Spark Tutorial – Apache Spark Introduction for Beginners
In this Spark tutorial, we will focus on what is Apache Spark, Spark terminologies, Spark ecosystem components as well as RDD. Now-a-days, whenever we talk about Big Data, only one word strike us – the next-gen Big Data tool – “Apache Spark”.
We will discuss why you must learn Apache Spark, how Spark handles big data efficiently, why industry is focusing on Spark. We will also cover the Spark history to understand its evolution.
In closing, we will also study Apache Spark architecture and deployment mode. This spark blog is turned out as Apache spark quickstart tutorial for beginners.
What is Apache Spark?
Apache Spark is powerful cluster computing engine. It is purposely designed for fast computation in Big Data world. Spark is primarily based on Hadoop, supports earlier model to work efficiently. It offers several new computations.
Such as interactive queries as well as stream processing. The most Sparkling feature of Apache Spark is it offers in-memory cluster computing. In-memory cluster computing enhances the processing speed of an application.
There is a huge range of workloads in Apache Spark. For example streaming and batch applications, iterative algorithms, interactive queries. In addition, Spark also decreases the management burden of maintaining separate tools.
Spark supports high-level APIs such a Java, Scala, Python and R. It is basically built upon Scala language. Due to its feature of high speed to handle large scale data it becomes visible. The superiority about spark is it works 100 x faster than Hadoop.
It is also 10 x faster than accessing data from disk. Spark is highly compatible with Hadoop. As Apache Spark does not have its own file management system. So Apche spark can simply integrated with Hadoop and can process existing Hadoop HDFS data.
Evolution of Apache Spark
Apache Spark is one of Hadoop’s subproject. This was first developed in AMPLab by Matei Zaharia in the year 2009 in UC Berkeley’s. Spark became Open Sourced under a BSD license in the year 2010.
Afterwards, Apache software foundation adopted Spark in 2013. Now, It is announced as a top-level Apache project from February 2014.
Why Apache Spark is remarkable now-a-days?
Spark always been a Step ahead from Hadoop in Several features. Those features itself defines why it remains in high demand always. One of the possible reason for its popularity is fast Speed.
As we discussed already, Apache Spark offers about 100 times faster processing than Hadoop. It process very large amount of data in such short span of time. Spark uses fewer resources as compared to Hadoop, which makes it cost-effective.
One of the Prime aspect where Spark has the upper hand in terms of compatibility. It is highly compatible with a resource manager. It is generally known to run with Hadoop, just as MapReduce does.
Although, it can also work with other resource managers such as YARN or Mesos.
In addition, a major reason is that Spark supports Real-time processing even in batch mode. Spark is fulfilling that fundamental demand of Industry.
There is also a need for an engine that can perform in-memory processing. As a matter of fact, it offers in-memory computation which also increases its demand.
Apache Spark Ecosystem Components
As we know, Spark offers faster computation and easy development. But it is not possible without following components of Spark. To learn all the components of Apache Spark in detail, let’s study all one by one.
Those are:
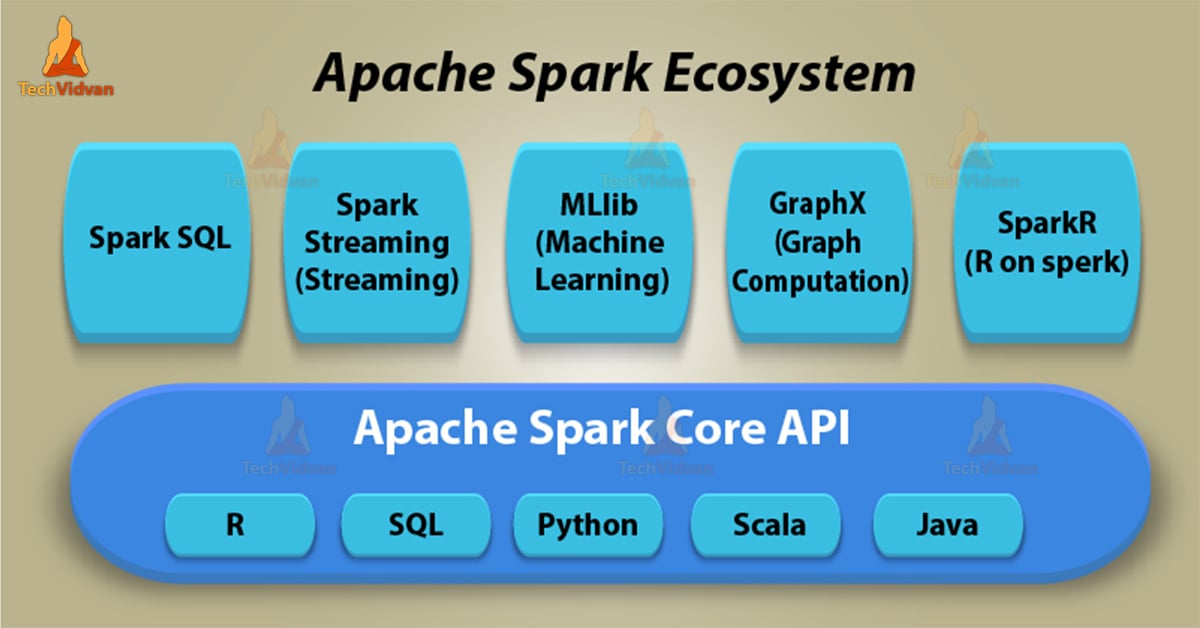
1. Apache Spark Core
Apache Spark Core is a platform on which all functionality of Spark is basically built upon. It is the underlying general execution engine for spark. Spark core provides In-Memory computation. It also references datasets in external storage systems.
