SparkContext In Apache Spark: Entry Point to Spark Core
This tutorial gives information on the main entry point to spark core i.e. Apache Spark SparkContext. Apache Spark is a powerful cluster computing engine, therefore, it is designed for fast computation of big data.
Here, we will learn what is Apache Spark SparkContext. Furthermore, we will discuss the process to create SparkContext Class in Spark and the facts that how to stop SparkContext in Spark.
To get this concept deeply, we will also study various functions of SparkContext in Spark.
Introduction
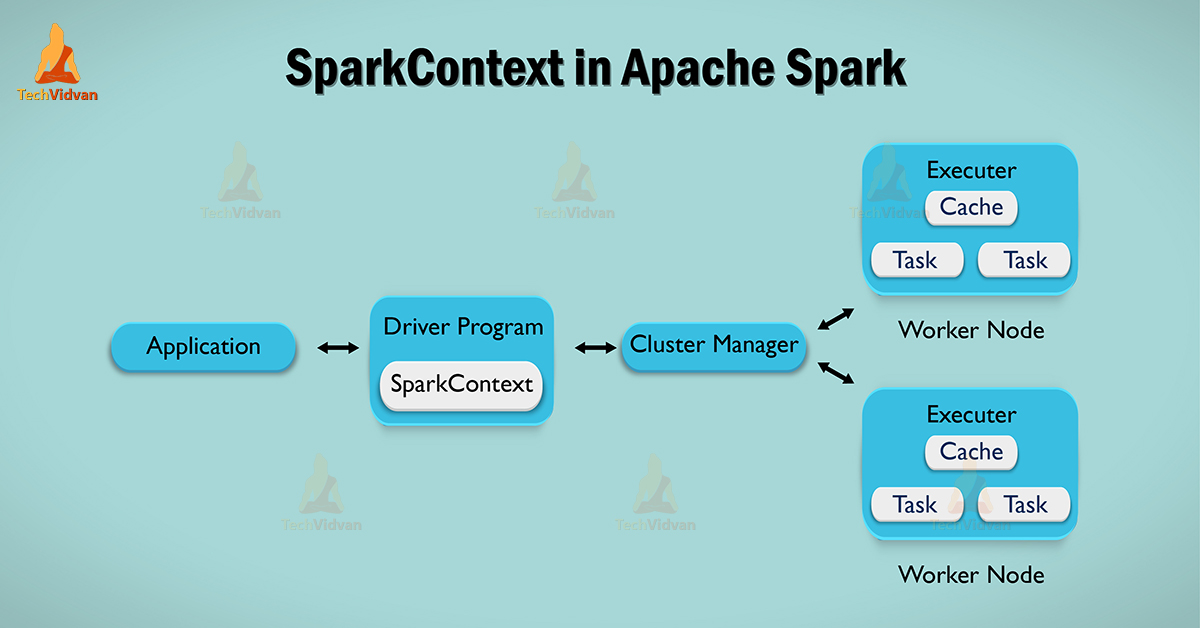
We can say Apache Spark SparkContext is a heart of spark application. It is the Main entry point to Spark Functionality. Generating, SparkContext is a most important task for Spark Driver Application and set up internal services and also constructs a connection to Spark execution environment.
This is essentially a client of Spark’s execution environment, that acts as a master of Spark Application.
Moreover, once we create Apache Spark SparkContext we can use it in following ways. We can make RDDs (Resilient distributed datasets) from it, which is also used to obtain broadcast variables.
Broadcast variables mean, which allow the programmer to cache a read-only variable and allows reading on each machine than shipping copy of it with jobs. Furthermore, we can create accumulator using SparkContext. It allows to access spark services and helps to run jobs until we stop SparkContext by own.
In addition, SparkContext allows accessing spark cluster manager, spark Standalone, Yarn, and Apache Mesos any one of them can be selected as a cluster manager.
If we use YARN (head node), and node manager (worker node), it may work to allocate containers for executors. As resources are available then, it will allocate memory and cores.
It distributes according to the configuration. If we use sparks manager (head node), and spark slave (worker node) will work to allocate resources.
SparkContext – Ways to create Class
The first step to create Apache Spark SparkContext. It is the main entry point to spark functionality, is to make sparkconf. We have some configuration parameters. Those parameters we pass to sparkcontext through spark driver application and these parameters explain the properties of the application.
We configure the parameters according to functionalities we need. Spark use some of them to allocate resources on a cluster by executors. Resources like cluster, like the number, memory size, and cores.
In addition, it helps us to access spark cluster in a better way. Due to sparkcontext objects, we can use functions such as textfile, sequence file and parallelize. There are following context in which it can run are local, yarn-client, Mesos URL and Spark URL.
As we discussed earlier, once we create sparkcontext. We can use it to create RDDs, broadcast variable, accumulator, and run jobs. Until we stop sparkcontext we can carry most of all these things.
