stream of data into blocks. Afterwards, all that data stores in the memory of the executor. In Addition, data is also written to a write ahead log in fault-tolerant file systems, if enabled.
– Notifying driver (orange arrows)
It says sending of metadata of the received blocks to the streamingcontext in the driver, whereas metadata includes:
- Block’s reference ids for locating their data in the executor memory.
- Block data are offset information in the logs (if enabled).
– Processing the data (blue arrow)
The streamingcontext uses the block information to generate RDDs and jobs on them. To process the in-memory blocks, sparkcontext also executes these jobs by running tasks.
– Checkpointing the computation (red arrow)
In the same system, it checkpoints the computation to another set of files, this process helps to recover.
Implementation of Spark Streaming Fault Tolerance
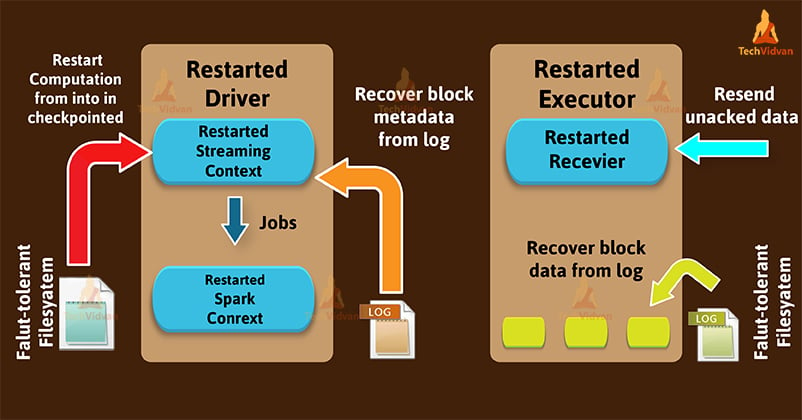
Now, we will see changes when a failed driver is restart, in the next diagram.
– Recover computation (red arrow)
To restart the driver and all the receivers, it uses checkpointed information. Also uses the checkpointed information to reconstruct the contexts.
– Recover block metadata (orange arrow)
The recovery of metadata of all the blocks which is necessary to continue the processing.
– Re-generate incomplete jobs (blue arrow)
The processing which is incomplete due to the failure of the batches. For that, it regenerates corresponding jobs & RDDs by using the recovered block metadata.
– Read the block saved in the logs (yellow arrow)
When it executes those jobs block data is read directly from the write-ahead logs. It recovers all the important data that were reliably saved to the logs.
– Resend unacknowledged data (cyan arrow)
At the time of failure, buffered data that was not saved to the log will resent by the source. Since receiver does not acknowledge it.
Conclusion
As a result, Spark Streaming fault tolerance property ensures that there will be no loss of input data will occur due to driver failures. Thus, it is only possible with the help of write-ahead logs and reliable receivers.
Moreover, write ahead logs in streaming improves recovery mechanism. Also, gives stronger guarantees of zero data loss for more data sources. Hence, fault tolerance in spark streaming property also enhances the efficiency of the system.