2. Apache Spark SQL
On top of Spark Core, It is a component that introduces a new data abstraction. That abstraction is called SchemaRDD. It supports for both structured as well as semi-structured data.
3. Apache Spark Streaming
While we talk about Real-time Processing in Spark it is possible because of Spark Streaming. It holds the capability to perform streaming analytics. SQL divides data in mini-batches and perform Micro batch processing.
It Supports DStream. Dstream is fundamentally a series of RDDs, to process the real-time data
4. MLlib (Machine Learning Library)
MLlib is Spark’s machine learning framework. It consists of common learning algorithms as well as utilities. This library also includes classification, regression, clustering & many more.
It is also capable of performing in-memory data processing. That enhances the performance of iterative algorithm drastically.
5. GraphX
On top of Spark, GraphX is a distributed graph-processing framework. It enables to process graph data at scale.
6. SparkR
SparkR is somehow a combination of Spark and R. Major key Aspect behind SparkR is we can explore different techniques. It enhances functionality by merging the use of R with the scalability of Spark.
RDD: Core Abstraction of Apache Spark
RDD refers to Resilient Distributed Dataset. It is the fundamental unit of data in Apache Spark. RDDs are distributed a collection of elements across cluster nodes. One of the Important parameters is RDD supports parallel operations.
Spark RDDs are immutable in nature. We can not make any changes though it can generate by transforming existing RDD.
we can create RDD in Spark by several ways. Those are:
1. Parallelized collections
2.External datasets
3.Existing RDDs
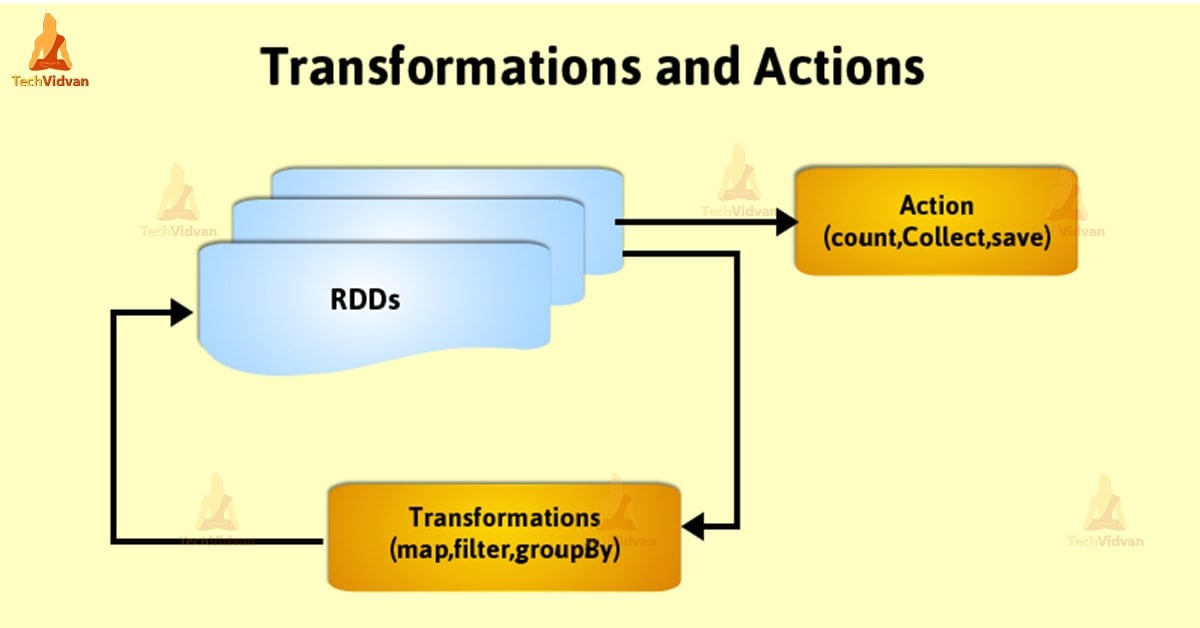
RDD offers two types of operations:
1. Transformation
2. Action
Transformations:
As we can not make any changes in RDD but we can transform one. This process returns a new RDD.
Few of the Transformation functions are a map, filter, flatMap etc.
Actions:
After Action takes place it returns a new value to driver program. It may write it to external datastore also.
Few of the Action operations are reduce, collect etc.
Conclusion
As a result, we have seen how spark dominated complete Big Data world. It is a powerful framework which enhances Big Data to a new level in the industry. Spark provides a collection of technologies, which increases the efficiency of the system.
Also, a powerful engine which mainly provides ease of use. Hence, Spark became very beneficial to developers of this ere with phenomenal speed.