SparkContext – How to stop
There is a condition that only a single sparkcontext can be active for single JVM. Before creating a new sparkcontext we need to stop () the active one.
To Stop()
stop(): Unit
While we apply this command we get a message written below:
INFO SparkContext: Successfully stopped SparkContext
This message signifies that running sparkcontext stopped successfully.
SparkContext – Various tasks
SparkContext offers following functions. Those are list-up below:

1. We have following functions to get the current status of Spark Application
– SpkEnv
SparkENV is a runtime environment with spark’s public services. For a running spark application, it holds all the running services objects.
It may also include serializer, block manager, map output tracker, Akka actor system and also interacts to establish a distributed computing platform for spark application.
– To access SparkEnv
SparkEnv.get
– SparkConf
In spark, each application is configured separately with spark properties. Properties also manage all the applications. We can also set these properties manually on sparkconf.
We can configure following common properties, such as master URL, application name, arbitrary key-value pair and configured through set method.
– Deployment environment (as master URL)
We can categorize deployment environment in two ways, such as local and clustered. We can also run spark in local mode. This is non-distributed single – JVM deployment mode. All the execution components are present in same single JVM. It includes driver, executor, local scheduler backend, and master.
Hence, a local mode is the only mode where drivers are useful for execution. This mode is very appropriate for testing, debugging.
Also, helps in demonstration purposes. Due to there is no earlier setup require to launch spark applications. Local mode is also called as spark in-process or a local version of Spark.
2 Spark in Cluster mode
Spark can run in cluster mode also. The following cluster managers (task schedulers or resource managers) are currently supported:
1.Spark’s own built-in standalone cluster manager
2.Hadoop YARN
3.Apache Mesos
– Application name
This function gives the value to the mandatory spark.app.name setting.
– Unique identifier of the execution attempt
This application provides the unique identifier of a spark application.
– Deploy Mode
This mode returns the current value of spark.submit.deployMode setting or client if not set.
– Default level of parallelism
When we create Spark RDDs without specifying the number by a user. That specifies the number of partitions in Spark RDDs.
– SparkUser
It is the user that initiated the sparkcontext instance.
3. We have following functions to set the configuration
– Master URL
This method helps to returns back the current value of spark.master. That is deployment environment in use.
– Local properties – Creating Logical Job Groups
To form logical groups of jobs by means of properties, we use local properties. These create job launched from the different thread. That belongs to the single logic group. We can also set local properties. That may affect spark Jobs submitted from the thread, as spark fair scheduler pool.
We can also use our own custom properties. Properties can propagate through to worker tasks. We can access thereby TaskContext.getLocalProperty.
– Default Logging level
In a spark application, default logging level helps to set the root login level.
4. We have following functions to access various services
– Task Scheduler
It helps to manage (i.e. reads or writes) task scheduler internal property.
– LiveListenerBus
We use livelistnerbus to declare application-wide events in a spark application. It makes a path to pass listener events to register spark listeners.
– Block Manager
It is a key-value store for blocks of data in spark. Also, acts as a local cache. It runs on every “node” in a spark, i.e. the driver and executors.
– Scheduler Backend
To support various cluster managers, it works as a pluggable interface. The first one is Apache Mesos, second is Hadoop YARN and the third one is Spark Standalone.
– Shuffle Manager
It is the pluggable mechanism for shuffle systems. On the driver and executors, it tracks shuffle dependencies for ShuffleMapStage.
5. Provides a function To Cancel a job
It simply means to cancel a Spark job (with an optional reason) by requesting DAG Scheduler.
6. Provides a function Closure Cleaning
Whenever we call an action, Spark cleans up the closure. That is the body of the action before it is serialized. This method is closure cleaning method. In addition, it not only cleans the closure but also does it transitively. That means referenced closures are cleaned transitively.
7. Provides a function To cancel a stage
It simply means to cancel a Spark stage (with an optional reason). Actually, by requesting DAGScheduler.
8. Provides a function To Register Spark listener
We can register a custom Spark Listener Interface by using add Spark Listener method.
9. It allows Programmable Dynamic allocation
SparkContext offers the several methods as API developer for dynamic allocation of executors:
- Request Executors
- Kill Executors
- Request Total Executors
- GetExecutorIds
10. It provides a function To access persistent RDD
This provides the collection of spark RDDs. Those have considered themselves as persistent by using the cache.
11. It provides a function to un-persist RDDs
Unpersist removes the RDD from the master’s block manager internal persistent RDD pamapping.
Conclusion
Hence, we have discussed, an introduction of SparkContext, a creation of SparkContext, how to stop it and it’s various tasks. However, provides the various functions in sparks, such as getting the current status, set the configuration, cancel a job, cancel a stage and much more.
As a result, we get SparkContext is the main entry point to spark core and it acts as a heart of a spark application.